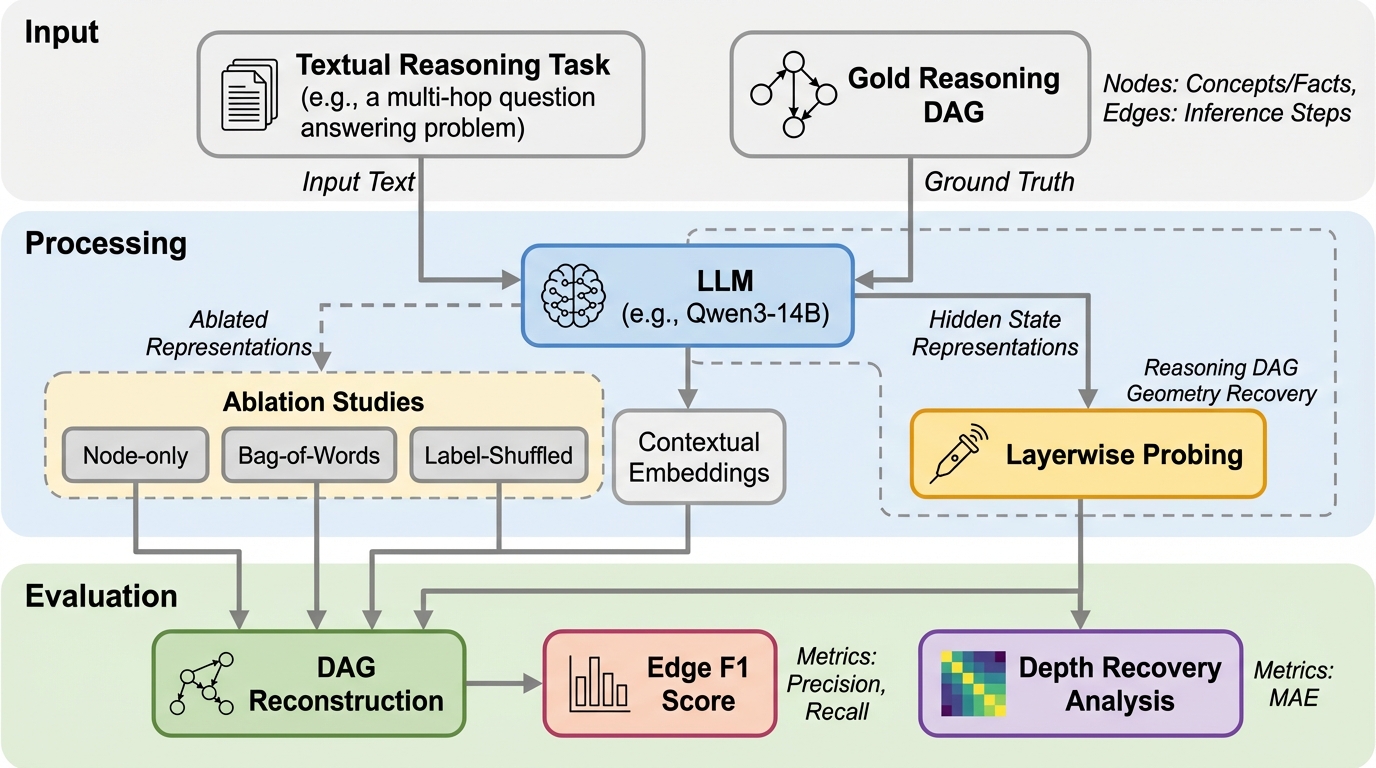
チェーンからDAGへ:LLMにおける推論のグラフ構造の探究
大規模言語モデル(LLM)の内部的な推論プロセスは、従来の「思考の連鎖(CoT)」のような単純な線形構造ではなく、複数の前提や分岐、再利用を含む「有向非巡回グラフ(DAG)」として空間的に符号化されていることを明らかにしました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の内部的な推論プロセスは、従来の「思考の連鎖(CoT)」のような単純な線形構造ではなく、複数の前提や分岐、再利用を含む「有向非巡回グラフ(DAG)」として空間的に符号化されていることを明らかにしました。
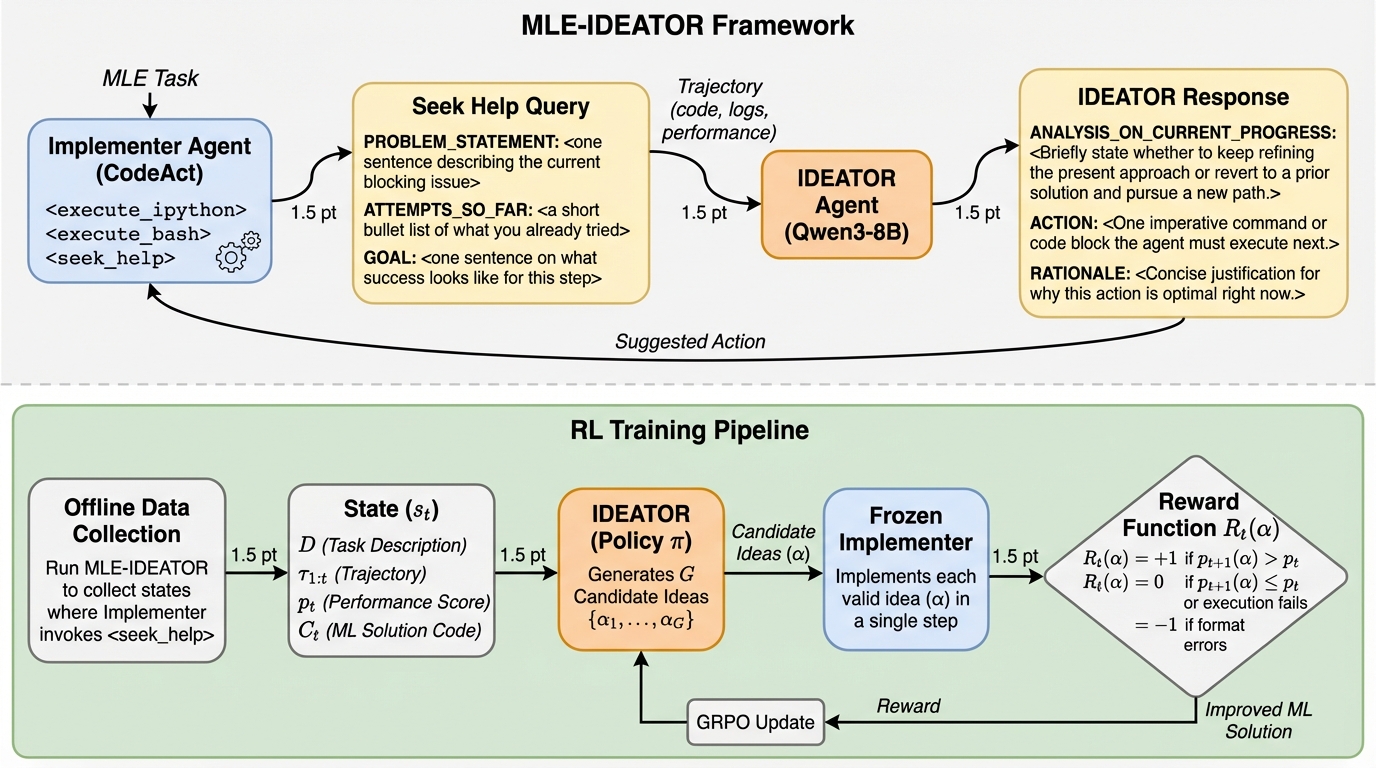
機械学習エンジニアリング(MLE)において、戦略的なアイデア創出とコード実装を分離した二層エージェント構成「MLE-IDEATOR」を開発し、従来の実装のみを行うエージェントを大幅に上回る性能を達成した。 強化学習(GRPO)を用いて軽量なQwen3-8Bモデルを訓練した結果、未訓練時と比較して11.
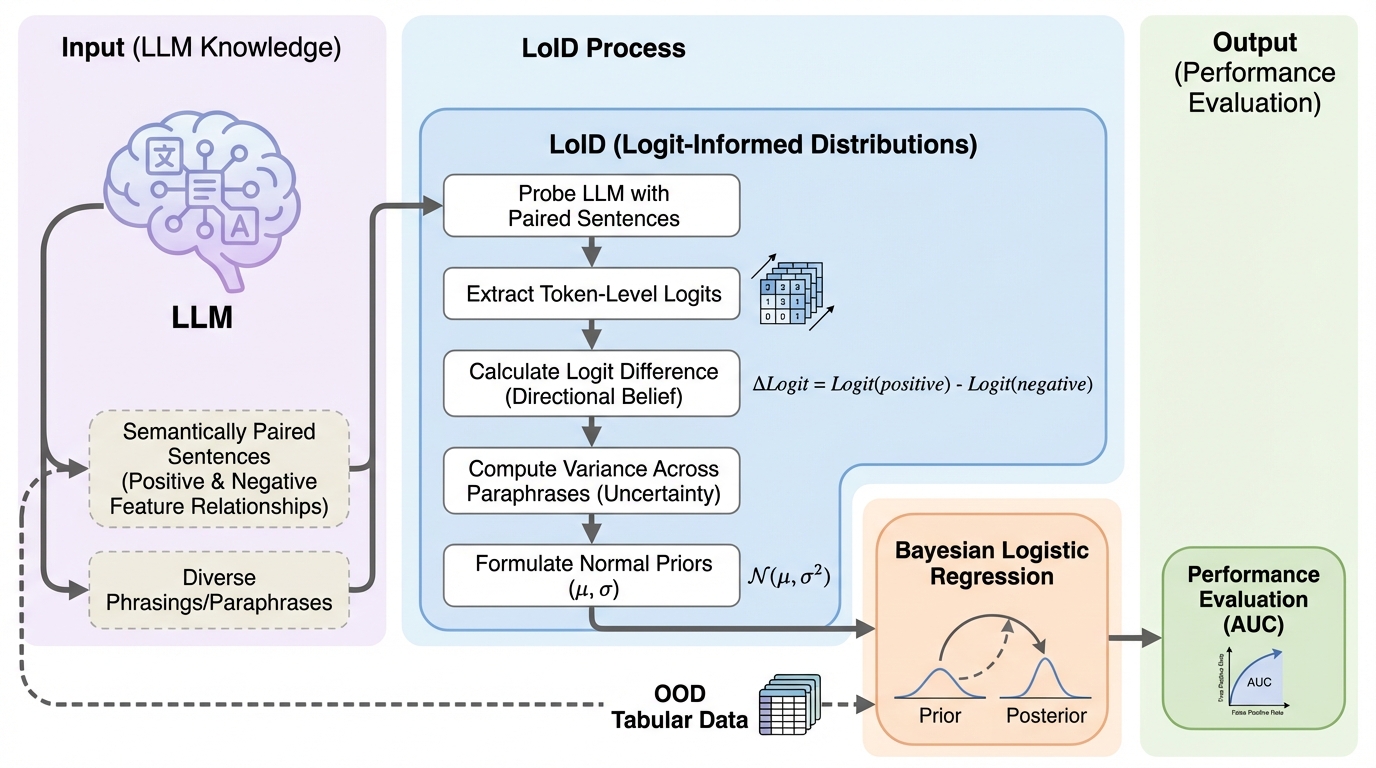
医療や金融分野ではラベル付きデータの収集が困難であり、少数の偏ったデータで学習したモデルは未知のデータ分布に対して汎化性能が著しく低下するという深刻な課題がある。 本研究が提案するLoIDは、大規模言語モデルが内部に持つ知識をテキスト生成ではなくトークン単位のロジットとして直接抽出する決定論的な手法であり、ベイズ統計学の事前分布として統合する。 10種類の公開データセットを用いた検証の結果、LoIDは既存手法を上回る精度を記録し、理想的なモデルとの性能差を最大59%回復させるなど、高い信頼性と計算効率、そして再現性を示した。
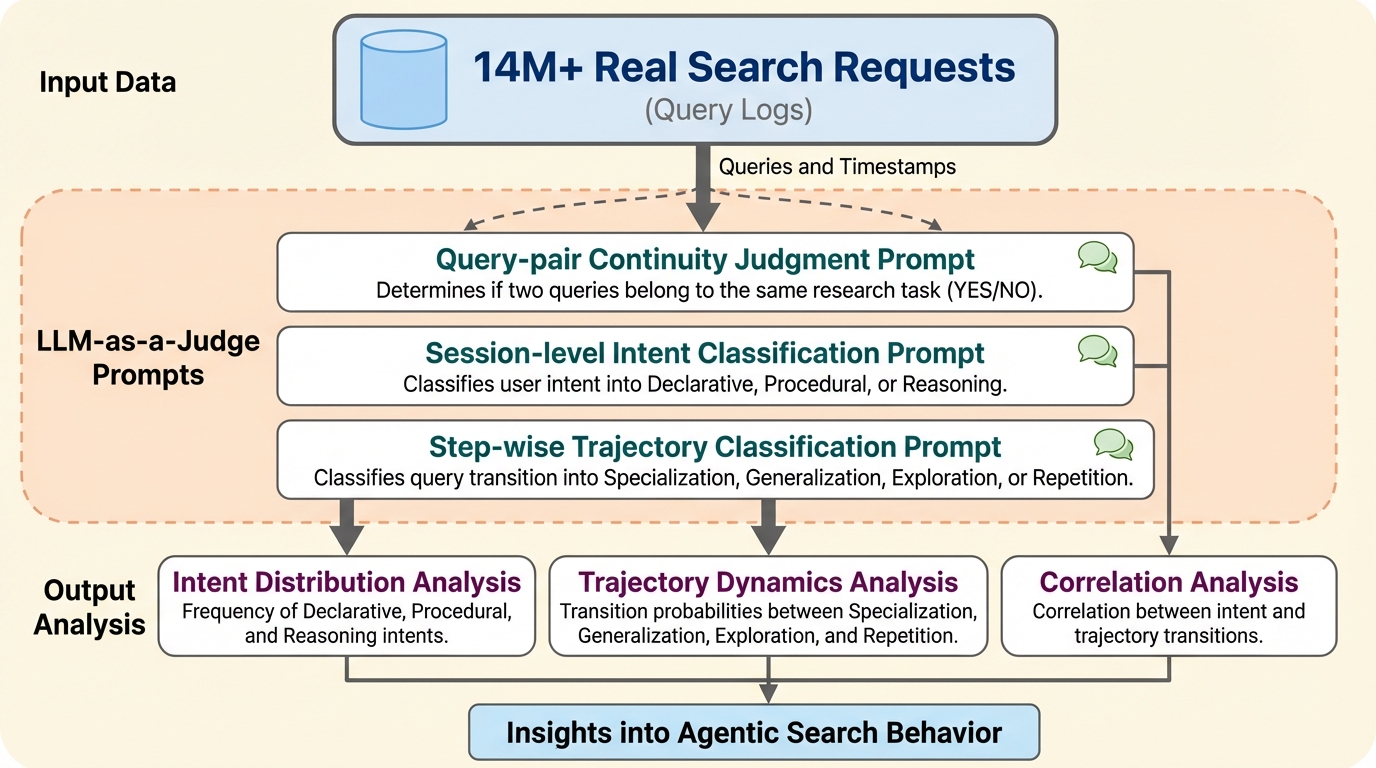
本研究は、1444万件以上の実検索リクエストと397万件のセッションを含む大規模ログを分析し、自律型エージェントの検索行動を世界で初めて包括的に解明しました。 エージェントの検索意図(事実確認、手続き、推論)によって行動パターンが大きく異なり、特に事実確認では非効率な重複が発生しやすい一方で、推論では広範な探索が行われることを特定しました。 新規クエリ用語の54%が過去の検索結果に由来することを示す新指標「CTAR」を提案し、エージェントがセッション全体を通じて蓄積された文脈をクエリの洗練に活用していることを定量的に証明しました。
