意味内容がアルゴリズムの性能を決定する
大規模言語モデル(LLM)は、本来入力の意味に左右されないはずの「計数(カウント)」という基本的なアルゴリズムにおいて、対象が「都市名」か「化学物質名」かといった意味内容によって正解率が40%以上も変動するという深刻な脆弱性を抱えていることが判明しました。
TL;DR(結論)
大規模言語モデル(LLM)は、本来入力の意味に左右されないはずの「計数(カウント)」という基本的なアルゴリズムにおいて、対象が「都市名」か「化学物質名」かといった意味内容によって正解率が40%以上も変動するという深刻な脆弱性を抱えていることが判明しました。 新しく提案されたベンチマーク「WhatCounts」を用いた検証により、最先端モデルであるo3やClaude、DeepSeekなどは、アルゴリズムを厳密に実行しているのではなく、入力の意味内容に依存した近似的なパターンマッチングを行っているに過ぎないことが浮き彫りになりました。 この「意味のギャップ」は、トークン数や区切り文字の認識といった構造的な要因では説明できず、さらに関係のないデータの微調整(ファインチューニング)によって失敗の傾向が予測不能に変化するため、AIエージェントなどの複雑なシステムにおける信頼性を根本から揺るがすリスクとなります。
なぜこの問題か
アルゴリズムの定義とは、入力の構造に基づいて動作するものであり、その引数が持つ「意味」には依存しないはずのものです。例えば、10個の要素を数えるという操作は、対象が都市の名前であっても、化学物質の名称であっても、あるいは絵文字であっても、全く同じように機能しなければなりません。この「不変性」こそが、アルゴリズムをアルゴリズムたらしめる本質的な性質です。しかし、近年のLLMは、計数、ソート、検索といったアルゴリズム的な操作を実行できるかのように見え、「プロンプト・プログラミング」の時代が到来したとも言われています。 開発者は、LLMをパイプラインやエージェントの構成要素として組み込む際、これらの低レベルな操作がドメインを問わず予測可能に動作することを前提としています。もし、これらの基本的な操作が入力の意味内容によって体系的に失敗するのであれば、その脆弱性はシステム全体に伝播し、最終的な出力の信頼性を著しく損なうことになります。…
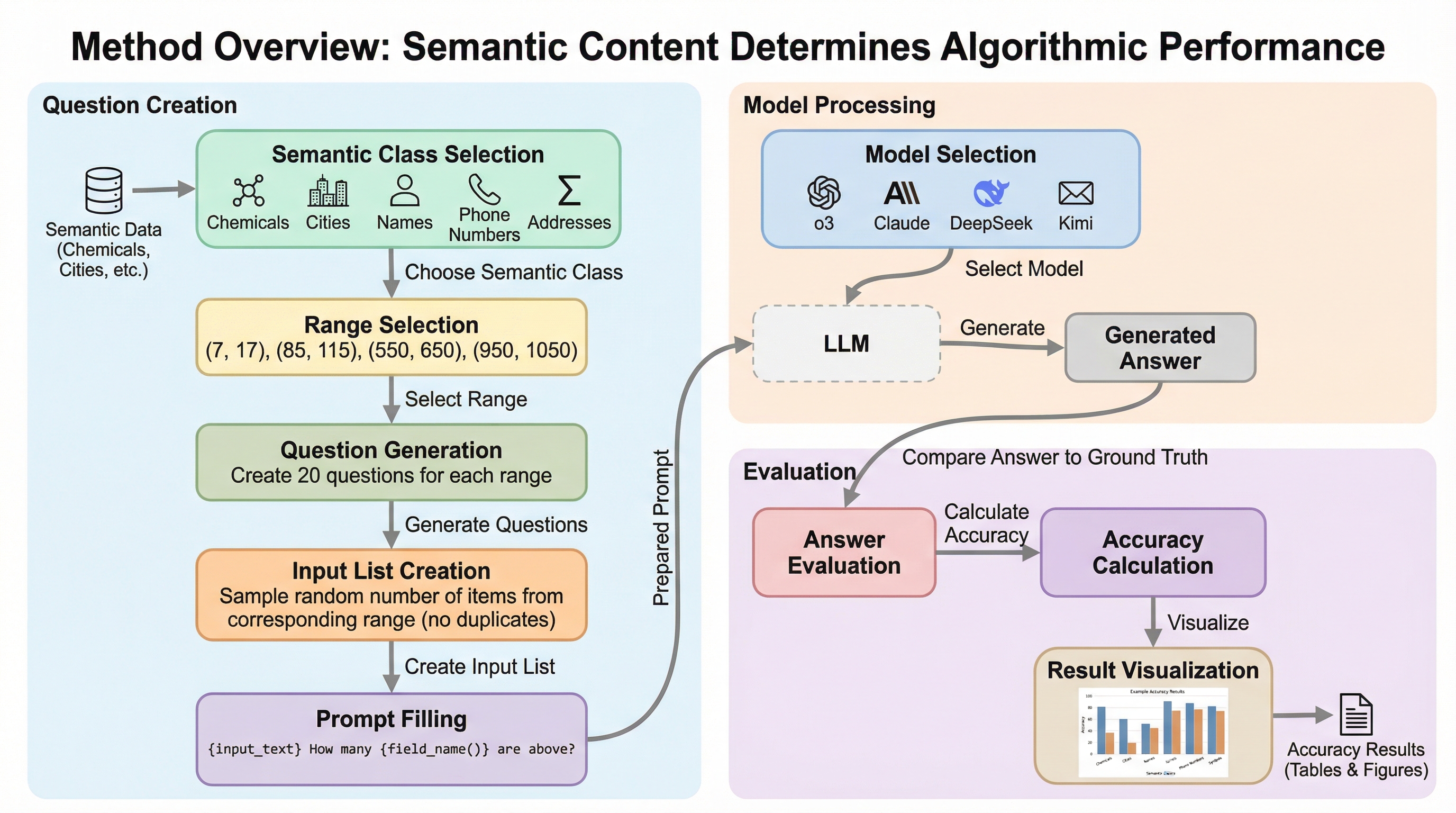
核心:何を提案したのか
著者らは、意味内容による不変性を単独でテストするための最小限のベンチマーク「WhatCounts」を導入しました。このベンチマークの最大の特徴は、推論の複雑さやプロンプトのバリエーションといった混同要因を排除し、純粋に「意味内容」の影響だけを測定できるように設計されている点にあります。具体的には、重複がなく、紛らわしい要素(ディストラクター)も含まれない、明確に区切られたリスト内のアイテムを数えるという、極めて単純かつ原子的なタスクを課します。 検証の対象として、以下の6つの一般的な意味カテゴリ(セマンティック・クラス)が選定されました。 1. 住所(Addresses) 2. 化学物質(Chemicals) 3. 都市名(Cities) 4. 人物のフルネーム(Full names) 5. 電話番号(Phone numbers) 6.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related