Zonkey:微分可能なトークン化と確率的アテンションを備えた階層的拡散言語モデル
従来の言語モデルが抱えていた「固定された非微分的なトークナイザー」という制約を根本から解消するため、生の文字から文書レベルの表現までを完全に学習可能な階層型拡散モデル「Zonkey」が提案されました。
TL;DR(結論)
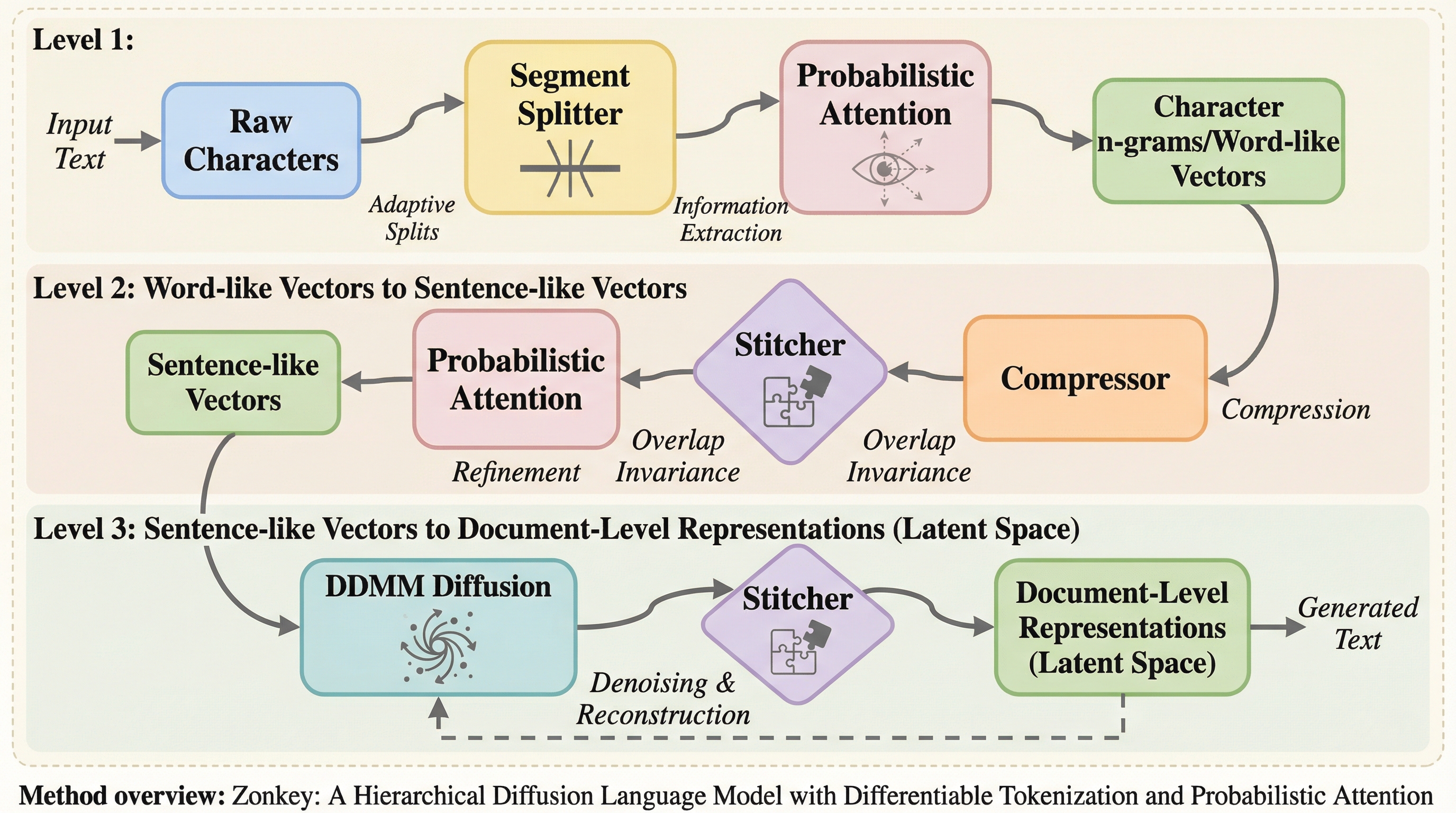
従来の言語モデルが抱えていた「固定された非微分的なトークナイザー」という制約を根本から解消するため、生の文字から文書レベルの表現までを完全に学習可能な階層型拡散モデル「Zonkey」が提案されました。このモデルは、確率的な判断に基づき単語や文の境界を自律的に学習する「Segment Splitter」と、可変長の系列を微分可能な形で扱う「Probabilistic Attention」を中核として構成されています。 Wikipediaを用いた学習の結果、明示的な教師なしで言語的な階層構造が創発し、ノイズから一貫性のあるテキストを生成できることが確認されました。これにより、特定のルールに縛られず、データの背後にある構造を直接勾配法で最適化できる次世代の言語モデルへの道が示されました。 この手法は、未知語(OOV)への耐性やドメイン適応能力において従来のモデルを凌駕する可能性を秘めており、文字レベルから高度な抽象概念までをシームレスにつなぐ新しいフレームワークとして、自然言語処理の柔軟性を大きく拡張するものです。
なぜこの問題か
現在の大規模言語モデル(LLM)は目覚ましい発展を遂げていますが、その基盤となるトークナイザーには依然として大きな課題が残されています。Byte Pair Encoding(BPE)に代表される既存のトークナイザーは、事前に定義された固定のルールに基づいてテキストを分割するため、学習プロセスの中で最適化することができない「非微分的」な存在です。この剛直な仕組みは、未知語(OOV)への対応を困難にするだけでなく、スペルミスやノイズの多いテキスト、あるいは専門性の高いドメインのデータに対して、モデルが柔軟に適応することを妨げる要因となっています。また、既存の階層型モデルにおいても、文字のような低レベルの情報を単語や文といった高レベルの抽象概念に集約する際、固定長を前提とした処理が行われることが多く、これが言語本来の柔軟な構造を捉える上での障壁となっていました。 拡散モデルをテキスト生成に応用する試みも進んでいますが、離散的なトークンの扱いや、ノイズによる意味の歪み、そして固定された出力長といった制約が、画像生成のような高い成果を出す上での大きな壁となっていました。…
核心:何を提案したのか
本論文では、生の文字から文書レベルの表現までを完全に学習可能なパイプラインで構築する階層型拡散モデル「Zonkey」を提案しています。このモデルの最大の特徴は、微分可能なトークナイザーとして機能する「Segment Splitter」と、新しいアテンション機構である「Probabilistic Attention」を導入した点にあります。これらは、従来のハードな境界設定を排除し、すべてを確率的な「ソフト」な処理に置き換えることで、勾配による最適化を可能にしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related