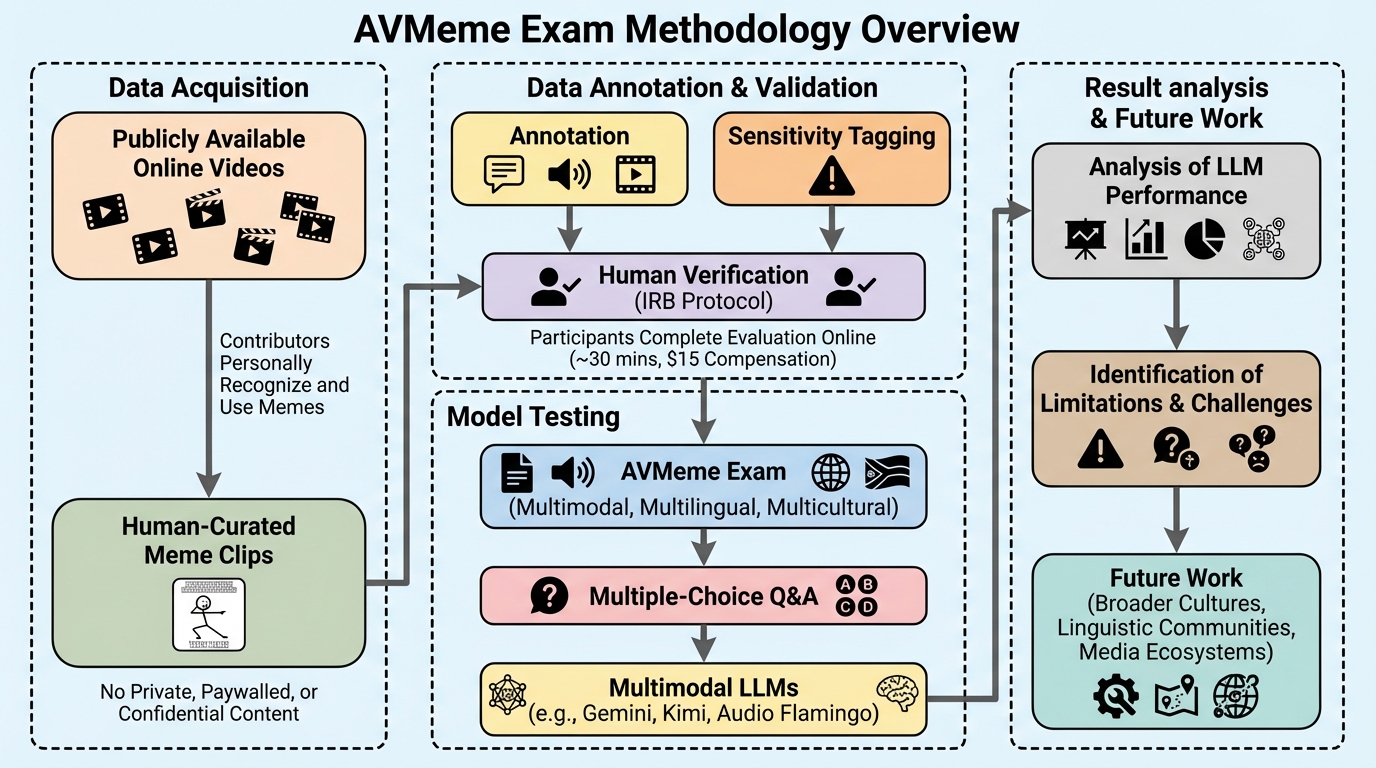
本研究では、インターネット上の音声・映像ミーム1,032件を厳選し、AIモデルが人間の文化的・文脈的な意味をどの程度理解できるかを測定する新しいベンチマーク「AVMeme Exam」を開発しました。
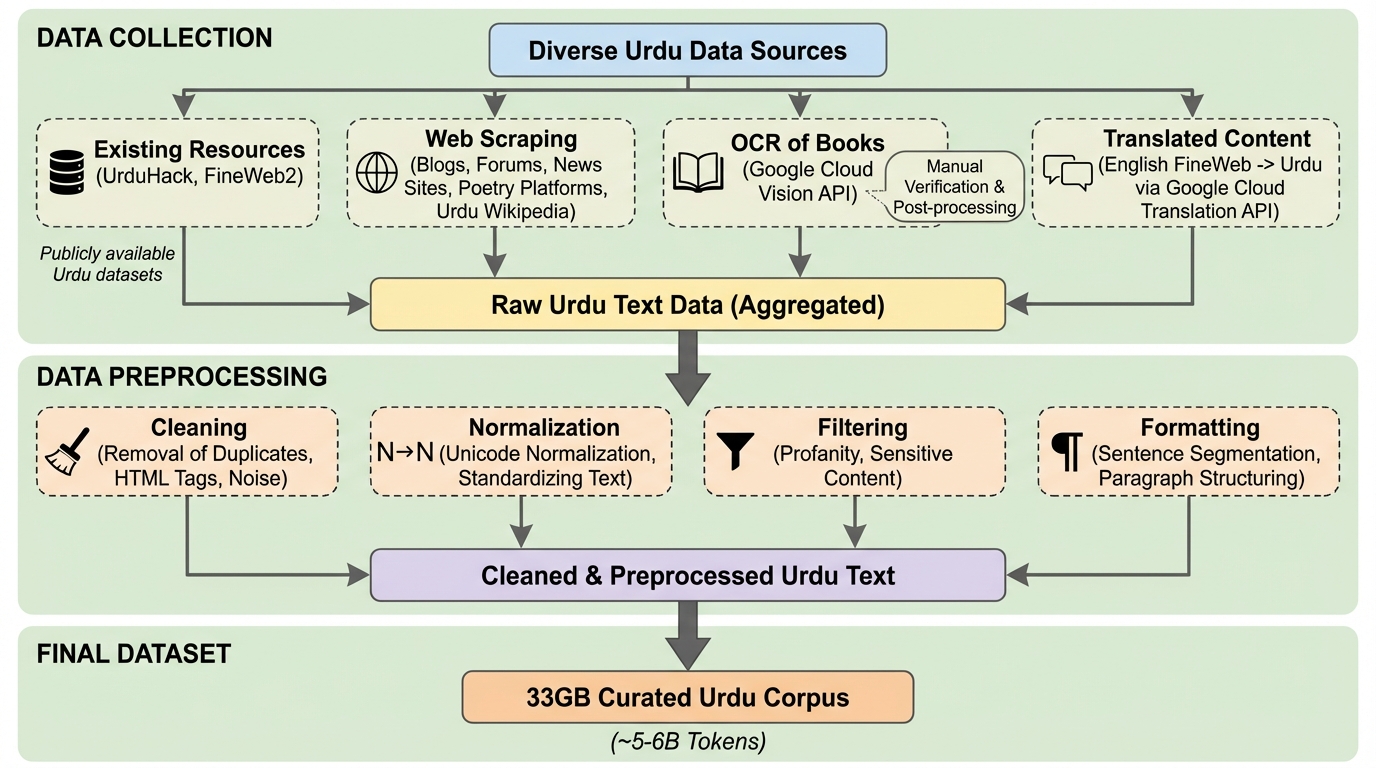
ウルドゥー語は世界で2億3000万人の話者を抱える主要言語ですが、既存の多言語モデルではトークン化の非効率性や文化的