堅牢なグリーンウォッシング検知のための言語モデルの強化
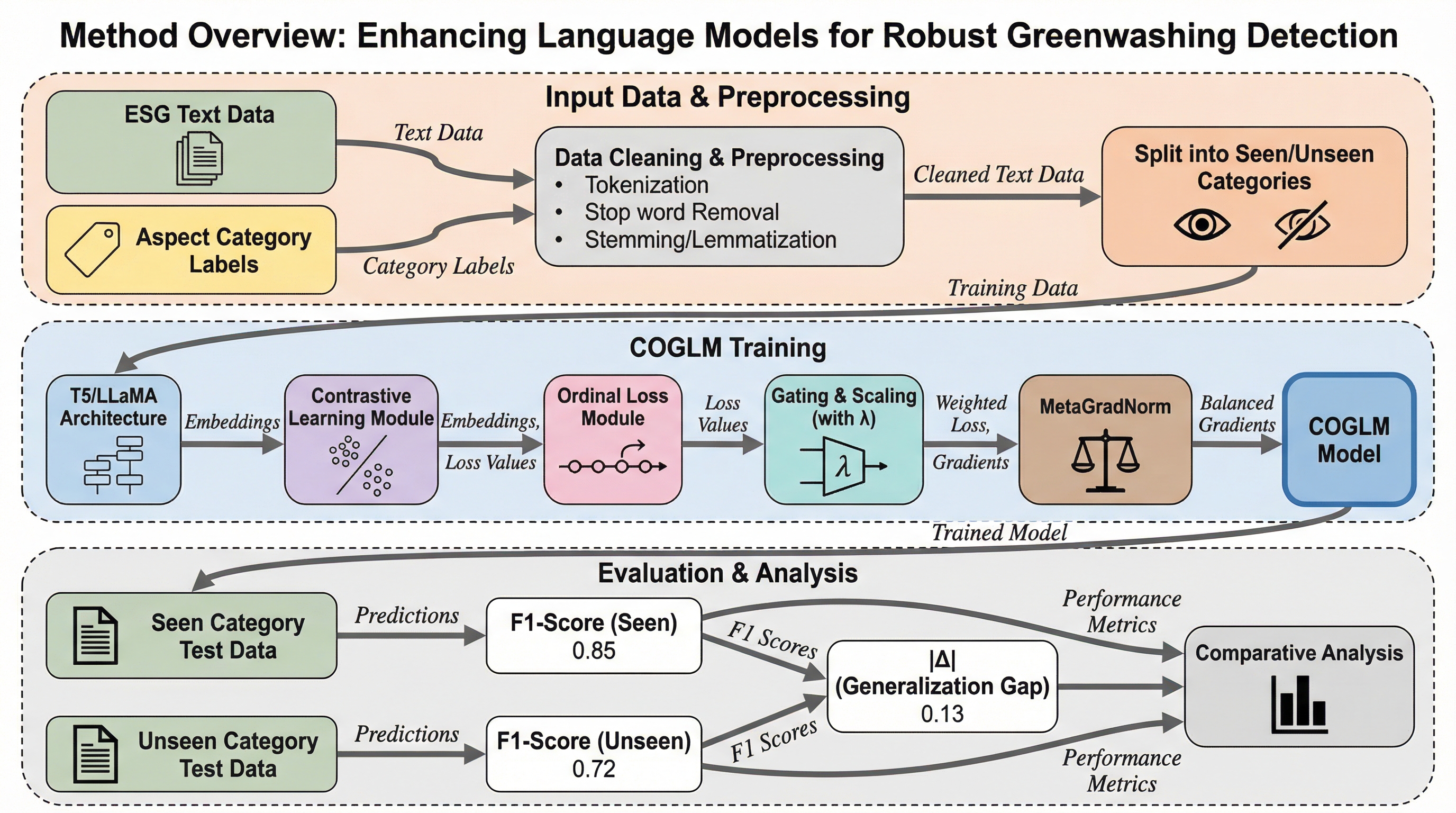
企業のサステナビリティ報告書におけるグリーンウォッシュや曖昧な主張を特定するため、大規模言語モデルの潜在空間を構造化する新しいパラメータ効率の良い学習フレームワーク「COGLM」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
企業のサステナビリティ報告書におけるグリーンウォッシュや曖昧な主張を特定するため、大規模言語モデルの潜在空間を構造化する新しいパラメータ効率の良い学習フレームワーク「COGLM」が提案されました。
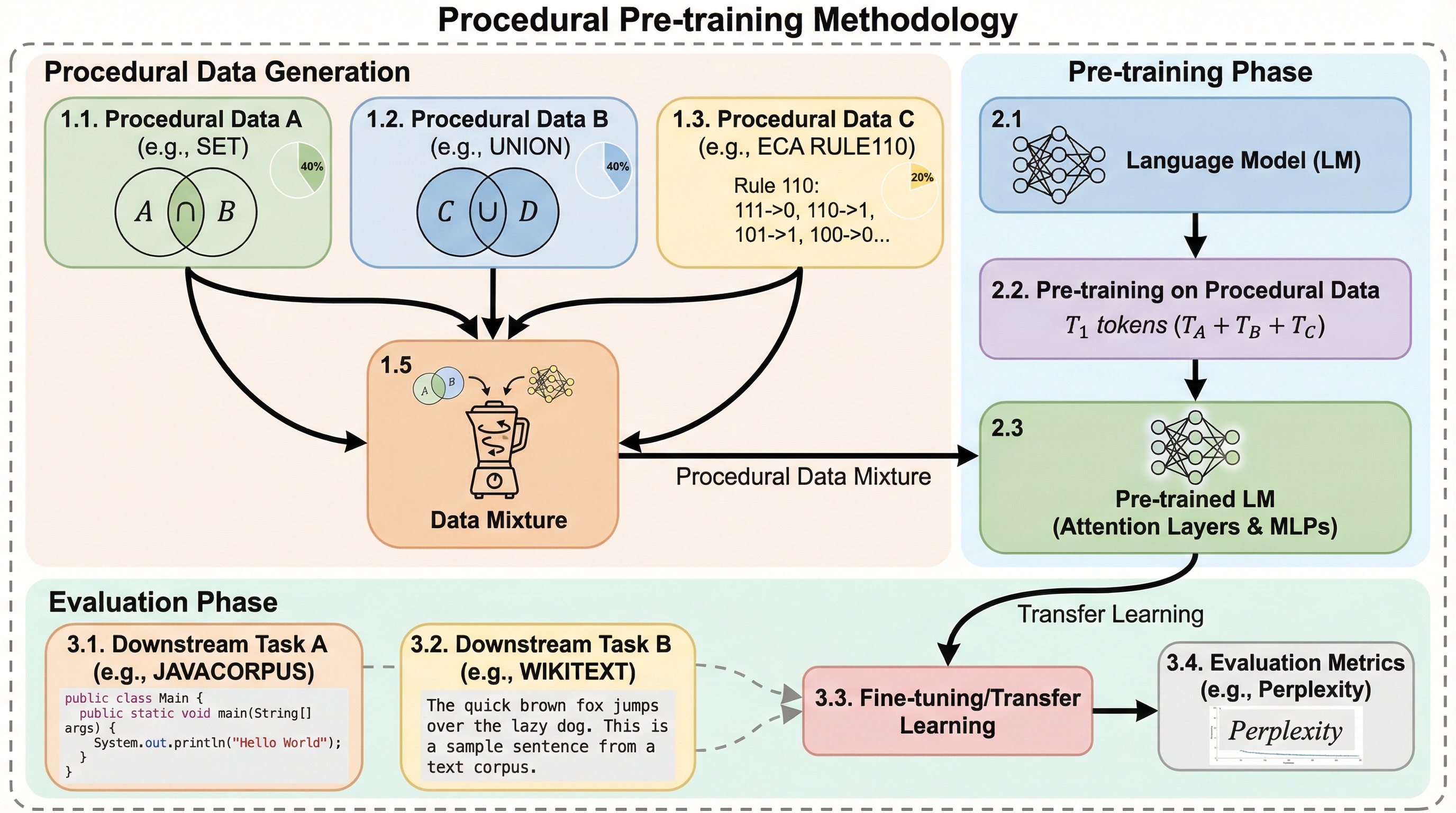
大規模言語モデルの学習において、自然言語の前に抽象的な構造を持つ「手続き型データ」を学習させる「手続き型事前学習」という手法が提案されました。この手法は、特定のアルゴリズムタスク(コンテキスト想起など)の精度を10%から98%へ劇的に向上させ、標準的な自然言語やコードの学習を大幅に加速させる効果があります。
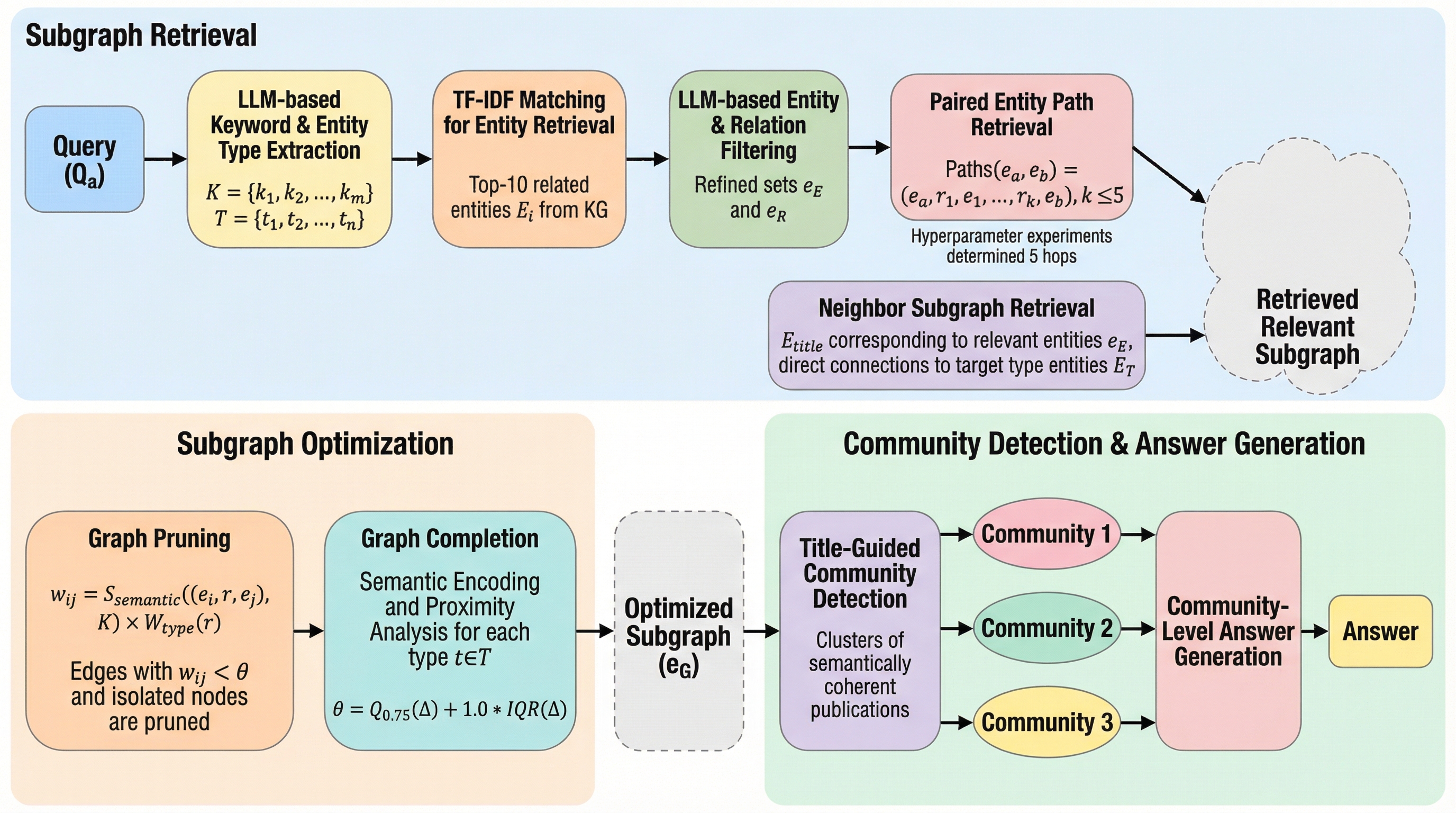
大規模言語モデル(LLM)を用いた科学文献の質問応答において、従来の検索手法では論文間の深い意味的つながりを見落とし、回答の包括性や具体性が損なわれるという課題がありました。 