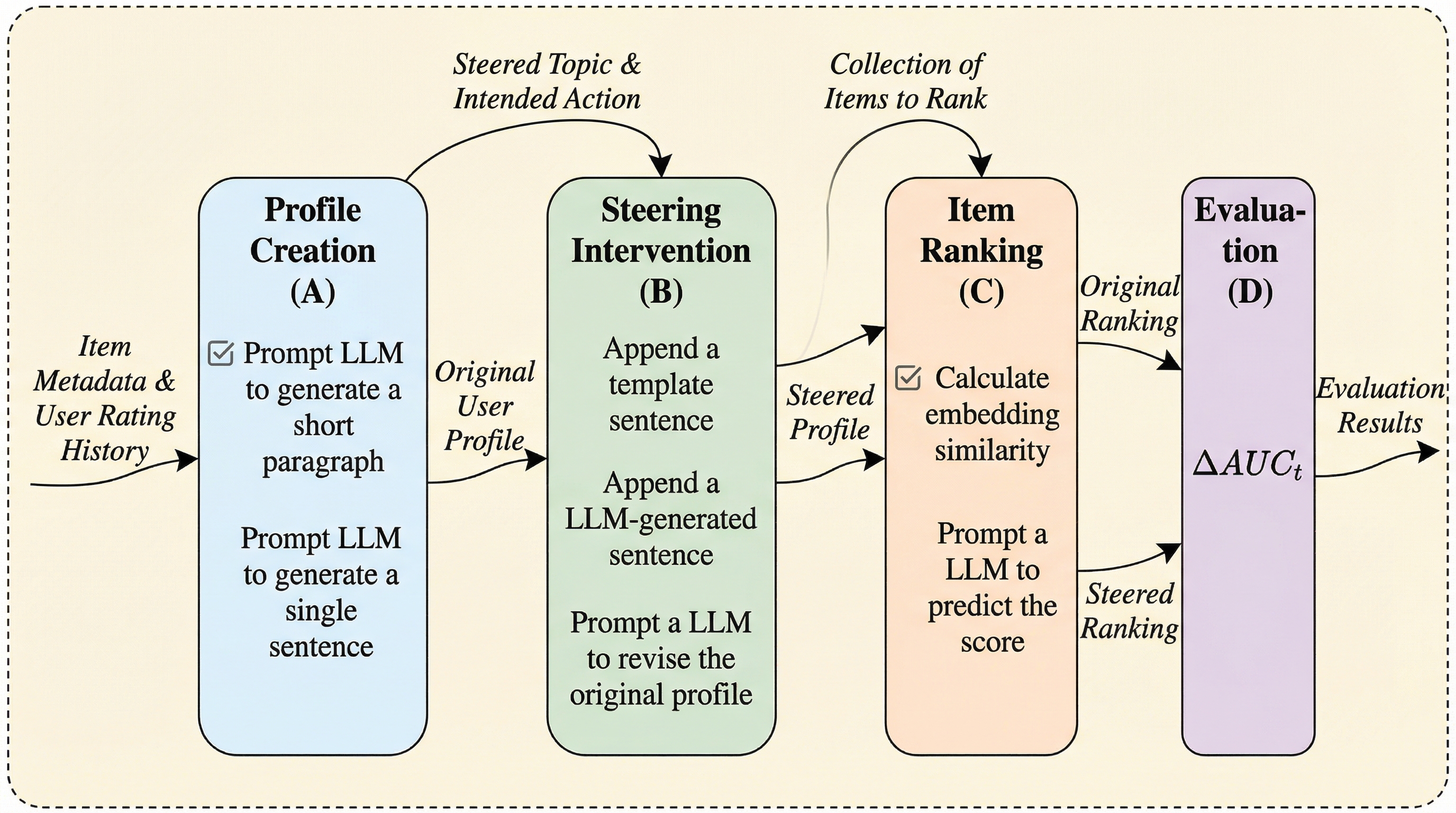
設計から信頼へ:スキルで見える、予算にやさしいLLM選択(BELLA)
「このタスク、どのLLMを使うのが正解?」 高いモデルほど良さそう──でも“何が得意か”が見えないまま、お金だけが溶ける。 この記事では、スキルの粒度でモデルを選び、しかも理由を言葉で説明する枠組み「BELLA」を読み解く。選択の精度だけでなく、選択そのものを信じられる形に整える、という発想に焦点を当てる。