な不正確さが課題となっており、専用の生成モデルや高品質なデータセットが不足していました。
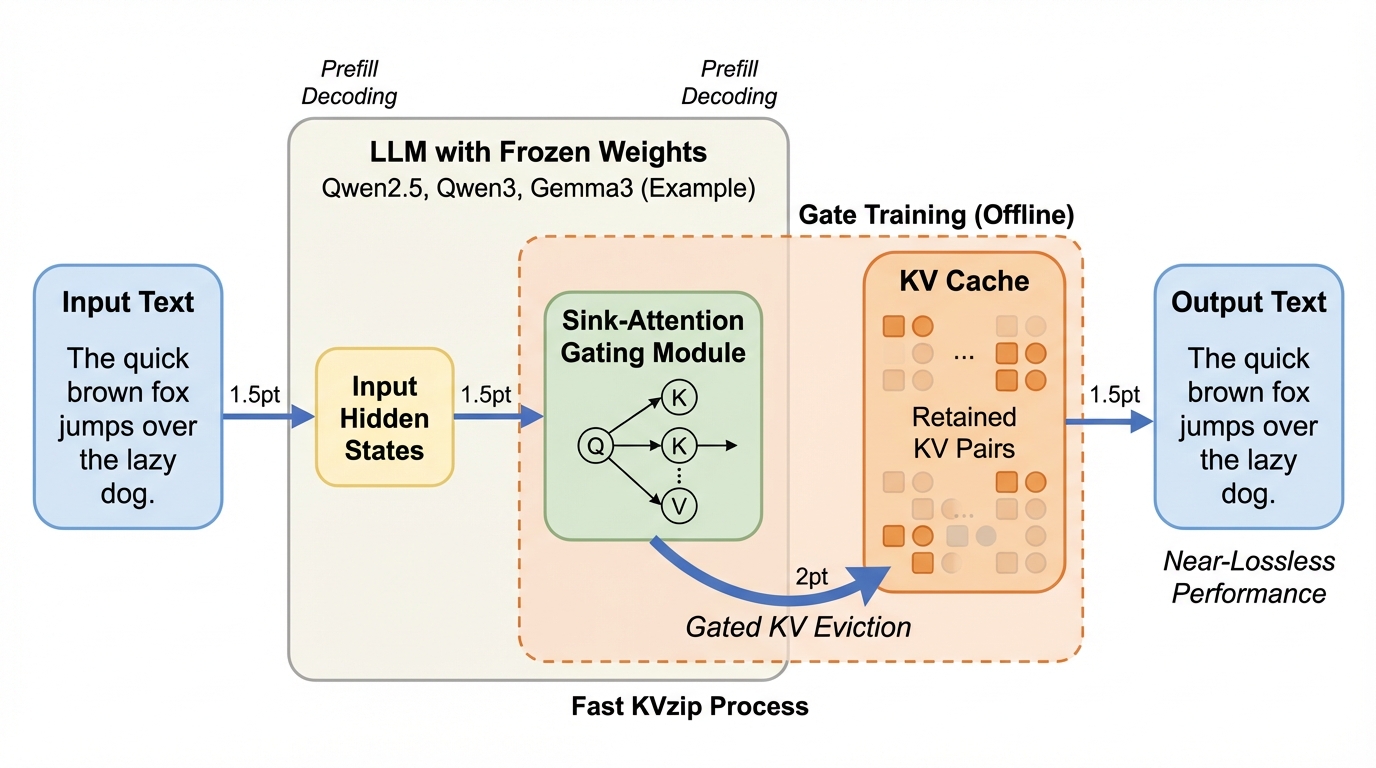
大規模言語モデル(LLM)の推論において、文脈長に比例して増大するKVキャッシュのメモリ消費を劇的に抑えるため、軽量なゲート機構を用いて不要な情報を動的に排除する新手法「Fast KVzip」が提案されました。
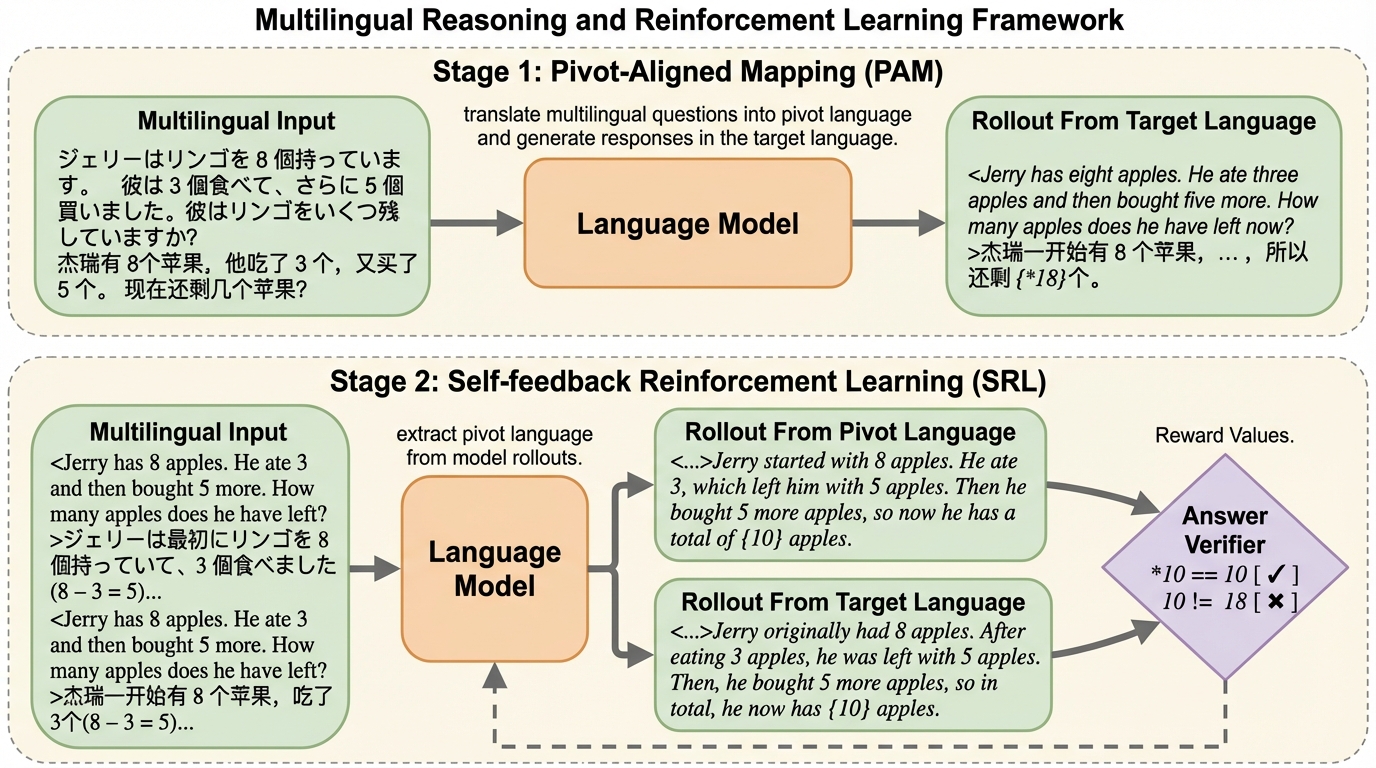
大規模言語モデル(LLM)が低リソース言語での数学的推論において性能を低下させる問題を解