本研究が提案するCE-GOCDは、論文タイトルを中心エンティティとして定義し、グラフの枝刈りや補完による最適化とコミュニティ検出を組み合わせることで、文献間の潜在的な関係を明示的にモデル化します。 NLP分野の複数のデータセットを用いた検証の結果、提案手法は既存のグラフ活用型RAG手法を上回る精度を達成し、医学ドメインへの適応可能性や回答生成における高い網羅性と正確性が確認されました。
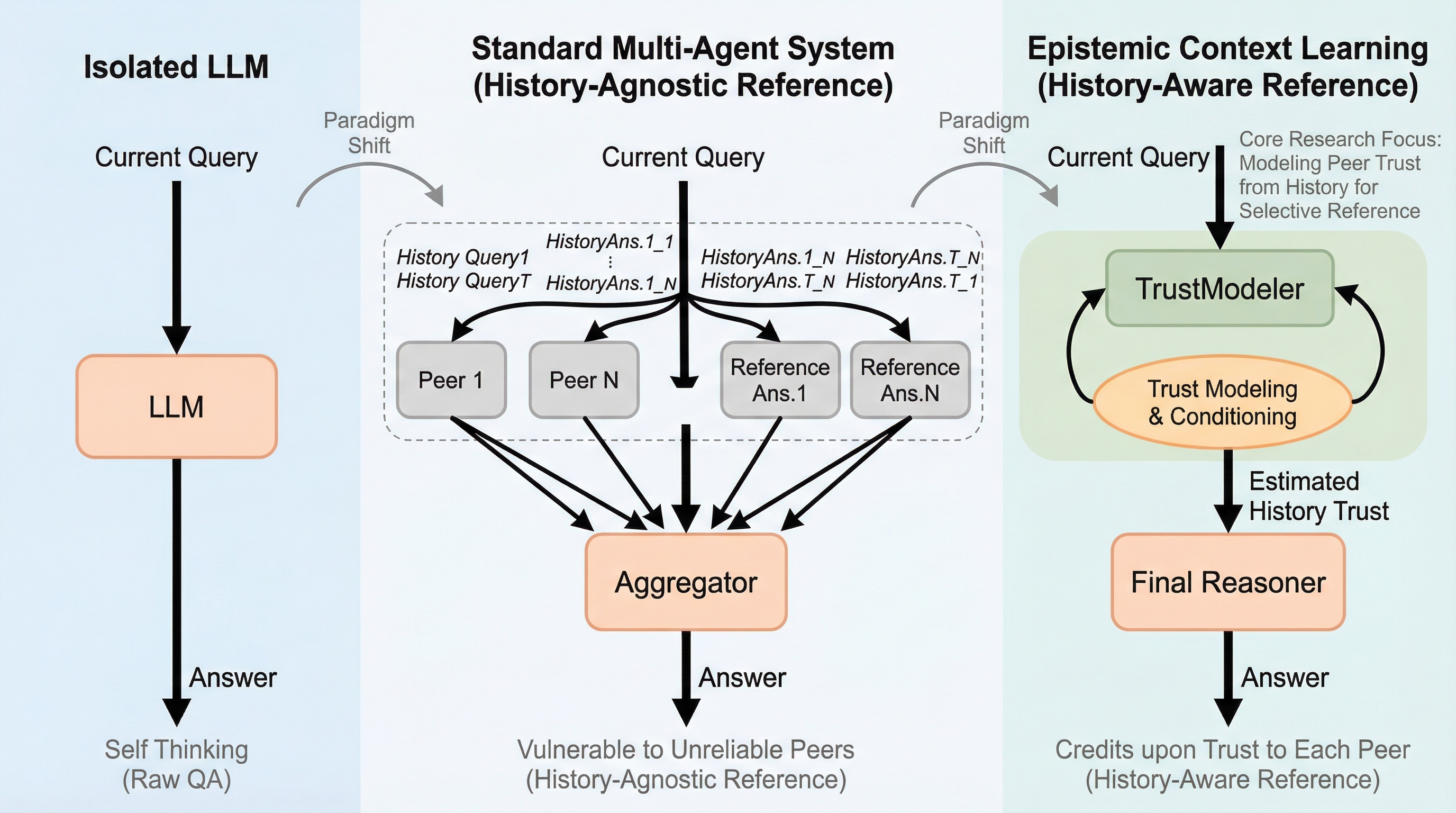
LLMベースのマルチエージェントシステムにおいて、エージェントが誤った情報を持つ他者に盲目的に同調してしまう脆弱性を解決するため、過去の対話履歴から他者の信頼性を評価して情報を選択的に参照する「履歴を考慮した参照」という新しいパラダイムを提案した。