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
「このタスク、どのLLMを使うのが正解?」 高いモデルほど良さそう──でも“何が得意か”が見えないまま、お金だけが溶ける。 この記事では、スキルの粒度でモデルを選び、しかも理由を言葉で説明する枠組み「BELLA」を読み解く。選択の精度だけでなく、選択そのものを信じられる形に整える、という発想に焦点を当てる。
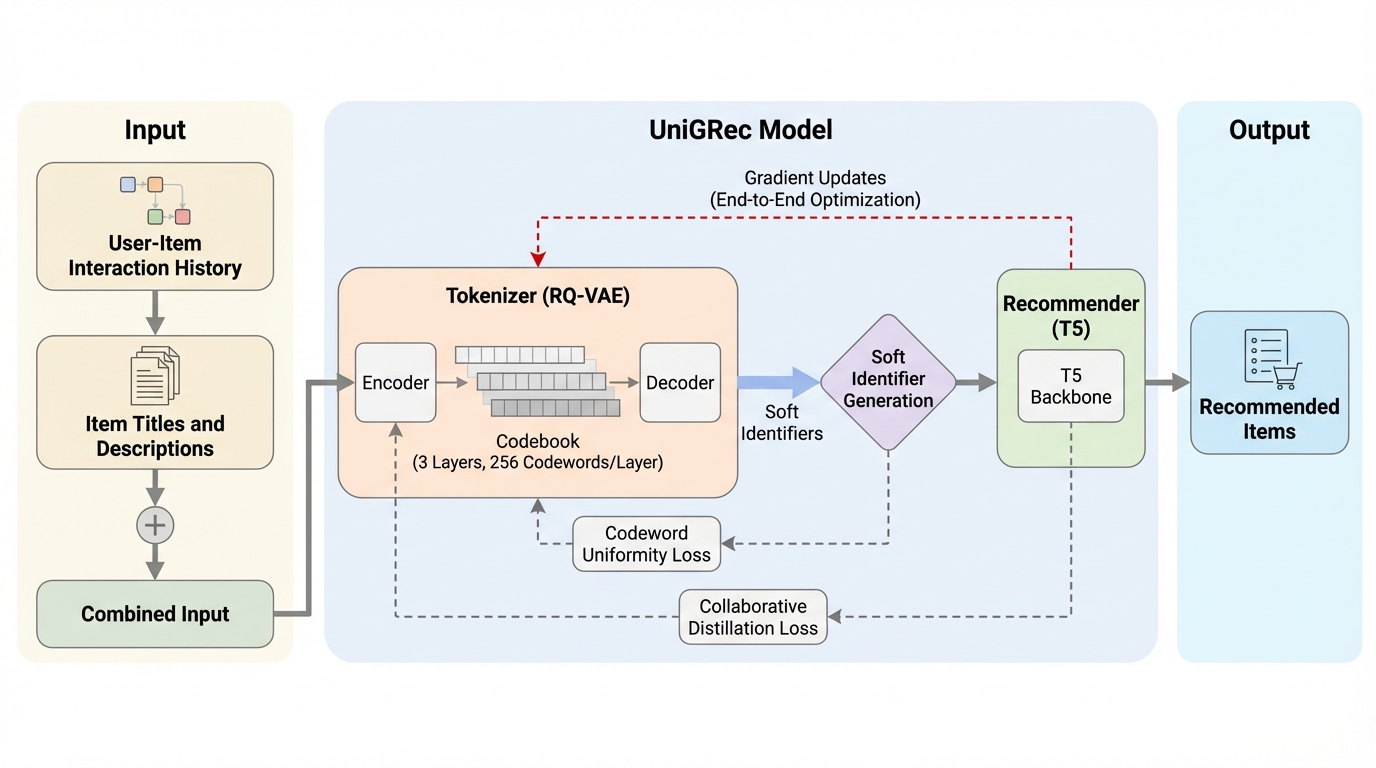
生成型推薦において、従来のトークナイザーと推薦モデルを個別に最適化する手法に対し、微分可能な「ソフト識別子」を導入することで、両者を単一の推薦目的関数でエンドツーエンドに同時最適化する新フレームワーク「UniGRec」が提案された。
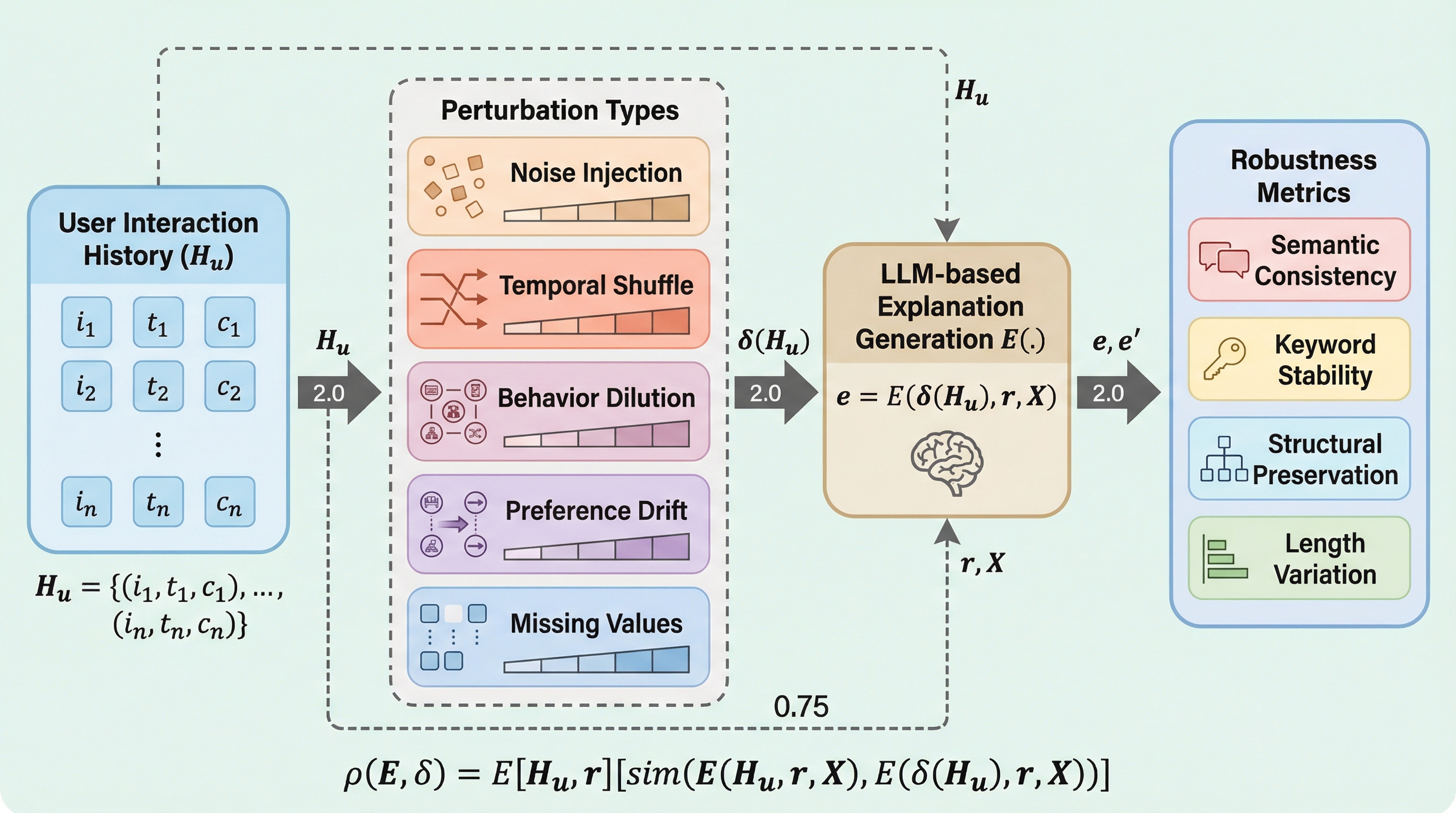