決するため、英語を「ピボット(軸)」として推論プロセスを整列させる新フレームワーク「PASMR」を提案しました。
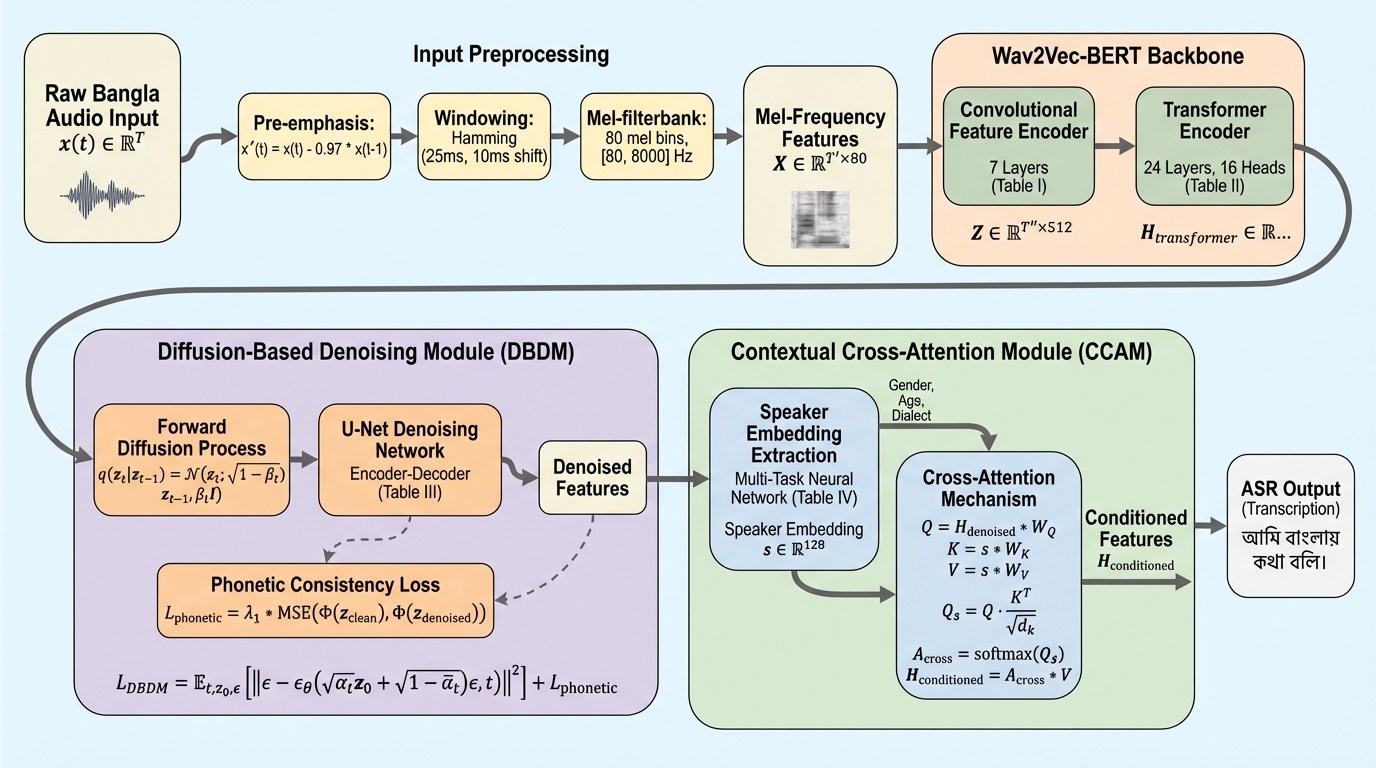
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
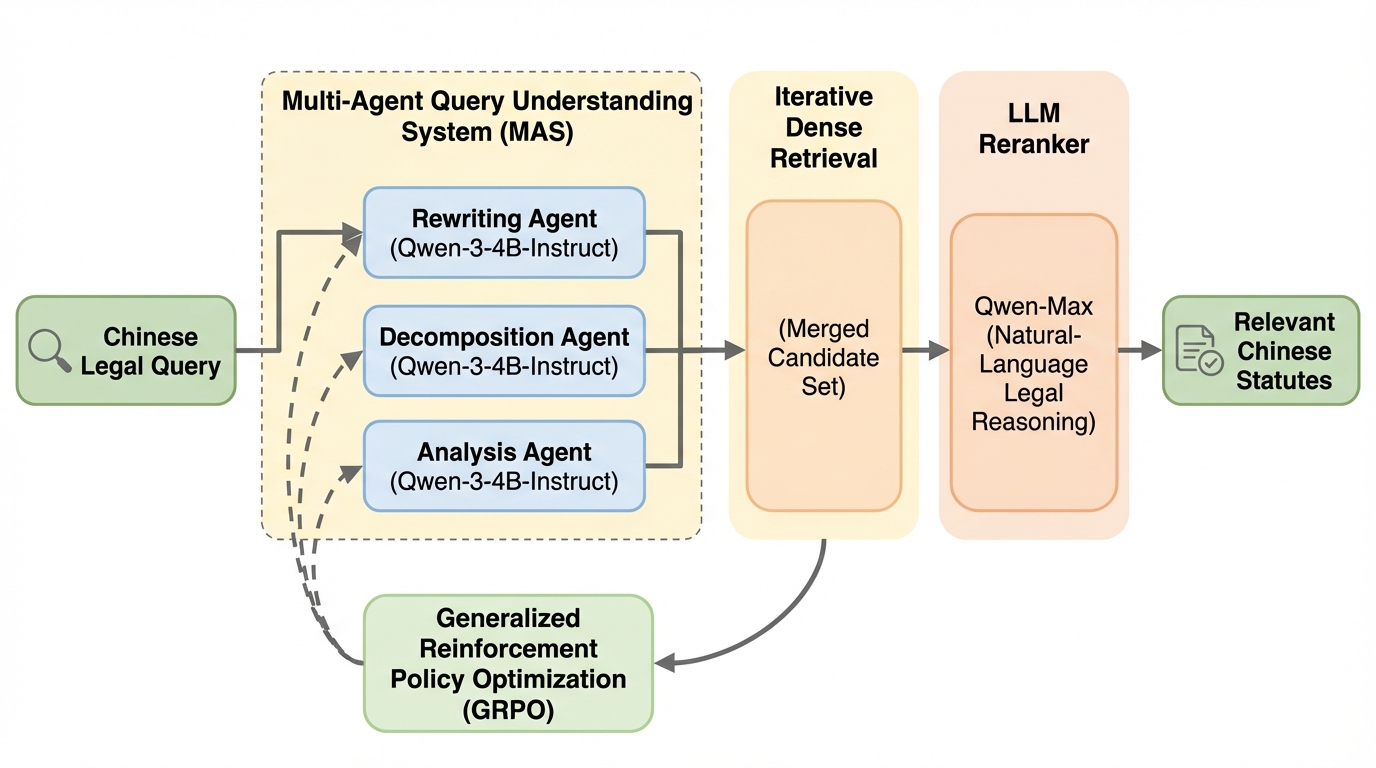
LegalMALRは、口語的で複雑な法的クエリに対し、複数のAIエージェントが多様な視点からクエリを再構成し、反復的に検索を行うことで候補の網羅性を劇的に向上させる新しいフレームワークである。このシステムは、GRPO(Generalized Reinforcement Policy Optimization)を用いてエージェントの挙動を安定化させるとともに、Qwen-Maxを活用したゼロショットのリランキングにより、従来の手法では困難だった高度な法的推論に基づく条文特定を実現している。独自の難関データセットCSAIDおよび公開ベンチマークSTARDを用いた検証の結果、LegalMALRは既存のRAGパイプラインを大幅に上回る精度を達成し、暗黙的な法的論点を含む実務的な検索課題に対して極めて有効であることが証明された。