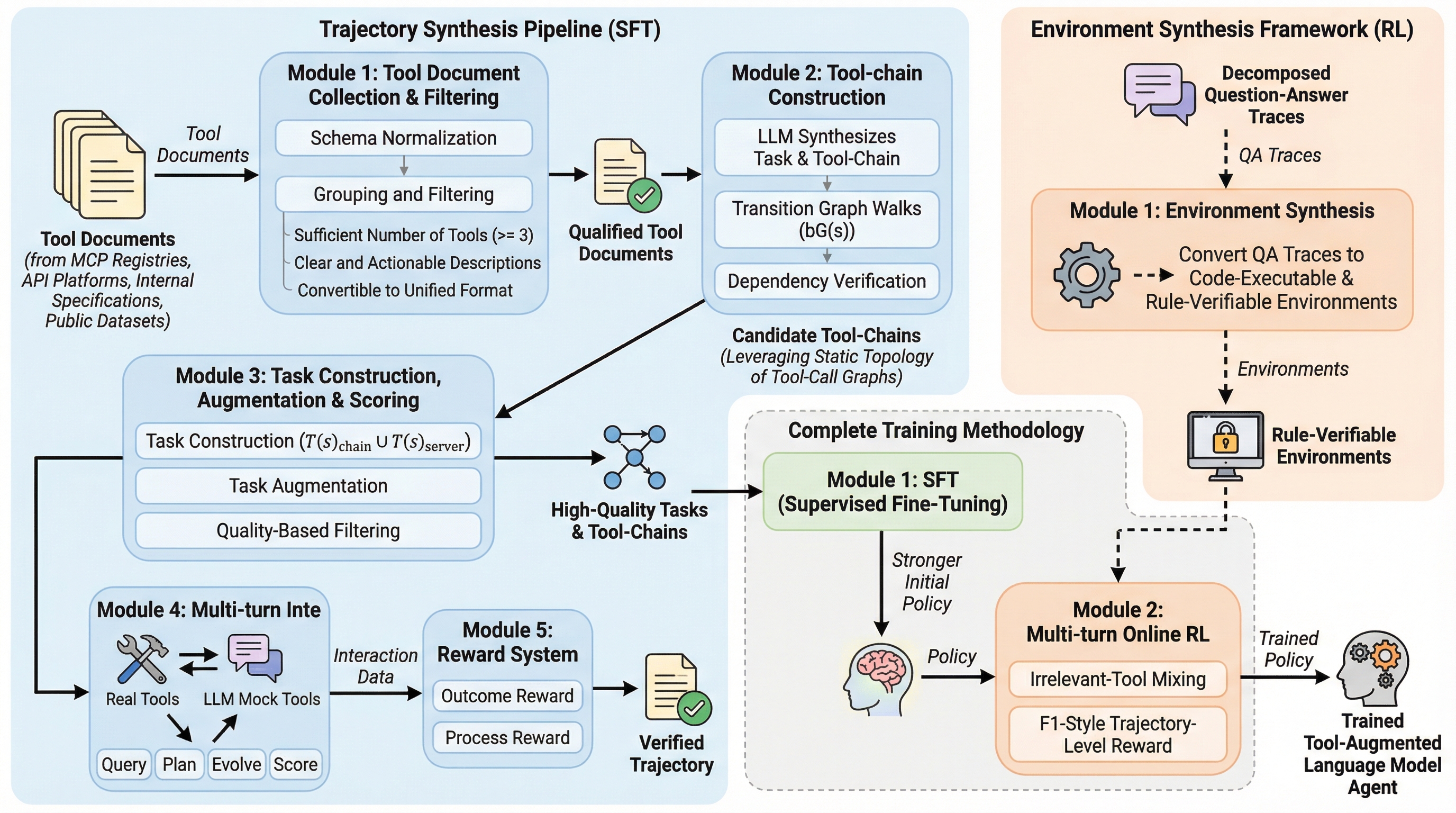
ASTRA:エージェント的軌跡と強化学習アリーナの自動合成
ASTRAは、ツール利用エージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成と検証可能な強化学習を統合することで、従来の手動介入や不確実なシミュレーション環境への依存を排除している。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ASTRAは、ツール利用エージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成と検証可能な強化学習を統合することで、従来の手動介入や不確実なシミュレーション環境への依存を排除している。
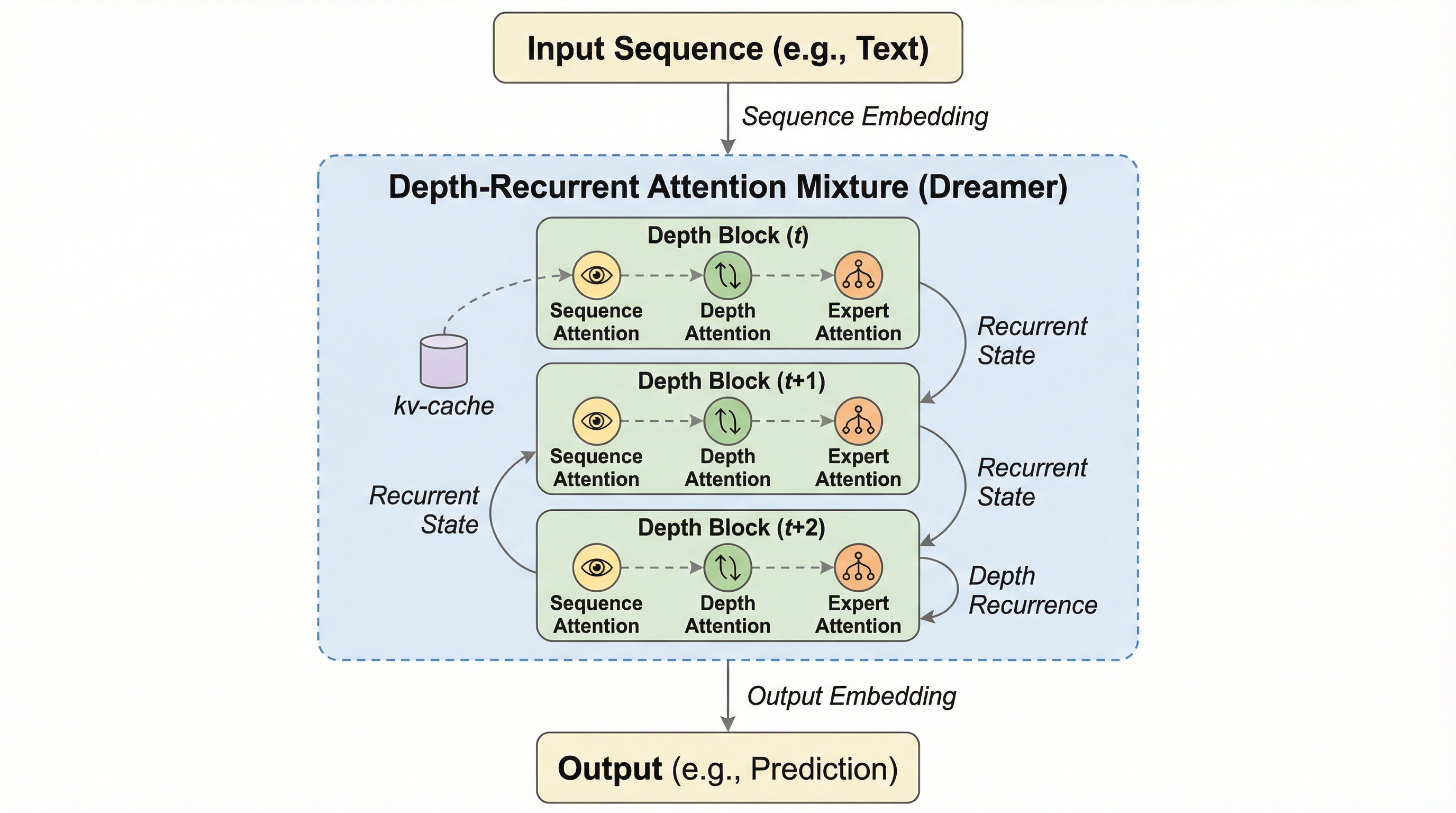
従来の思考連鎖(CoT)が抱える離散的な言語化の制約と計算コストの問題を、深層再帰とアテンション混合を統合した「Dreamer」フレームワークによって、潜在空間での効率的な多段階推論へと転換し、モデルの表現力を大幅に向上させた。
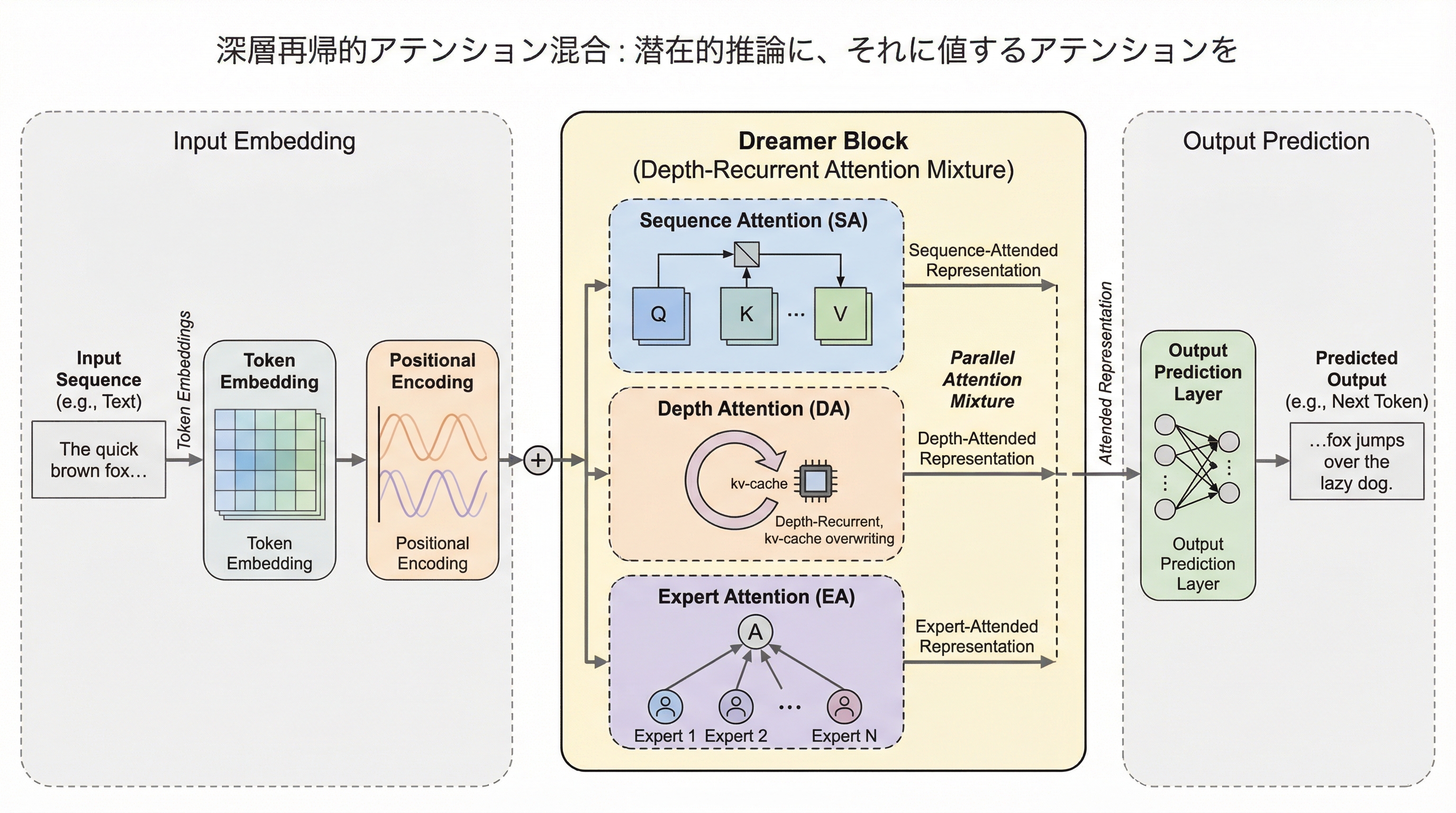
