ピボットへの整列:多言語数学推論のための自己フィードバックを用いた二重アライメント
大規模言語モデル(LLM)が低リソース言語での数学的推論において性能を低下させる問題を解決するため、英語を「ピボット(軸)」として推論プロセスを整列させる新フレームワーク「PASMR」を提案しました。
TL;DR(結論)
大規模言語モデル(LLM)が低リソース言語での数学的推論において性能を低下させる問題を解決するため、英語を「ピボット(軸)」として推論プロセスを整列させる新フレームワーク「PASMR」を提案しました。 この手法は、問題をピボット言語に変換して推論パターンを一致させる「ピボット整列マッピング(PAM)」と、モデル自身の英語回答を報酬として利用し外部の正解データに頼らず学習する「自己フィードバック強化学習(SRL)」の2段階で構成されます。 実験の結果、MistralやLlama-3などのモデルにおいて低リソース言語の精度が最大32.8%向上し、正解ラベルを用いた従来の強化学習を上回る性能と、未知のデータセットに対する高い堅牢性が実証されました。
なぜこの問題か
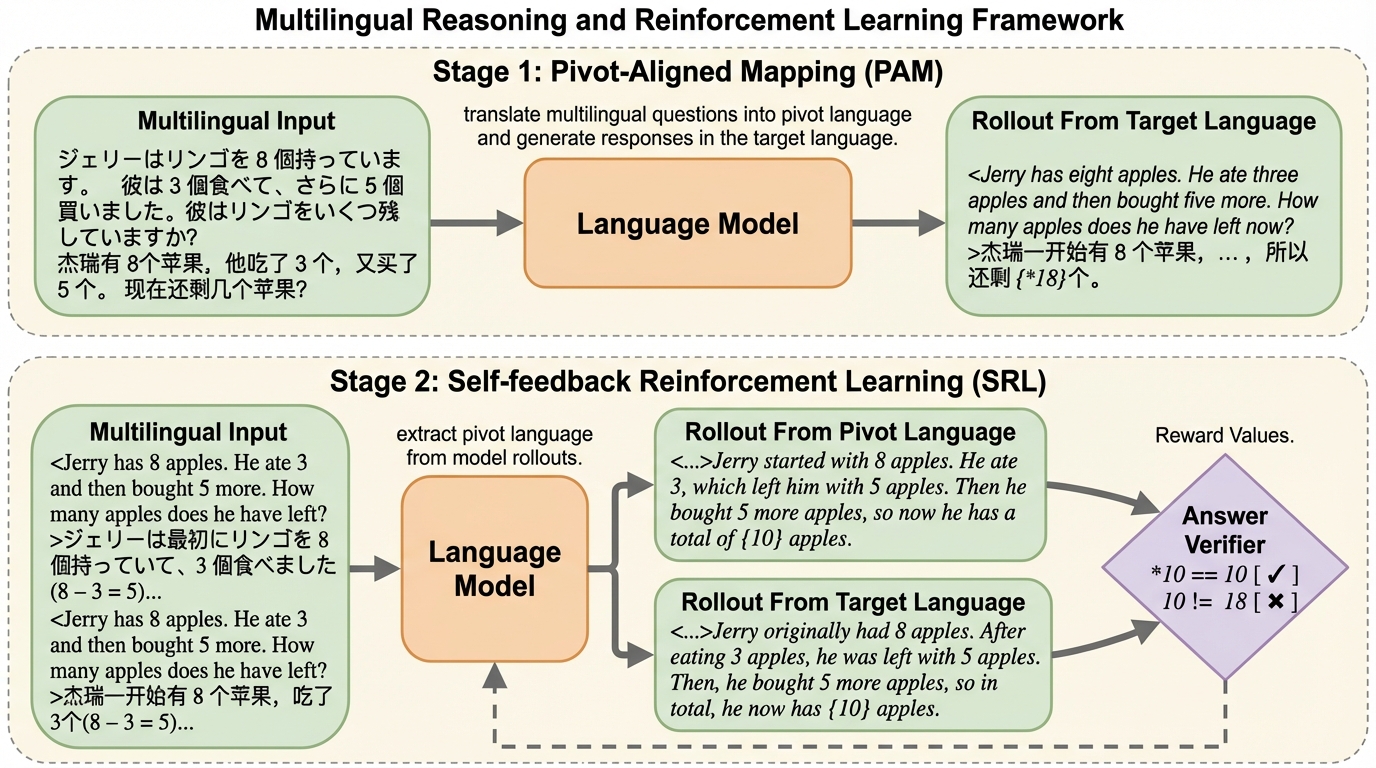
大規模言語モデルは驚異的な推論能力を示していますが、その能力はすべての言語で均等に発揮されるわけではありません。特に学習データが乏しい低リソース言語においては、英語などの高リソース言語と比較して数学的推論の精度が著しく低下するという課題があります。この性能差が生じる根本的な原因として、モデル内部における多言語の理解と推論のプロセスが、言語間で一貫して整列(アライメント)されていないことが挙げられます。数学的な論理構造は本来、言語に依存しない普遍的なものであるはずですが、現実のモデルでは言語ごとに推論の質に大きな隔たりが存在しています。 既存の研究によれば、LLMが多言語タスクを処理する際には、まず入力を得意な言語(主要言語)にマッピングし、その言語で推論を行い、最後に結果をターゲット言語に書き戻すという3段階のステップを踏むことが示唆されています。しかし、著者らの詳細な調査により、英語以外の言語での回答は英語の回答と一致する傾向があるものの、その精度は英語より低く、完全な一致には至っていないことが判明しました。…
核心:何を提案したのか
本研究では、多言語数学推論における性能低下を克服するために、PASMR(Pivot-Aligned Self-Feedback Multilingual Reasoning)という革新的な学習フレームワークを提案しました。このフレームワークの核心的なアイデアは、モデルが最も高い推論能力を発揮する言語(通常は英語)を「ピボット言語」として定義し、他のすべての言語の推論プロセスをこのピボットに強制的に整列させることにあります。これにより、モデルが持つ英語での強力な論理的思考能力を、他の言語での回答生成に直接的に活用することが可能になります。 PASMRは、大きく分けて2つの独立した、かつ相互に補完し合うステージで構成されています。第1ステージは「ピボット整列マッピング(PAM)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related