XProvence:検索拡張生成のためのゼロコストな多言語コンテキストプルーニング
XProvenceは、検索拡張生成(RAG)の推論速度を向上させるため、リランカーに「ゼロコスト」でコンテキスト削減機能を統合した多言語対応モデルであり、BGE-M3を基盤として100以上の言語をサポートします。
TL;DR(結論)
XProvenceは、検索拡張生成(RAG)の推論速度を向上させるため、リランカーに「ゼロコスト」でコンテキスト削減機能を統合した多言語対応モデルであり、BGE-M3を基盤として100以上の言語をサポートします。 英語データのみを用いた学習でも強力なクロスリンガル転移を発揮し、回答精度を維持したままコンテキストを40%から60%圧縮することで、大規模言語モデル(LLM)の計算負荷と推論コストを大幅に削減することに成功しました。 多言語質問回答ベンチマークにおいて、既存のDSLRなどの強力な手法を上回る性能を実証し、学習に含まれていない未知の言語や専門ドメインに対しても高い汎用性と頑健性を持つことが確認された実用的なフレームワークです。
なぜこの問題か
検索拡張生成(RAG)は、大規模言語モデル(LLM)が持つ知識の限界を補い、特定のドメインや最新の外部知識に基づいて回答を生成するための強力な手法として確立されています。しかし、その運用には膨大な計算コストが伴うという深刻な課題があります。検索によって取得された大量の文書をそのままLLMの入力コンテキストに含めると、入力長が著しく増大します。LLMの推論時間は入力の長さに対して二次関数的に増加する性質があるため、これは推論の遅延を直接的に引き起こし、ユーザー体験を損なう原因となります。また、計算リソースの消費量が増えることは、商用利用におけるデプロイコストの上昇を招くだけでなく、データセンターの電力消費に伴うカーボンフットプリントの拡大という環境負荷の問題も無視できません。 このような背景から、LLMに情報を渡す前に、検索された文書の中からクエリに無関係な部分を特定して取り除く「コンテキスト・プルーニング(削減)」という技術が重要な研究焦点となっています。…
核心:何を提案したのか
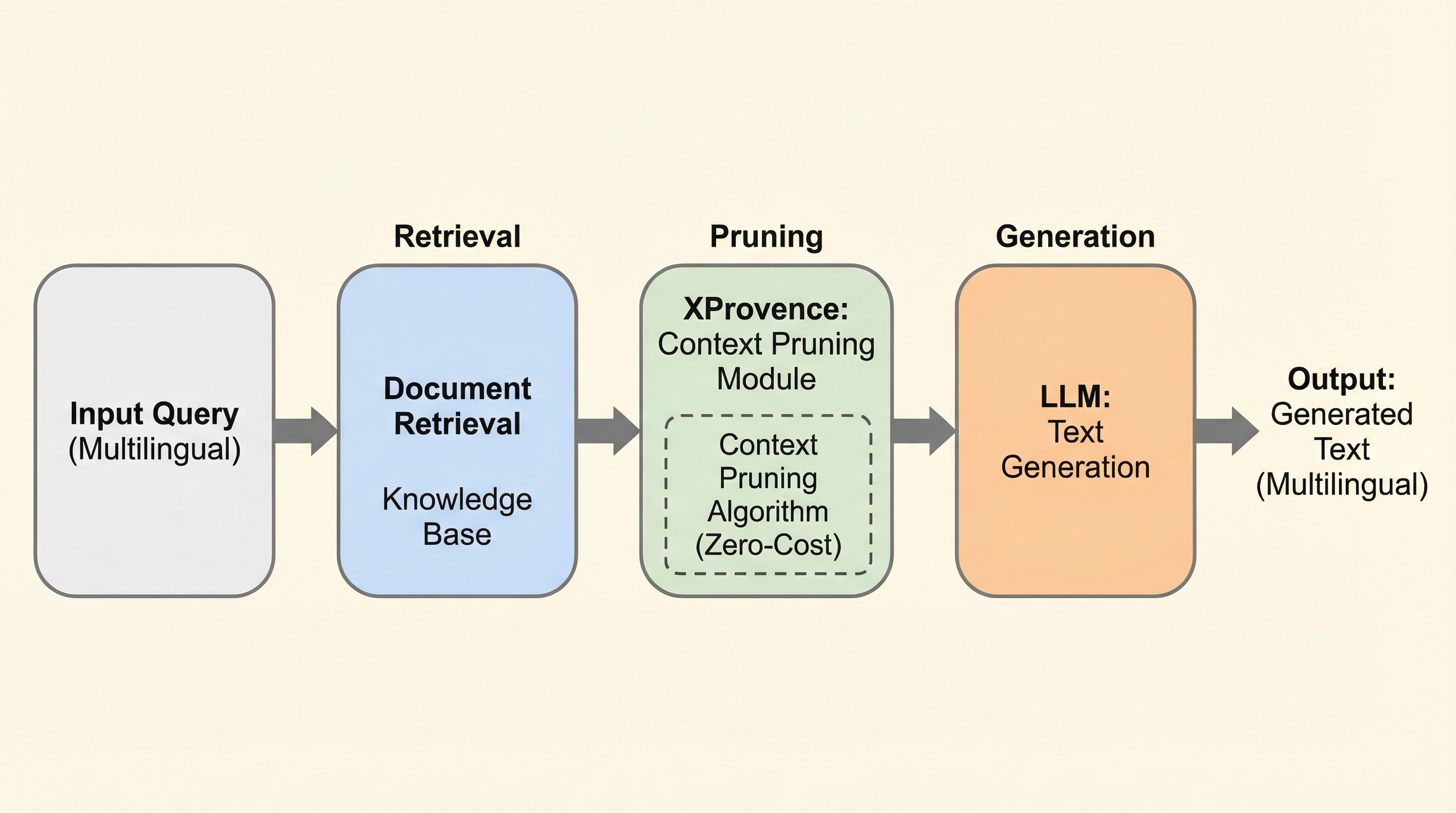
本論文では、Provenceのフレームワークを多言語へと拡張した「XProvence」を提案しています。これは、100以上の言語をサポートするBGE-M3リランカーをベースモデルとして採用し、リランキング(再順位付け)とコンテキスト削減を単一のモデルで同時に実行できるようにしたものです。XProvenceの最大の特徴は、リランカーがクエリと文書の関連性を計算する際に生成する「クエリを考慮した表現」を直接利用して、文単位での重要度判定を行う点にあります。これにより、RAGのパイプラインにおいてリランキングの後に別途削減用のモデルを動かす必要がなくなり、実質的な追加コストなしでコンテキストの最適化が可能になります。 研究チームは、この多言語対応を実現するために、最適な学習レシピの探索を行いました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related