従来の思考の連鎖(CoT)は自然言語による冗長な出力を必要とし、計算コストが高いという課題があったが、本研究ではモデルの深さ方向で再帰的に計算を行う「深層再帰(DR)」を用いることで、潜在空間内での効率的な推論を実現する新しいフレームワーク「Dreamer」を提案している。
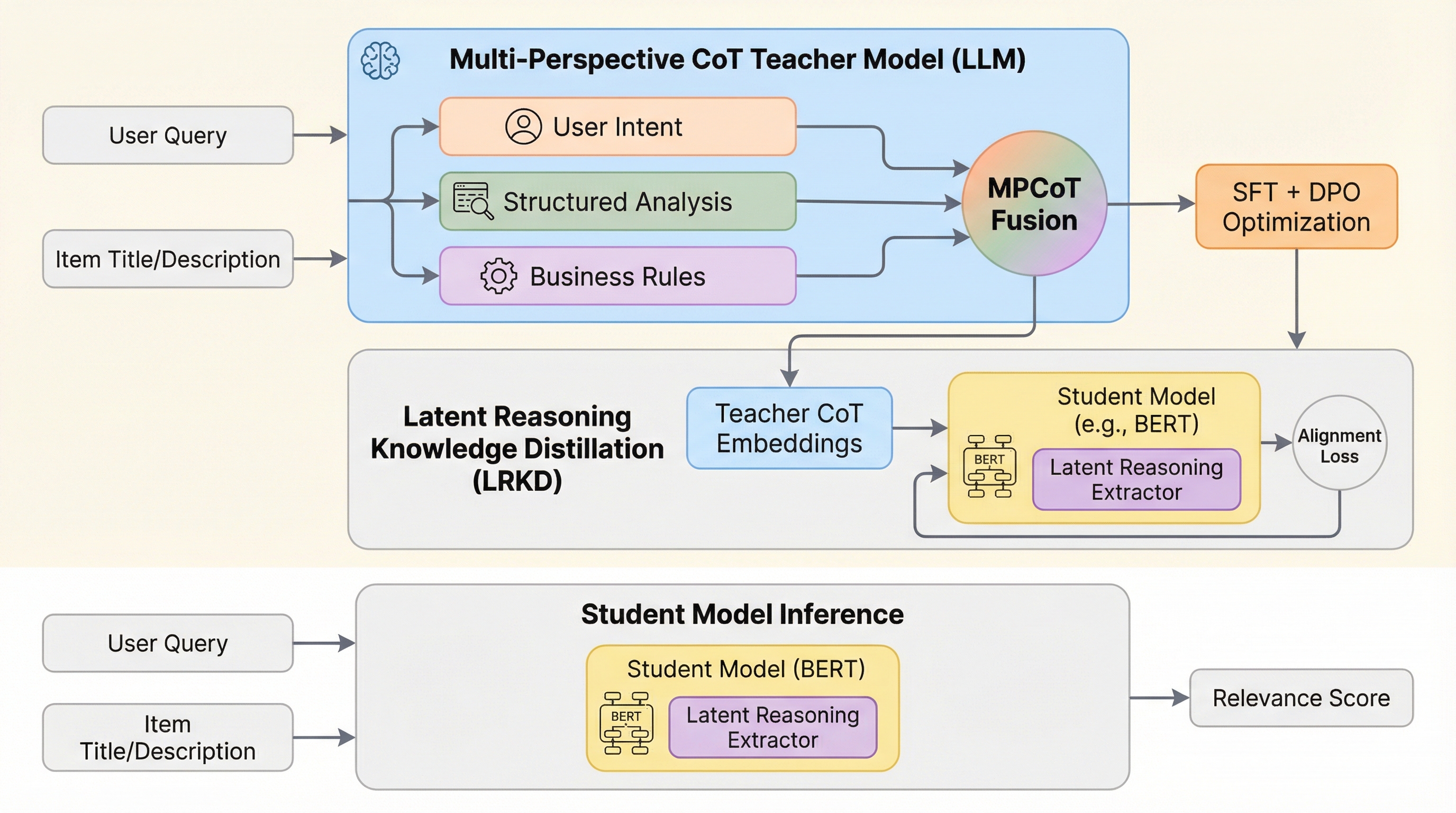
ECサイトの検索における検索語と商品の関連性判定を劇的に改善するため、大規模言語モデル(LLM)に「ユーザー意図」「構造的分析」「ビジネスルール」という3つの異なる視点から思考の連鎖(CoT)を行わせる「MPCoT」フレームワークを開発しました。