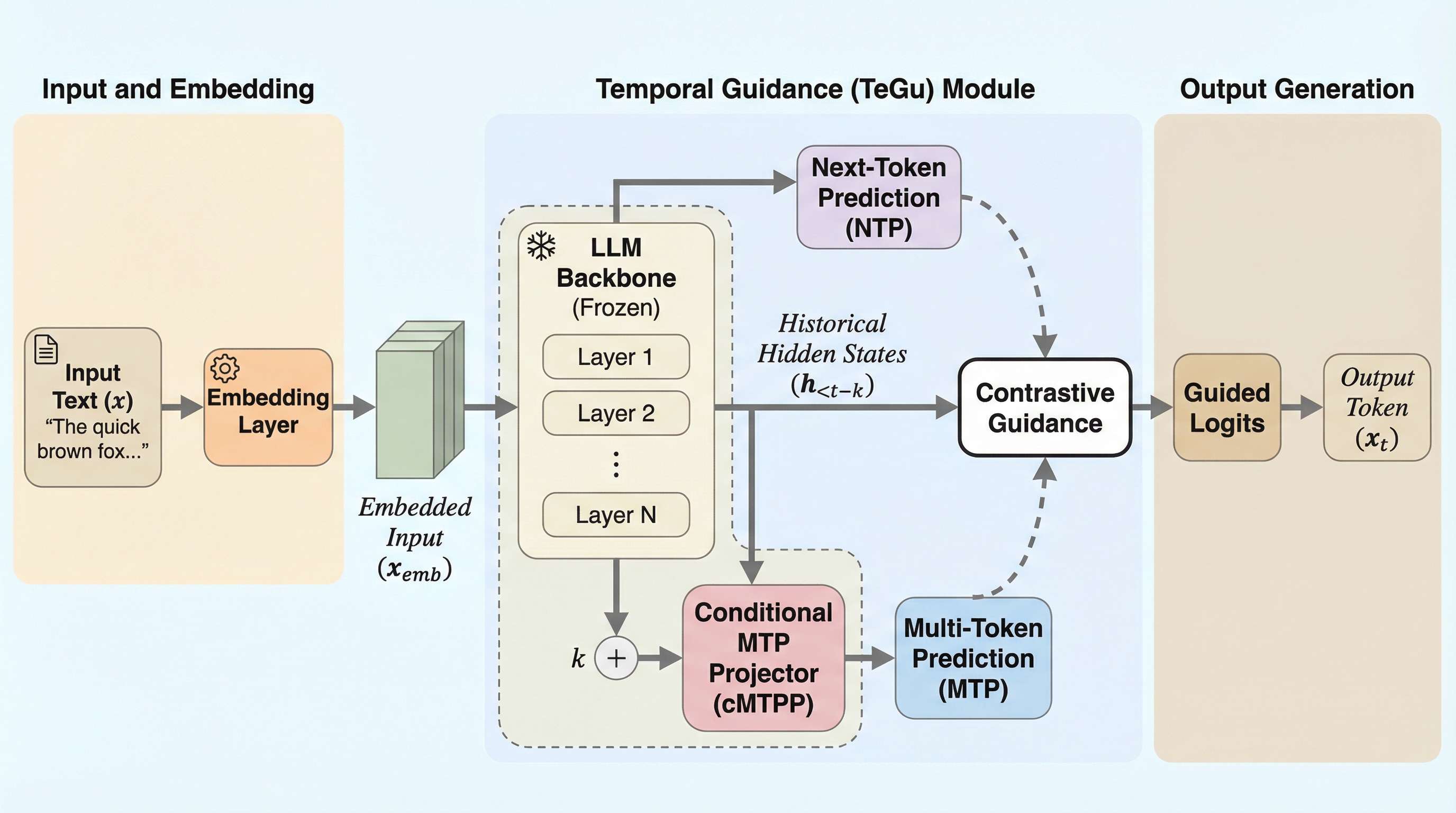
大規模言語モデル(LLM)の生成品質を向上させるため、モデル自身の過去の不完全な予測を「アマチュア」として利用し、現在の予測と対比させる新しいデコーディング戦略「TeGu(Temporal Guidance)」が提案されました。
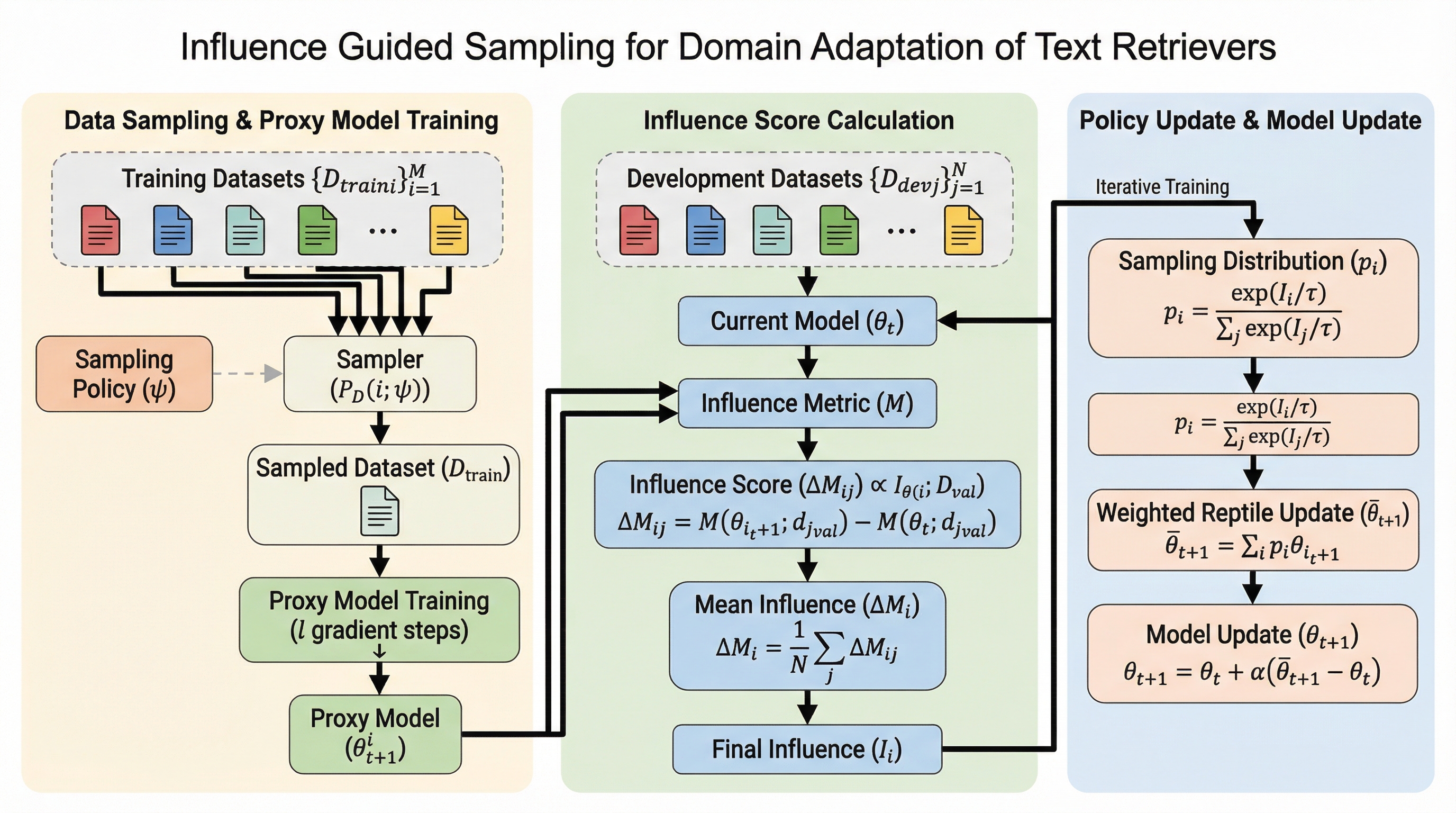
検索モデルの学習において、膨大で多様なデータセットから最適な訓練データを抽出する戦略は極めて重要ですが、従来の均等サンプリングや専門家の手動設定、あるいは勾配ベースの動的手法には、計算コストの増大や学習の不安定さという課題がありました。
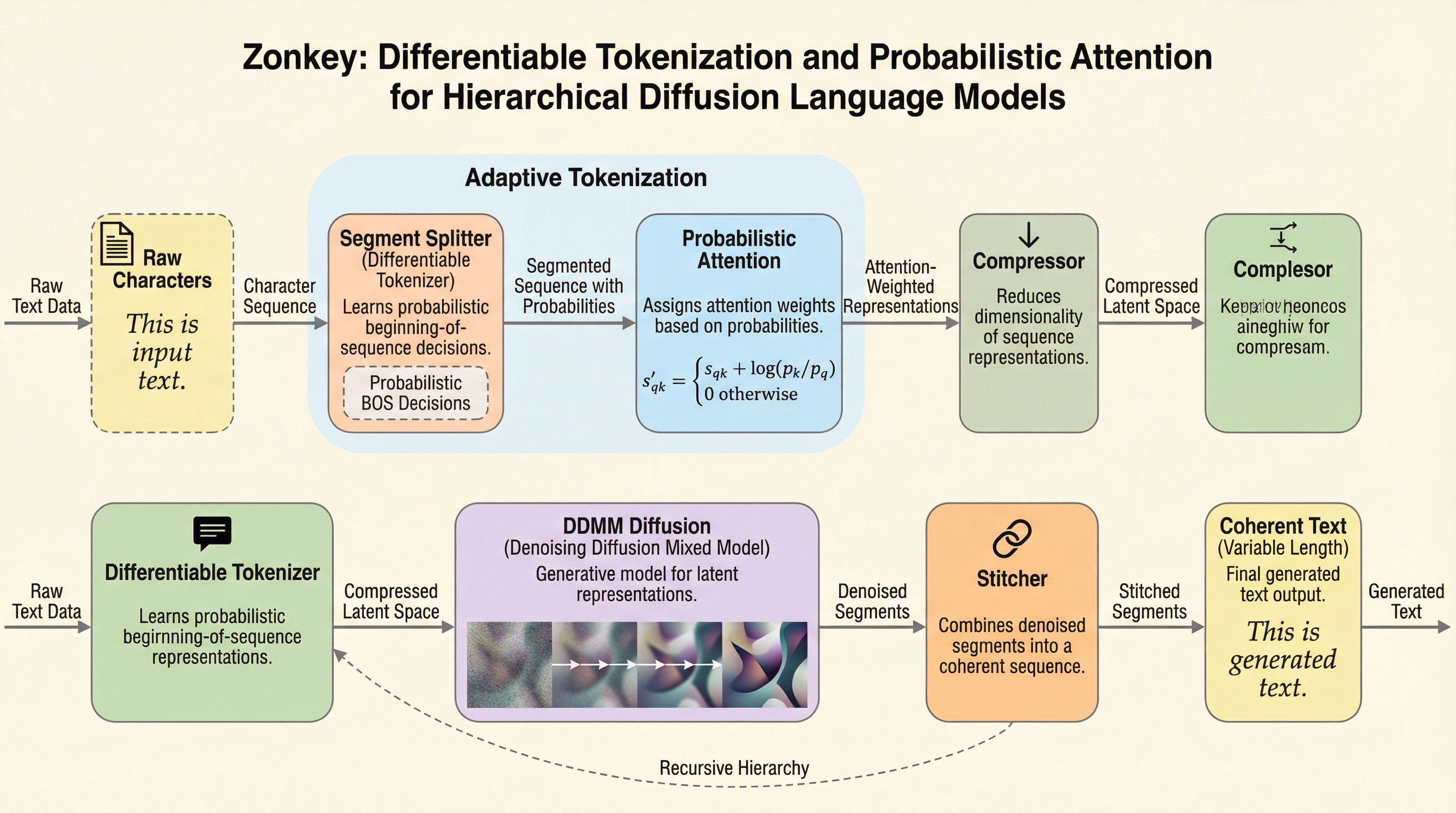
Zonkeyは、従来の固定されたトークナイザー(BPE)が抱える非微分性やドメイン適応の困難さを解消するため、生の文字から文書レベルの表現までを完全に微分可能なパイプラインで構築した階層型拡散言語モデルである。
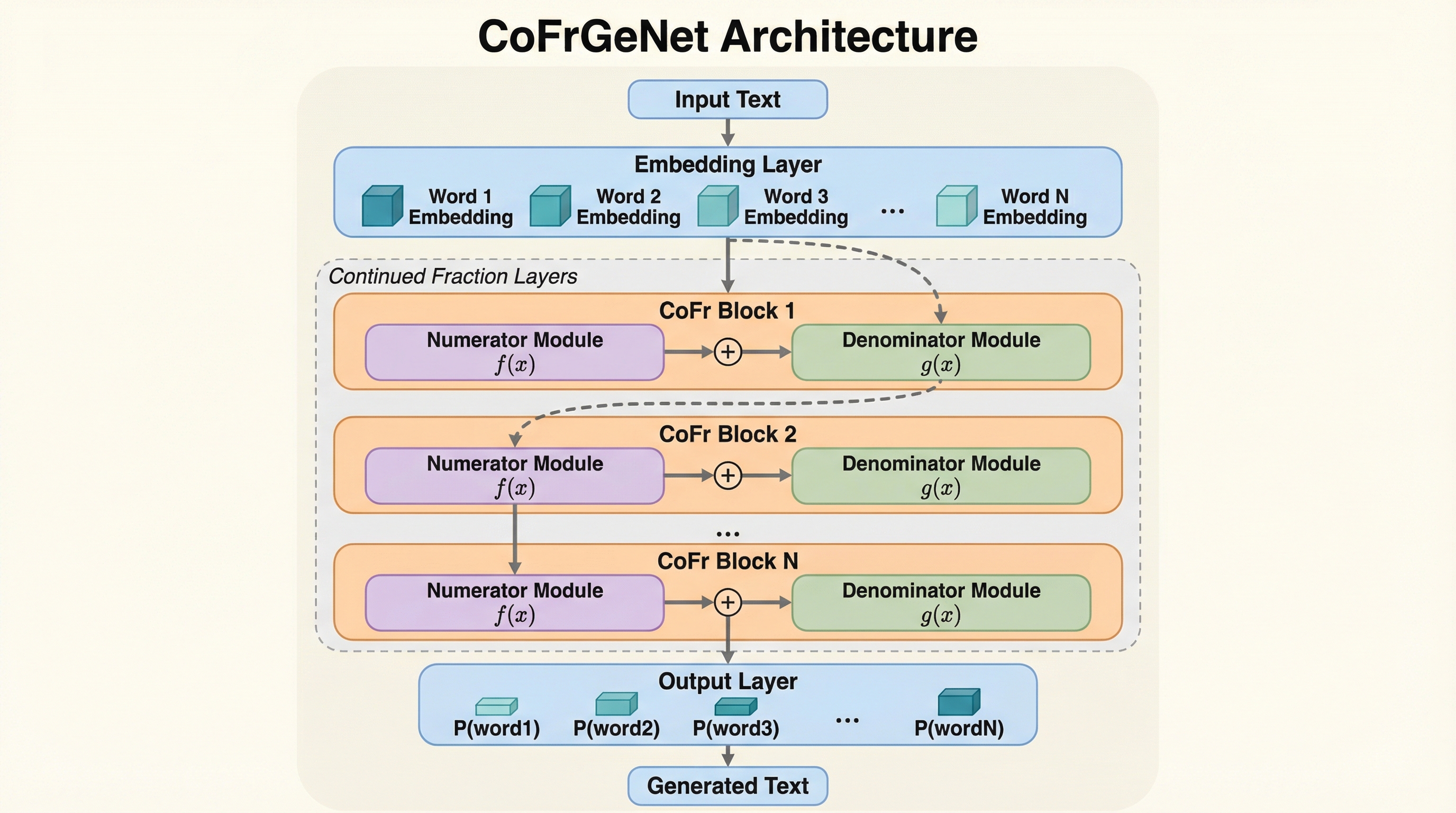
IBM Researchの研究チームは、連分数(Continued Fractions)の数学的構造を言語生成モデルに組み込んだ新アーキテクチャ「CoFrGeNet」を提案しました。