深層再帰アテンション混合:潜在的推論にふさわしい注目を
従来の思考連鎖(CoT)が抱える離散的な言語化の制約と計算コストの問題を、深層再帰とアテンション混合を統合した「Dreamer」フレームワークによって、潜在空間での効率的な多段階推論へと転換し、モデルの表現力を大幅に向上させた。
TL;DR(結論)
従来の思考連鎖(CoT)が抱える離散的な言語化の制約と計算コストの問題を、深層再帰とアテンション混合を統合した「Dreamer」フレームワークによって、潜在空間での効率的な多段階推論へと転換し、モデルの表現力を大幅に向上させた。 シーケンス、深さ、エキスパートという3つの直交する次元を統一的なアテンション形式で扱うことで、従来の再帰構造における隠れ状態のサイズ制限を克服し、パラメータ数を維持したまま深さ方向へのスケーリングと知識の再利用を可能にした。 厳密なリソース調整下での検証により、既存の最先端モデルと同等の精度を達成するために必要な学習トークン数を最大8倍削減し、同規模のモデルを凌駕する性能と、最大11倍に達するエキスパート選択の多様性を実現することに成功した。
なぜこの問題か
現代の人工知能において、推論能力を備えた言語モデルは極めて重要な役割を担っている。特に思考連鎖(CoT)は、テスト時の計算量を増大させることで複雑な問題を解決する有力な手法として広く普及している。しかし、従来の思考連鎖には大きな課題が存在する。それは、推論過程を自然言語という離散的な形式で出力しなければならないという制約である。この言語化の強制は、モデルの内部的な表現力を制限するだけでなく、生成や学習において計算コストが非常に高い長いシーケンスを生み出す原因となっている。 この問題に対する潜在的な解決策として、深層再帰(DR)を用いた潜在空間での推論が注目されている。深層再帰は、層の間でパラメータを共有することで、モデルのパラメータ数を増やすことなく計算の深さをスケールさせることができる。これにより、連続的な空間での多段階推論が可能になり、自然言語の枠を超えた効率的な推論が期待される。しかし、深層再帰を大規模にスケールさせるには、二つの大きなボトルネックが立ちはだかっていた。 第一の課題は「層サイズ」のボトルネックである。…
核心:何を提案したのか
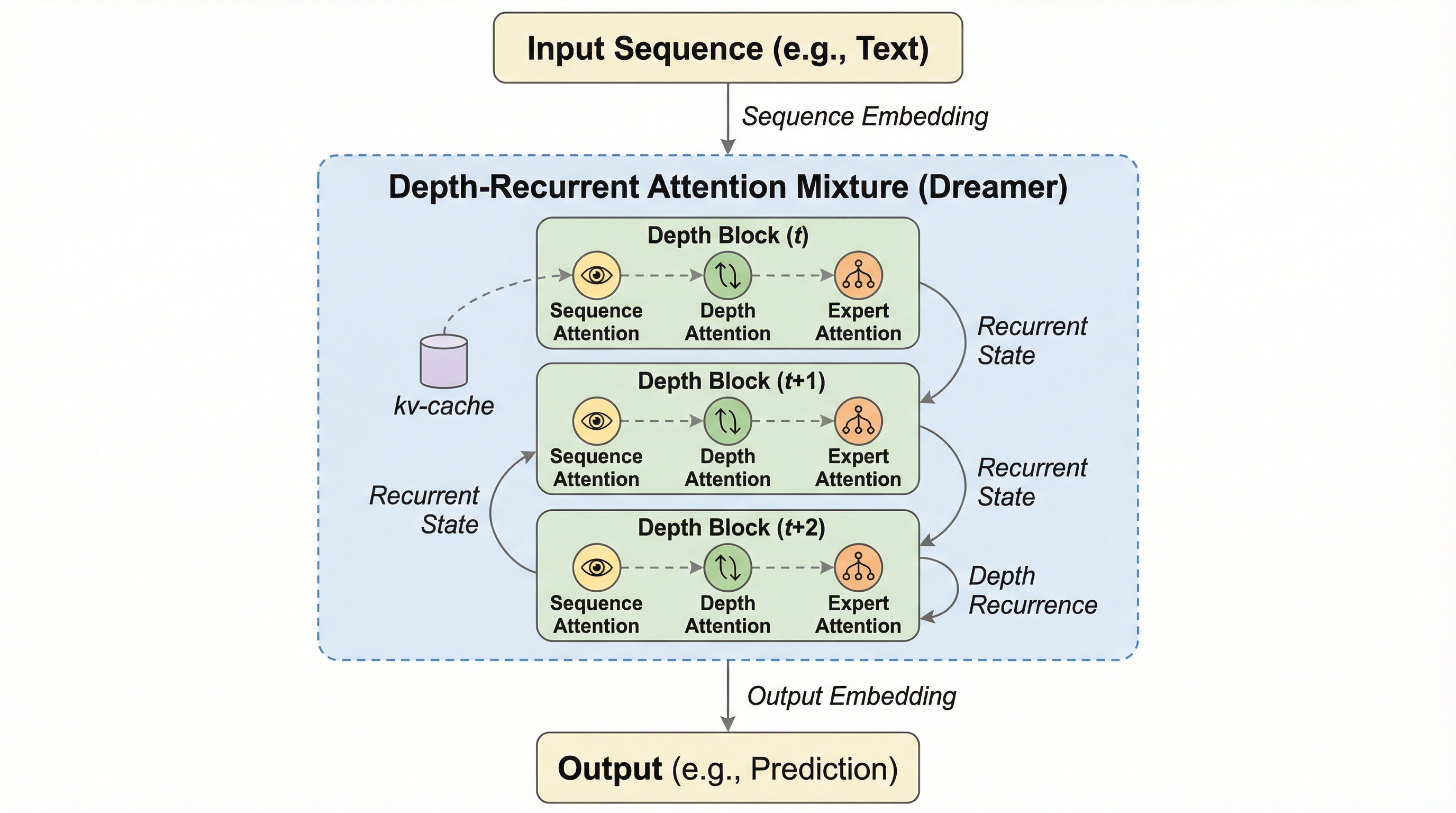
本研究では、深層再帰アテンション混合(Dreamer)と呼ばれるモジュール式のフレームワークを提案している。このフレームワークの核心は、シーケンス、深さ、そしてエキスパートという、モデルの知識アクセスにおける主要な三つの次元を、統一的なアテンション形式で統合した点にある。これにより、モデルは情報の時間的なつながり、推論の深さ、そして専門的な知識ベースの三方向に対して、均質かつ効率的なアクセスが可能となった。 Dreamerの最も重要な革新の一つは、「深さアテンション(DA)」の導入である。これは、シーケンス方向のアテンションがRNNのボトルネックを解消したのと同様の原理を、深さ方向の再帰に適用したものである。過去の深さにおける隠れ状態に対してドット積アテンションを行うことで、固定された隠れ状態のサイズに縛られることなく、より複雑で長期的な潜在的推論を支援する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related