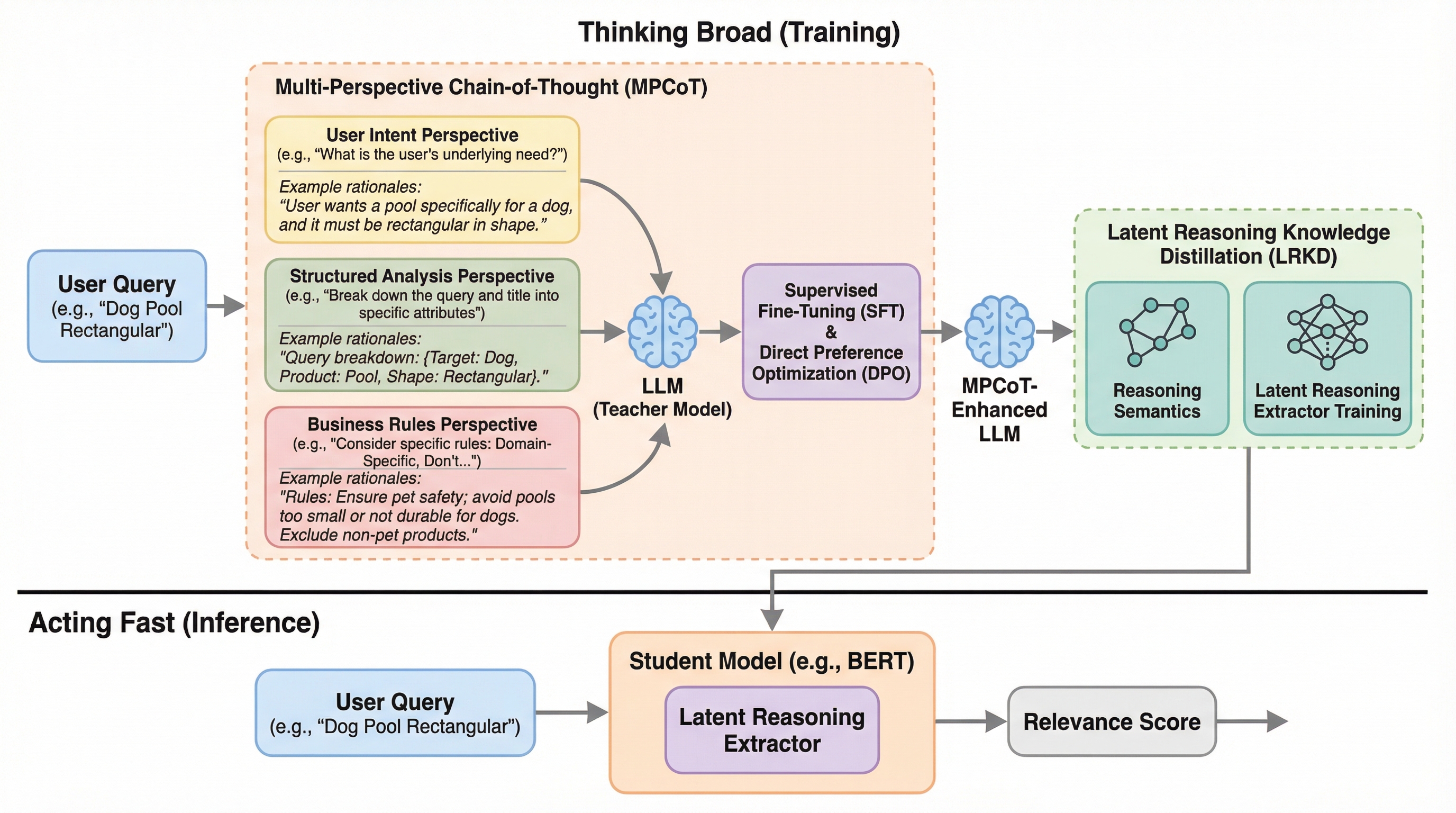
電子商取引(EC)における検索の関連性評価を劇的に向上させるため、大規模言語モデル(LLM)の高度な思考プロセスを軽量モデルに継承させる新しい学習フレームワークが提案されました。この手法では、単一の視点に頼る従来の思考の連鎖(CoT)の限界を克服するため、ユーザーの意図、商品の構造的分析、プラットフォーム固有のビジネスルールという三つの異なる視点から推論を行う「多角的思考の連鎖(MPCoT)」を導入しています。