このモデルは、従来のTransformerにおけるマルチヘッドアテンションやフィードフォワードネットワーク(FFN)を、より少ないパラメータ数で代替可能な連分数コンポーネントへと置き換えることに成功しています。 独自の「コンティニュアント(Continuants)」を用いた計算手法を導入することで、連分数計算のボトルネックであった除算回数を劇的に削減し、学習および推論の効率を飛躍的に向上させました。これにより、計算リソースの消費を抑えつつ、高度な言語生成能力を維持することが可能になります。 GPT2-xlやLlama3を用いた大規模な実験の結果、元のモデルの半分から3分の2程度のパラメータ数でありながら、分類、質疑応答、推論などの多様なタスクにおいて、標準的なTransformerと同等以上の性能をより短い学習時間で達成できることを実証しました。
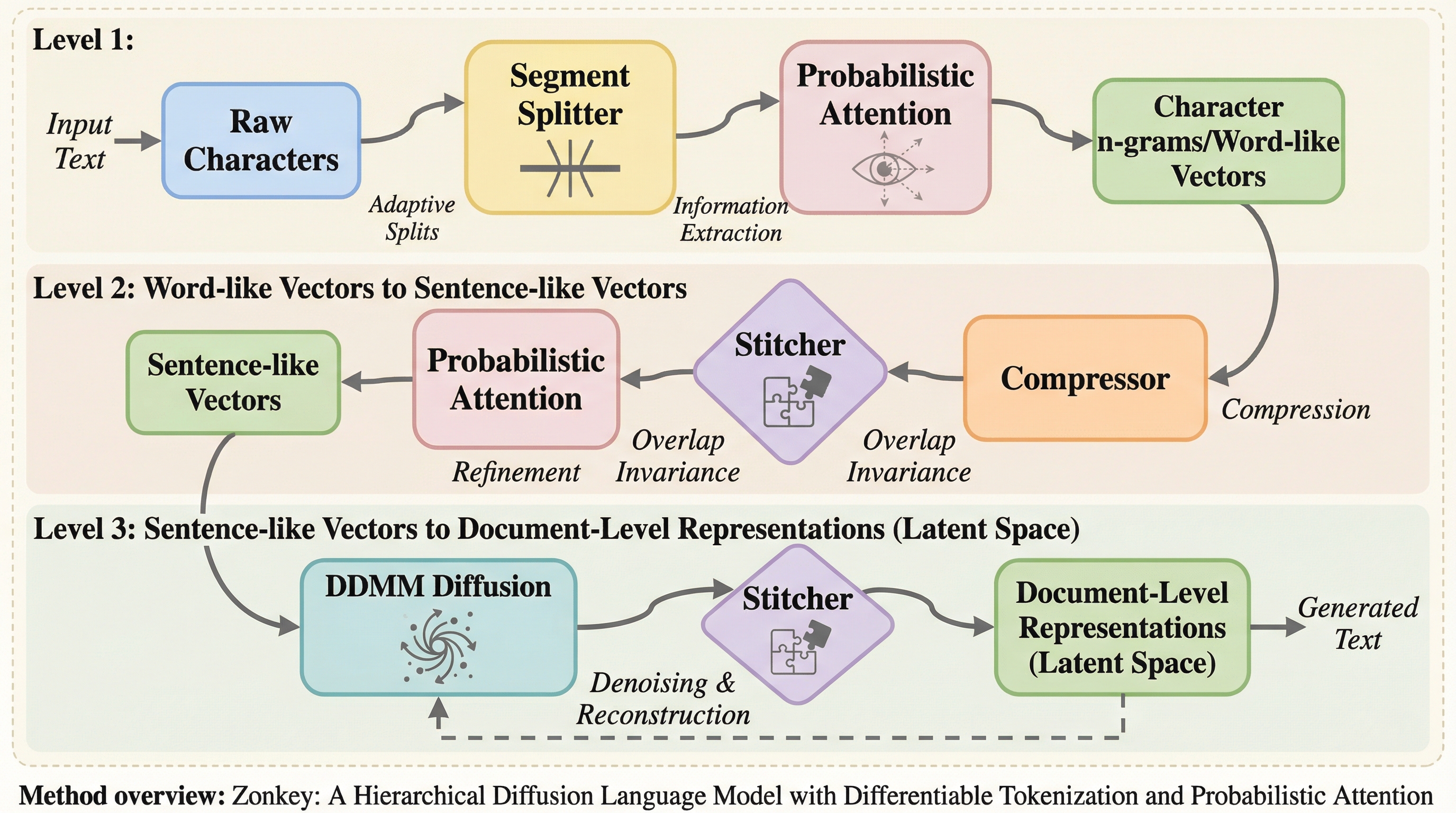
従来の言語モデルが抱えていた「固定された非微分的なトークナイザー」という制約を根本から解消するため、生の文字から文書レベルの表現までを完全に学習可能な階層型拡散モデル「Zonkey」が提案されました。
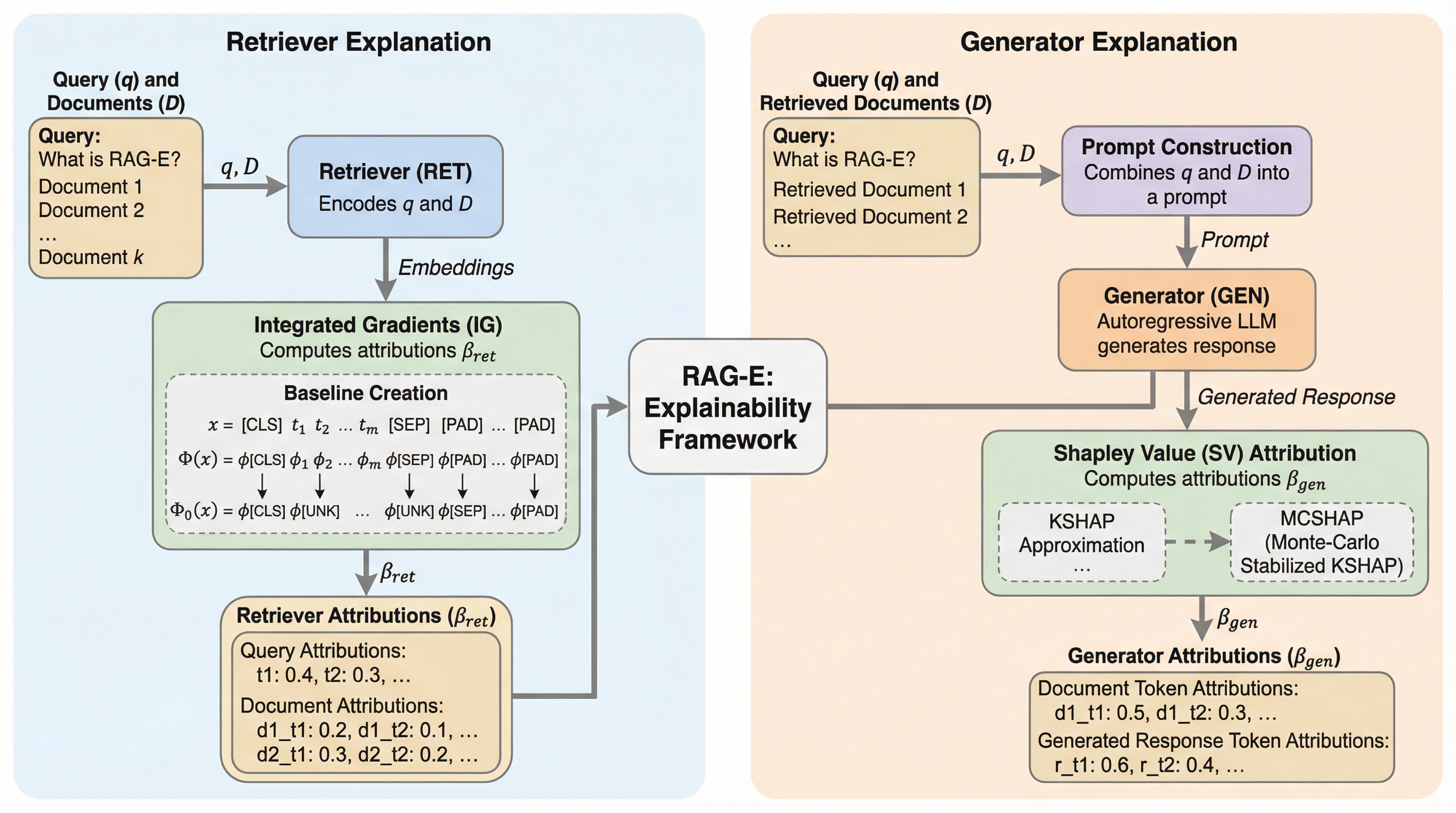
RAG-Eは、検索拡張生成(RAG)における検索器と生成器の相互作用を数学的に定量化し、システム全体の透明性を向上させるエンドツーエンドの説明可能性フレームワークである。検索器にはIntegrated Gradientsを、生成器にはモンテカルロ法で安定化させたPMCSHAPを適用し、情報の流れを可視化するとともに、検索順位と実際の利用度の乖離を測定する新指標「WARG」を導入した。実証分析の結果、生成器が上位文書を無視したり下位文書に過度に依存したりする深刻な不整合が最大66.7%の割合で確認され、RAGの品質は個々の性能ではなく両者の「整合性」に依存することが判明した。このフレームワークにより、医療や法律といった高い信頼性が求められる分野において、モデルがどの情報を根拠に回答したかを詳細に監査することが可能となり、計算コストの削減やプロンプト設計の最適化に寄与する。