LegalMALR:中国の法規検索のためのマルチエージェントによるクエリ理解とLLMに基づくリランキング
LegalMALRは、口語的で複雑な法的クエリに対し、複数のAIエージェントが多様な視点からクエリを再構成し、反復的に検索を行うことで候補の網羅性を劇的に向上させる新しいフレームワークである。このシステムは、GRPO(Generalized Reinforcement Policy Optimization)を用いてエージェントの挙動を安定化させるとともに、Qwen-Maxを活用したゼロショットのリランキングにより、従来の手法では困難だった高度な法的推論に基づく条文特定を実現している。独自の難関データセットCSAIDおよび公開ベンチマークSTARDを用いた検証の結果、LegalMALRは既存のRAGパイプラインを大幅に上回る精度を達成し、暗黙的な法的論点を含む実務的な検索課題に対して極めて有効であることが証明された。
TL;DR(結論)
LegalMALRは、口語的で複雑な法的クエリに対し、複数のAIエージェントが多様な視点からクエリを再構成し、反復的に検索を行うことで候補の網羅性を劇的に向上させる新しいフレームワークである。このシステムは、GRPO(Generalized Reinforcement Policy Optimization)を用いてエージェントの挙動を安定化させるとともに、Qwen-Maxを活用したゼロショットのリランキングにより、従来の手法では困難だった高度な法的推論に基づく条文特定を実現している。独自の難関データセットCSAIDおよび公開ベンチマークSTARDを用いた検証の結果、LegalMALRは既存のRAGパイプラインを大幅に上回る精度を達成し、暗黙的な法的論点を含む実務的な検索課題に対して極めて有効であることが証明された。
なぜこの問題か
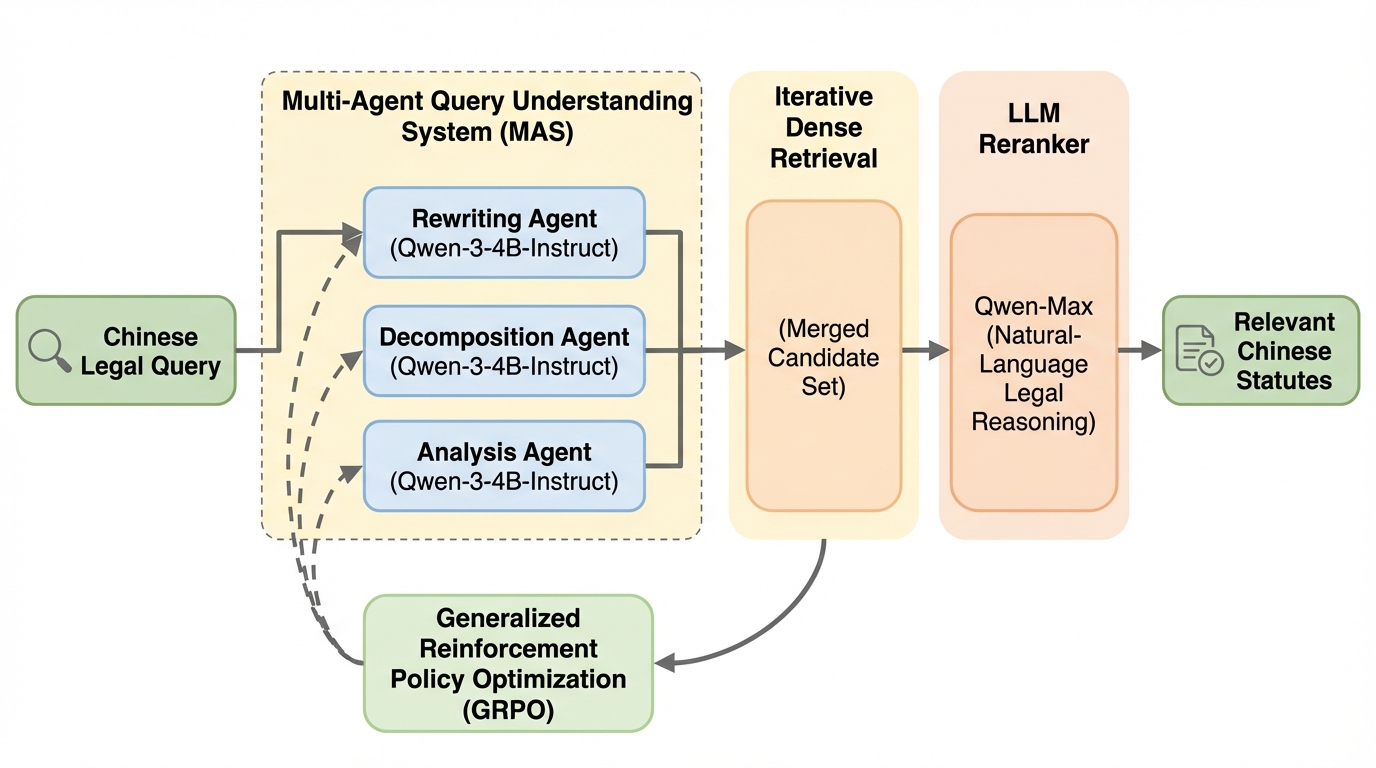
法律情報の検索は、現代の法的支援、コンプライアンス監査、および司法判断支援システムにおいて中核となるコンポーネントである。しかし、一般的な検索とは異なり、法律検索は高度に構造化された長い法条文を対象とし、事実条件と法的要素の間の複雑な関係を推論しなければならないという特有の困難がある。現実世界のユーザーが入力するクエリは、法的な専門用語を直接引用するのではなく、事実関係を物語風に記述したり、日常的な口語表現を用いたりすることが多い。このようなクエリは、しばしば重要な法的要素を欠いていたり、複数の法的論点を暗黙的に含んでいたりするため、正確な検索を行うにはキーワードの一致や単純な意味的類似性を超えて、クエリの潜在的な教義構造を再構築する必要がある。 既存の検索拡張生成(RAG)パイプラインには、この文脈においていくつかの重大な限界が存在する。第一に、高密度検索(Dense Retrieval)モジュールは通常、元のユーザークエリをそのまま処理するが、単一の法的質問に複数の法的問題や条文要素が隠されている可能性を考慮していない。…
核心:何を提案したのか
本研究では、上述の課題を解決するために、マルチエージェント・クエリ理解システム(MAS)と、ゼロショットのLLMベース・リランキングモジュール(LLM Reranker)を統合した検索フレームワーク「LegalMALR」を提案している。このフレームワークの核心は、検索のプロセスを「探索的な再現(Recall)」と「精度重視の法的判断(Precision)」の二段階に明確に分離し、それぞれに最適化されたモデル構成を採用した点にある。LegalMALRは、従来の単一クエリによる一回限りの検索を、複数の専門エージェントによる多角的な分析と反復的な検索プロセスへと置き換えるものである。 MASの段階では、複数の専門エージェントが入力クエリを分析し、書き換え、分解することで、法的根拠に基づいた多様な再構成案を生成する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related