これにより、複雑なクエリや曖昧な検索ワードに対しても、人間のような深い理解に基づいた正確な判断が可能になりました。さらに、この高度な推論能力を「潜在推論知識蒸留(LRKD)」という技術を用いて、BERTなどの小型モデルに「潜在的な推論ベクトル」として移植することで、推論時の計算コストを抑えつつLLMに匹敵する精度を実現しています。実際のオンラインA/Bテストでは、数千万人のユーザーを抱える広告プラットフォームにおいて、収益指標であるRPMが1.42%向上し、クリック率やユーザー満足度も有意に改善するなど、実用性と商業的価値の両面で極めて高い成果が実証されました。
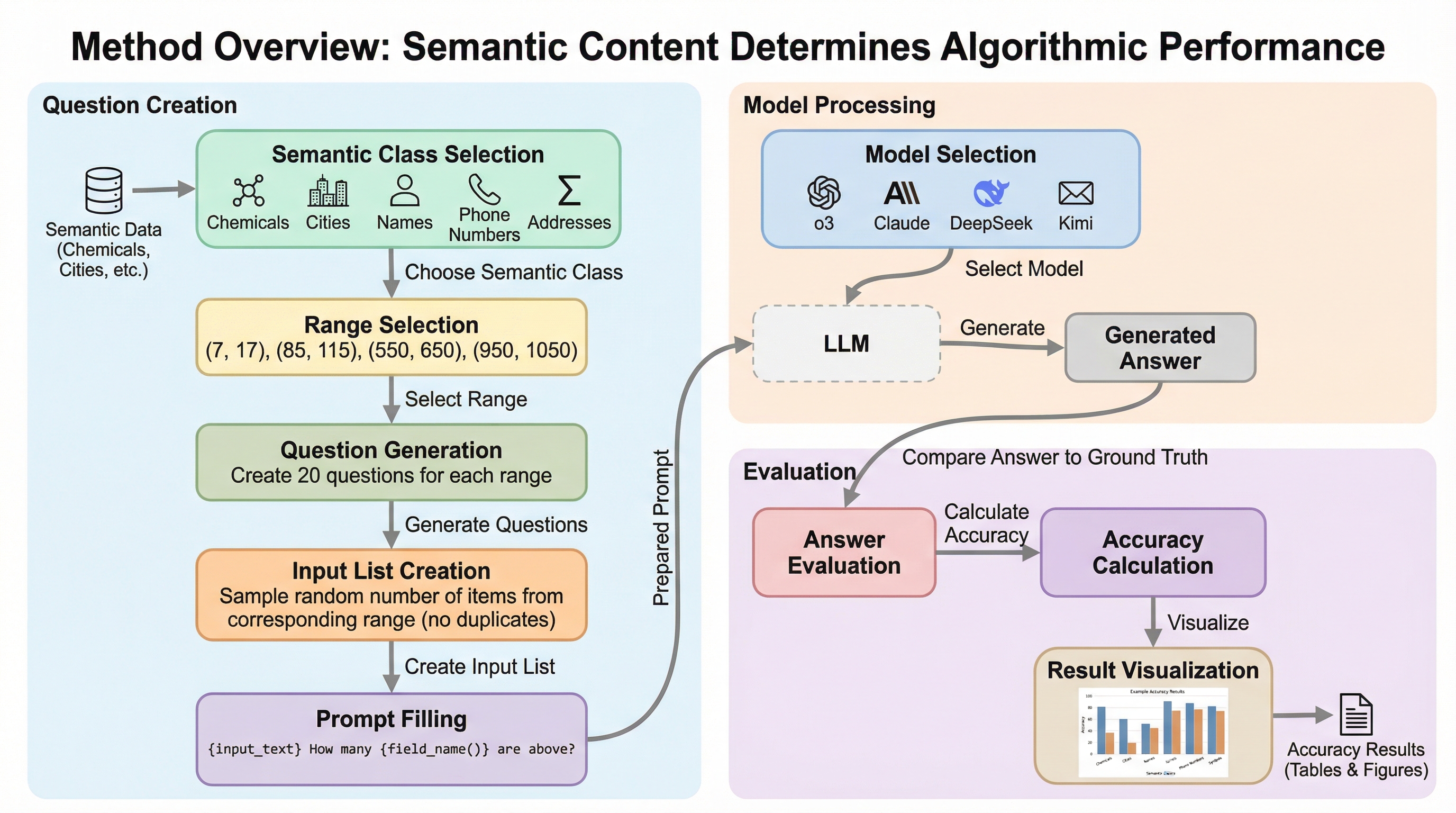
大規模言語モデル(LLM)は、本来入力の意味に左右されないはずの「計数(カウント)」という基本的なアルゴリズムにおいて、対象が「都市名」か「化学物質名」かといった意味内容によって正解率が40%以上も変動するという深刻な脆弱性を抱えていることが判明しました。
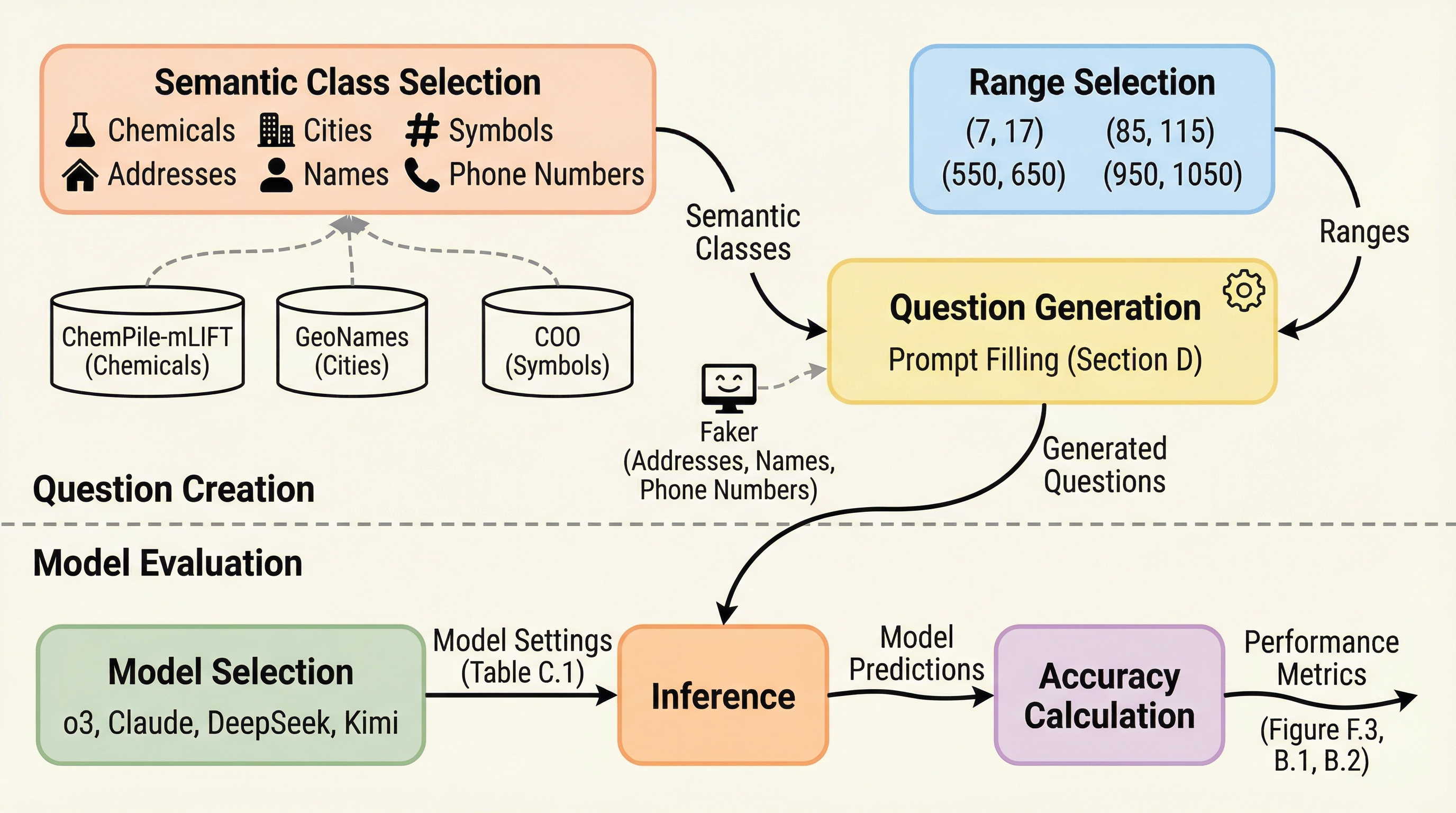
大規模言語モデル(LLM)は、本来なら入力の意味に左右されないはずの計数のようなアルゴリズム的タスクにおいて、対象が「都市名」か「化学物質名」かといった意味的内容(セマンティック・クラス)