推薦システムにおいてLLMを用いた説明エージェントは、ユーザーの行動履歴から自然言語で推薦理由を生成するが、誤クリックやデータの欠落といった現実的なノイズに対する堅牢性はこれまで十分に検証されていなかった。
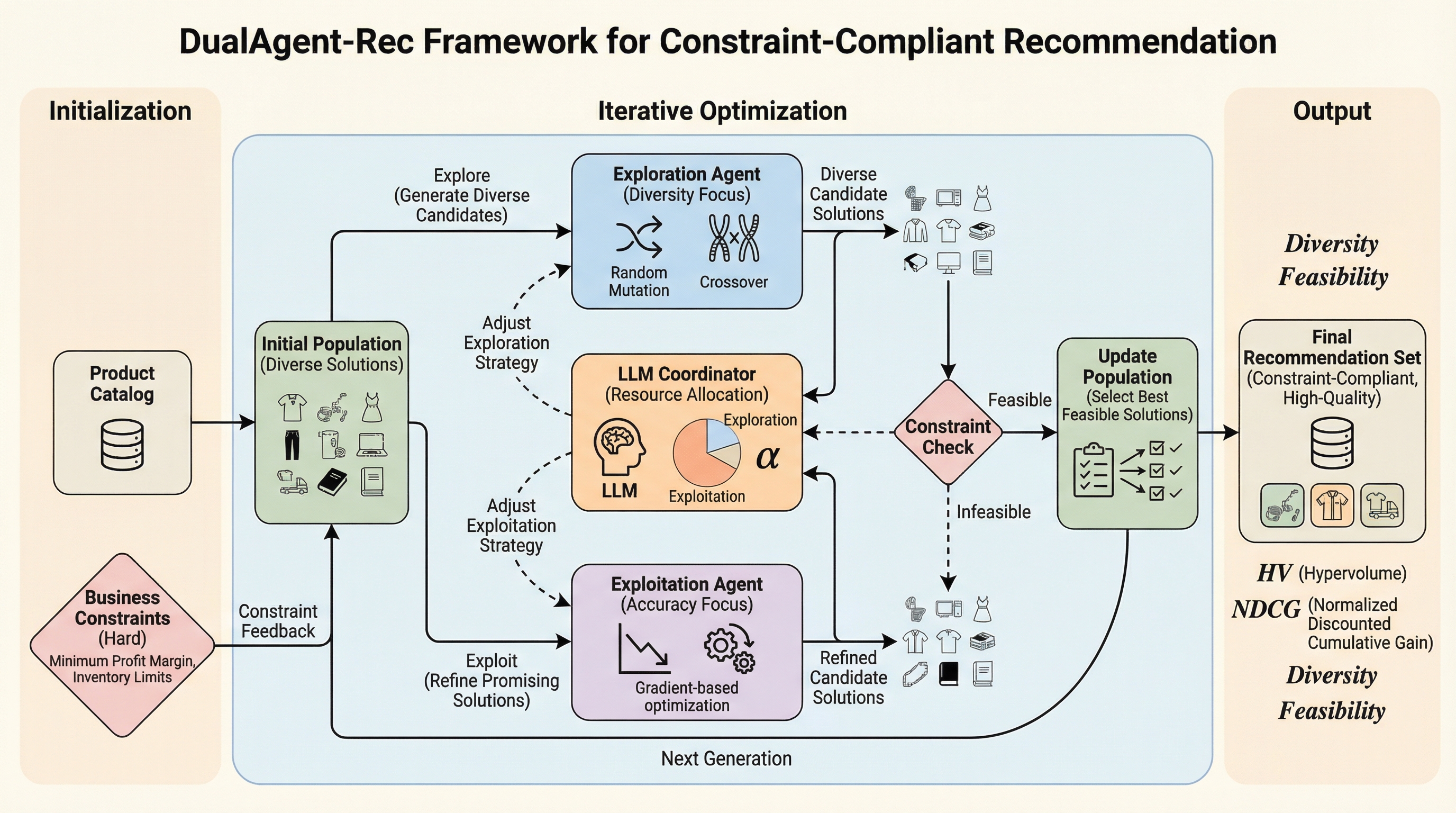
DualAgent-Recは、LLMを高度なオーケストレーターとして活用し、推薦精度と多様性の最適化、および公平性や出品者カバレッジといった厳しいビジネス制約の完全な遵守を両立させる新しいマルチエージェント・フレームワークです。
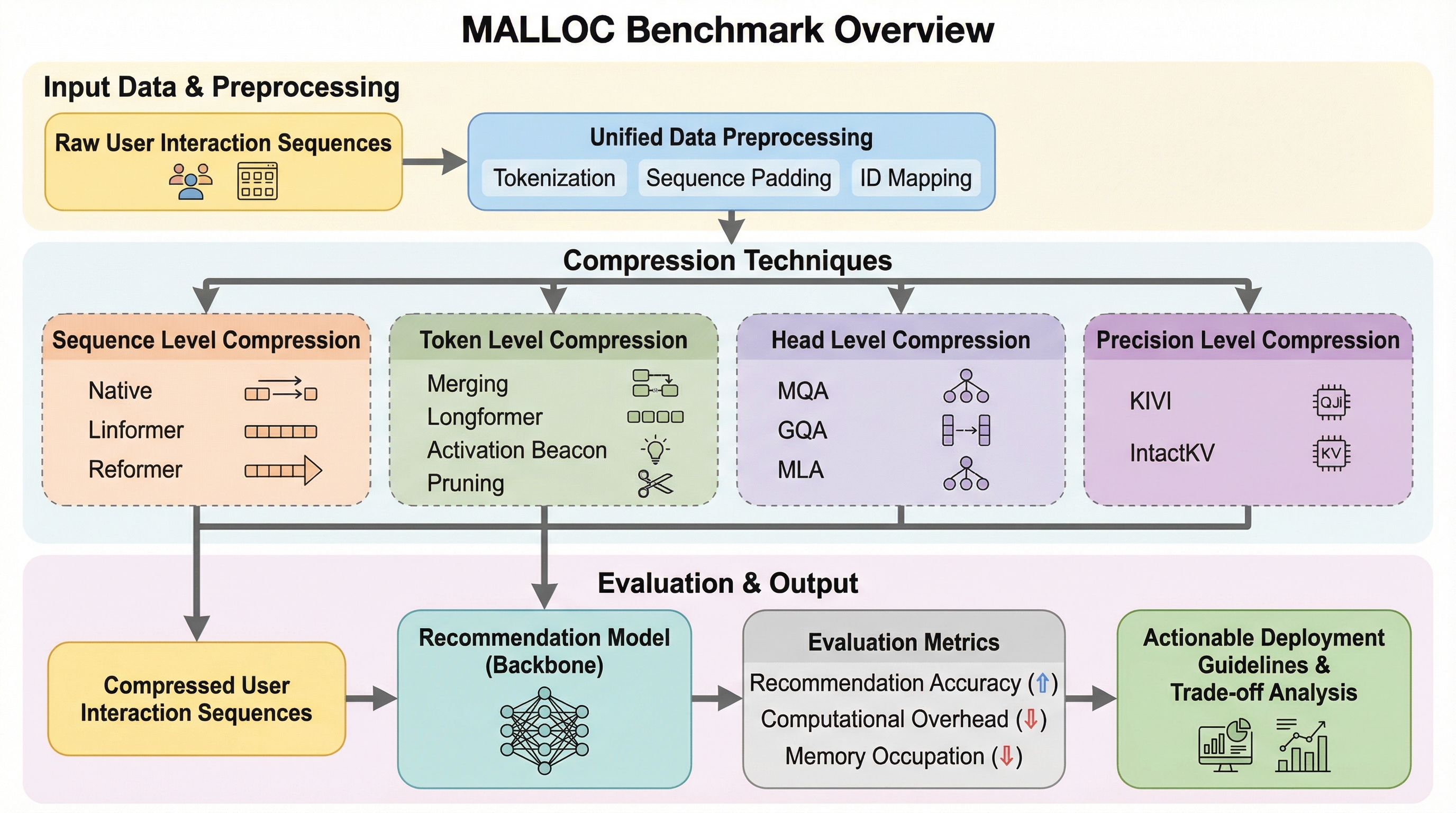
大規模推薦システムにおいて、ユーザーの長い行動履歴を処理する際の計算コストとメモリ消費の爆発的な増加(メモリ・レイテンシのジレンマ)を解決するため、メモリ効率を重視した長系列圧縮技術の包括的なベンチマークである「MALLOC」が提案されました。
