深層再帰的アテンション混合:潜在的推論に、それに値するアテンションを
従来の思考の連鎖(CoT)は自然言語による冗長な出力を必要とし、計算コストが高いという課題があったが、本研究ではモデルの深さ方向で再帰的に計算を行う「深層再帰(DR)」を用いることで、潜在空間内での効率的な推論を実現する新しいフレームワーク「Dreamer」を提案している。
TL;DR(結論)
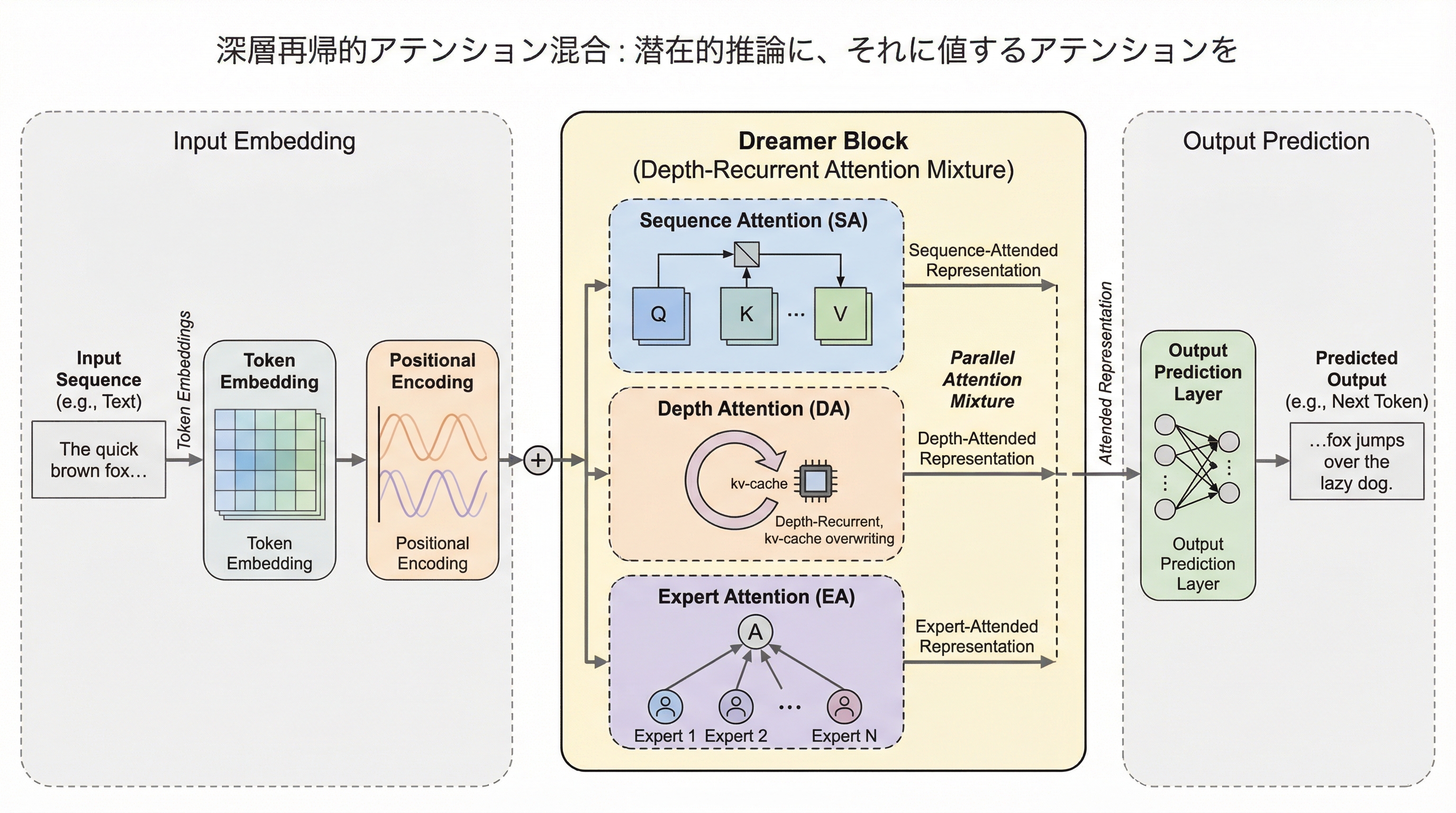
従来の思考の連鎖(CoT)は自然言語による冗長な出力を必要とし、計算コストが高いという課題があったが、本研究ではモデルの深さ方向で再帰的に計算を行う「深層再帰(DR)」を用いることで、潜在空間内での効率的な推論を実現する新しいフレームワーク「Dreamer」を提案している。 Dreamerは、系列アテンション、深さアテンション、そして疎なエキスパート・アテンションを統合したモジュール構造を持ち、特に深さ方向のアテンションを導入することで、従来の再帰モデルで問題となっていた隠れ状態のサイズによる制約(ボトルネック)を解消し、知識の再利用性と構成的な汎化性能を大幅に向上させている。 数学的な推論ベンチマークを用いた検証の結果、提案手法は既存の最先端モデルと比較して、同じ精度に到達するために必要な学習トークン数を2倍から8倍削減することに成功しており、さらに同等の学習リソースを用いた場合には約2倍のパラメータ数を持つ巨大なモデルを上回る高い性能と学習効率を実証している。
なぜこの問題か
現代のAIアプリケーションにおいて、推論能力を持つ言語モデルは不可欠な基盤となっている。複雑な問題を解決するために、テスト時の計算量をスケールさせる「思考の連鎖(CoT)」という手法が広く用いられているが、これには大きな課題が存在する。従来のCoTは、推論過程を自然言語として逐一出力(言語化)する必要があるため、生成される系列が非常に長くなり、結果として計算コストや学習コストが膨大になってしまう。この問題に対し、自然言語を介さずに連続的な潜在空間内で推論を行う「潜在的推論」が注目されている。 潜在的推論を実現する有望なアプローチの一つが、モデルの深さ方向でパラメータを共有して繰り返し計算を行う「深層再帰(DR)」である。深層再帰を用いることで、モデルのパラメータ数を増やすことなく計算の深さをスケールさせることが可能になり、潜在空間内での多段階の推論が実現できる。しかし、これまでの深層再帰モデルには、スケールを阻害する二つの大きなボトルネックが存在していた。 第一のボトルネックは、層のサイズに関するものである。…
核心:何を提案したのか
本研究では、系列アテンション(SA)、深さアテンション(DA)、そして疎なエキスパート・アテンション(EA)を一つのモジュールに統合したフレームワーク「Dreamer(Depth-Recurrent Attention Mixture)」を提案している。このフレームワークは、深さ方向にパラメータを再帰的に利用する構造を持ち、潜在的な推論に対して適切な「アテンション(注目)」を与えることを目的としている。 Dreamerの最大の特徴は、アテンションの概念を複数の次元に拡張し、それらを混合して利用する点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related