によって正解率が40%以上も変動するという重大な脆弱性を持っていることが明らかになった。
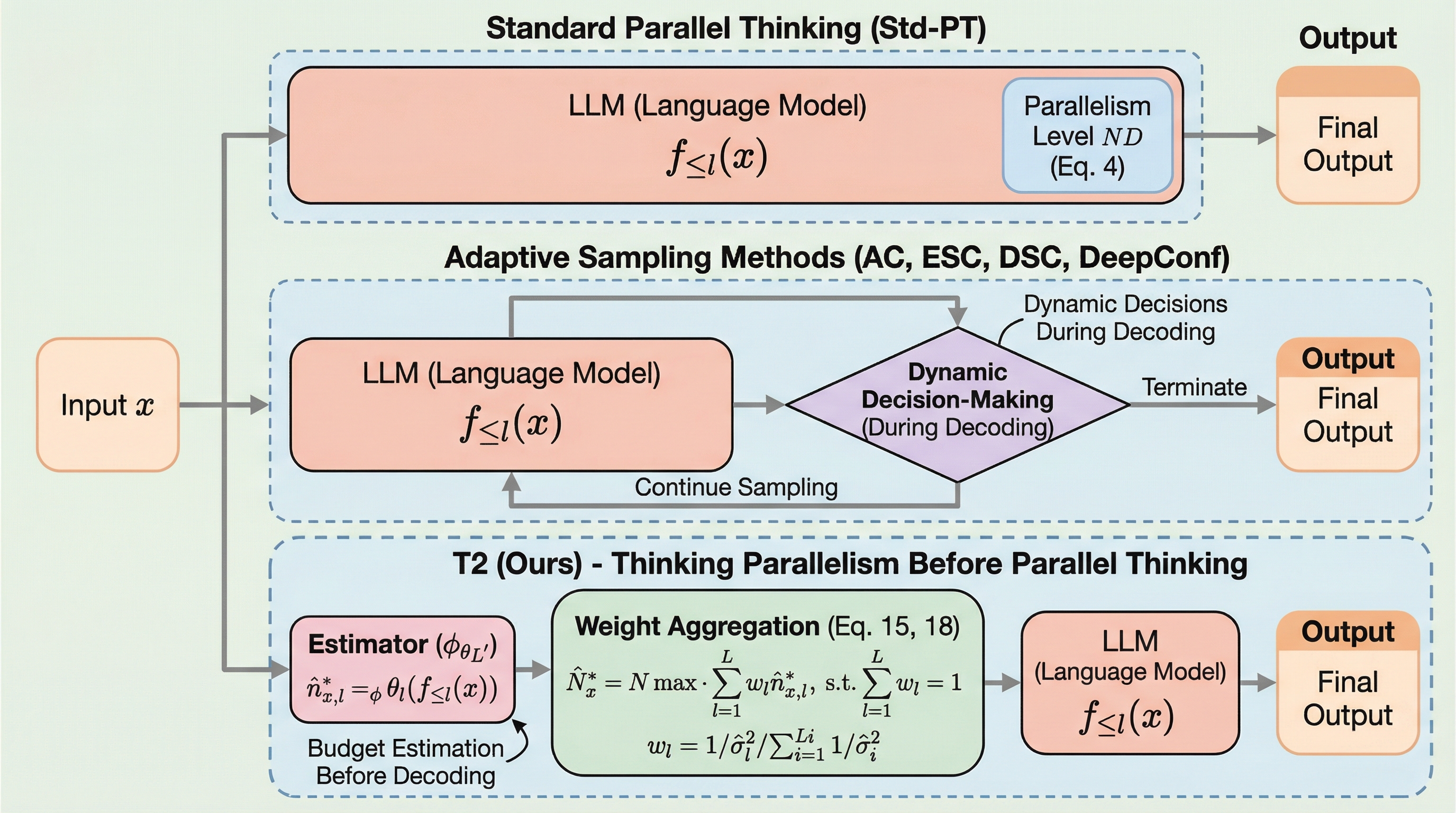
大規模言語モデル(LLM)の推論において、複数の推論パスを並列生成して多数決で統合する「並列思考」は有効ですが、全データに一律の大規模な並列数(予算)を割り当てると、多くのサンプルで計算資源が無駄になる「オーバースケーリングの呪い」が発生します。
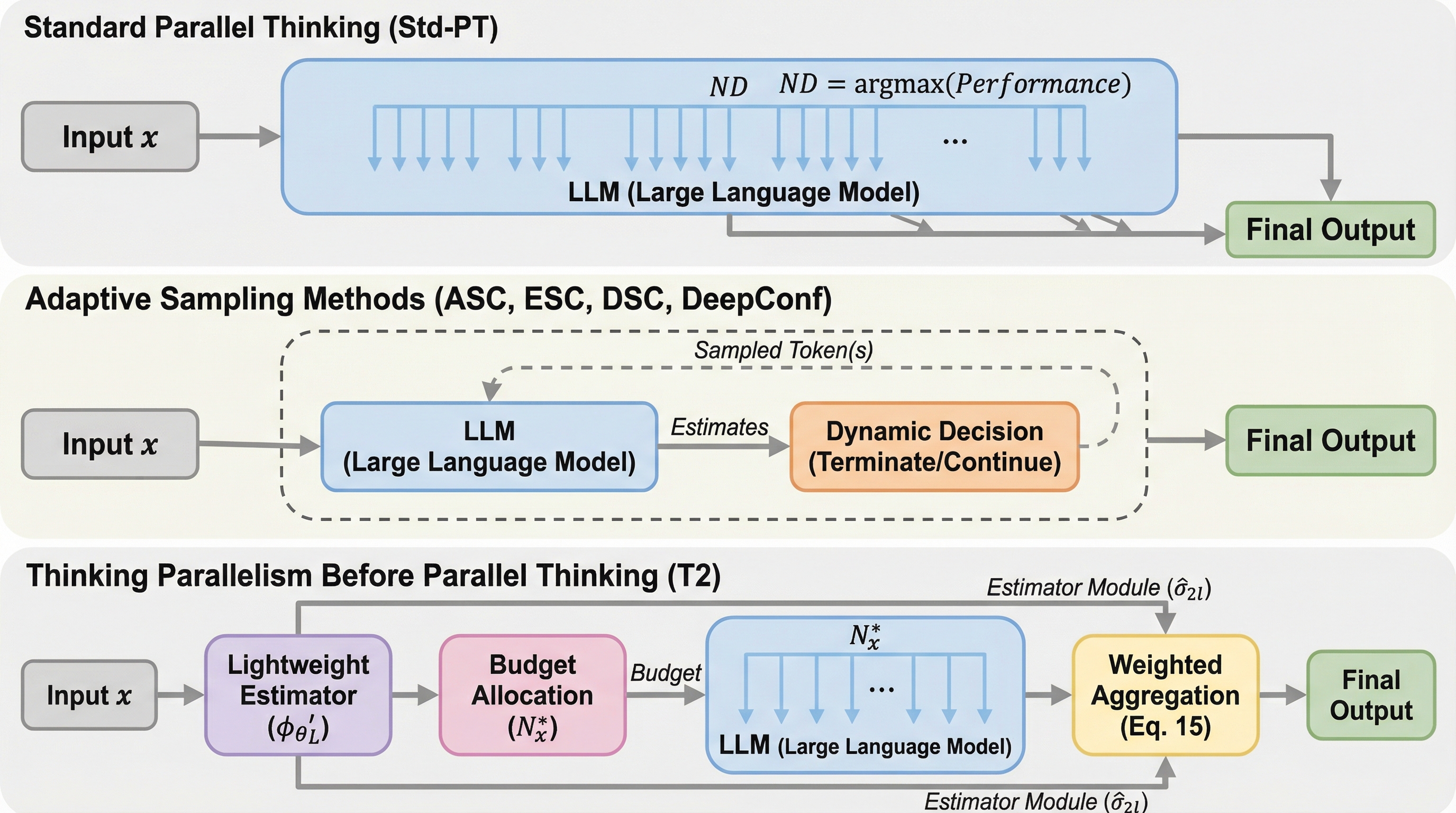
大規模言語モデルの推論において、複数の回答を生成して統合する「並列的思考」は精度を向上させますが、全問題に一律の大きな並列度を割り当てると、簡単な問題などで計算資源が無駄になる「オーバースケーリングの呪い」が発生することを明らかにしました。
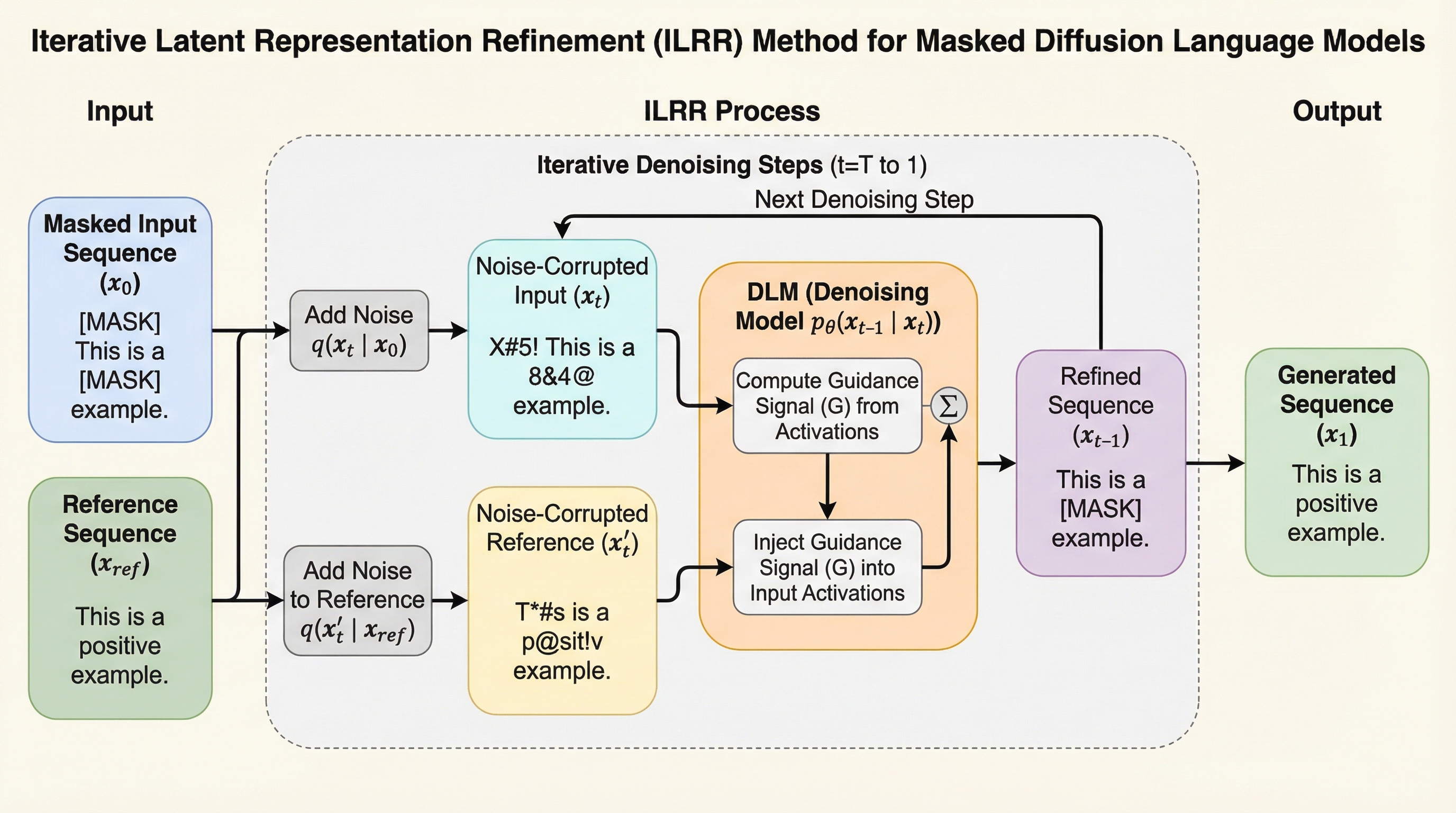
離散拡散言語モデル(DLM)の生成プロセスを推論時に制御するための、学習を必要としない新しいフレームワーク「反復的潜在表現洗練(ILRR)」が提案されました。この手法は、生成中のシーケンスの内部活性化状態を、単一の参照シーケンスの活性化状態と動的に位置合わせすることで、特定の属性やスタイルを効果的に転送します。