自然言語プロファイルを用いた推薦システムは、ユーザーが自分の好みをテキストで直接編集できるため、従来の数値ベクトル形式よりも高い透明性と操作性を提供しますが、これまでの評価は映画のジャンルなどの限定的な属性に留まっており、多様な要求への対応力は不明でした。
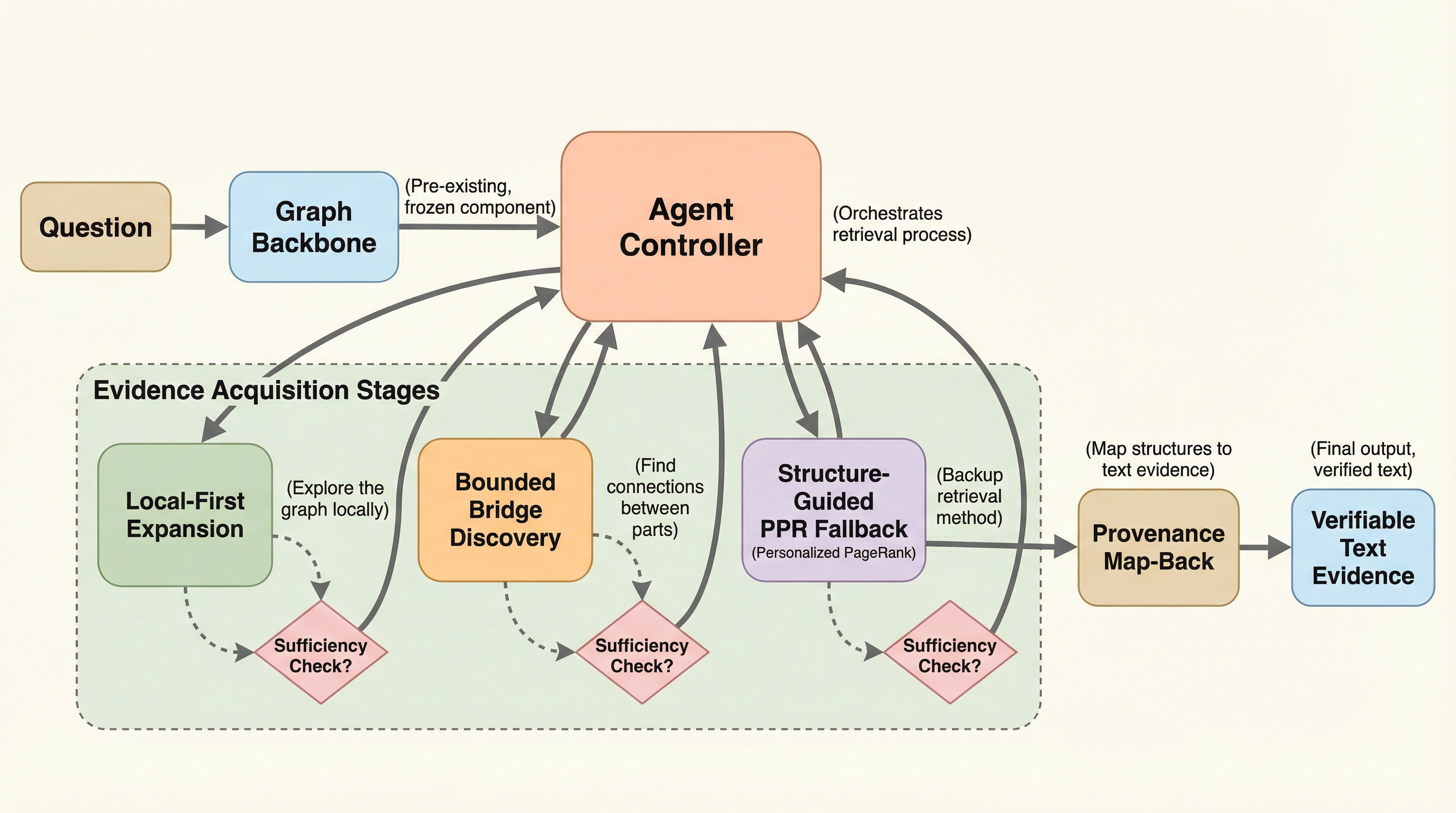
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
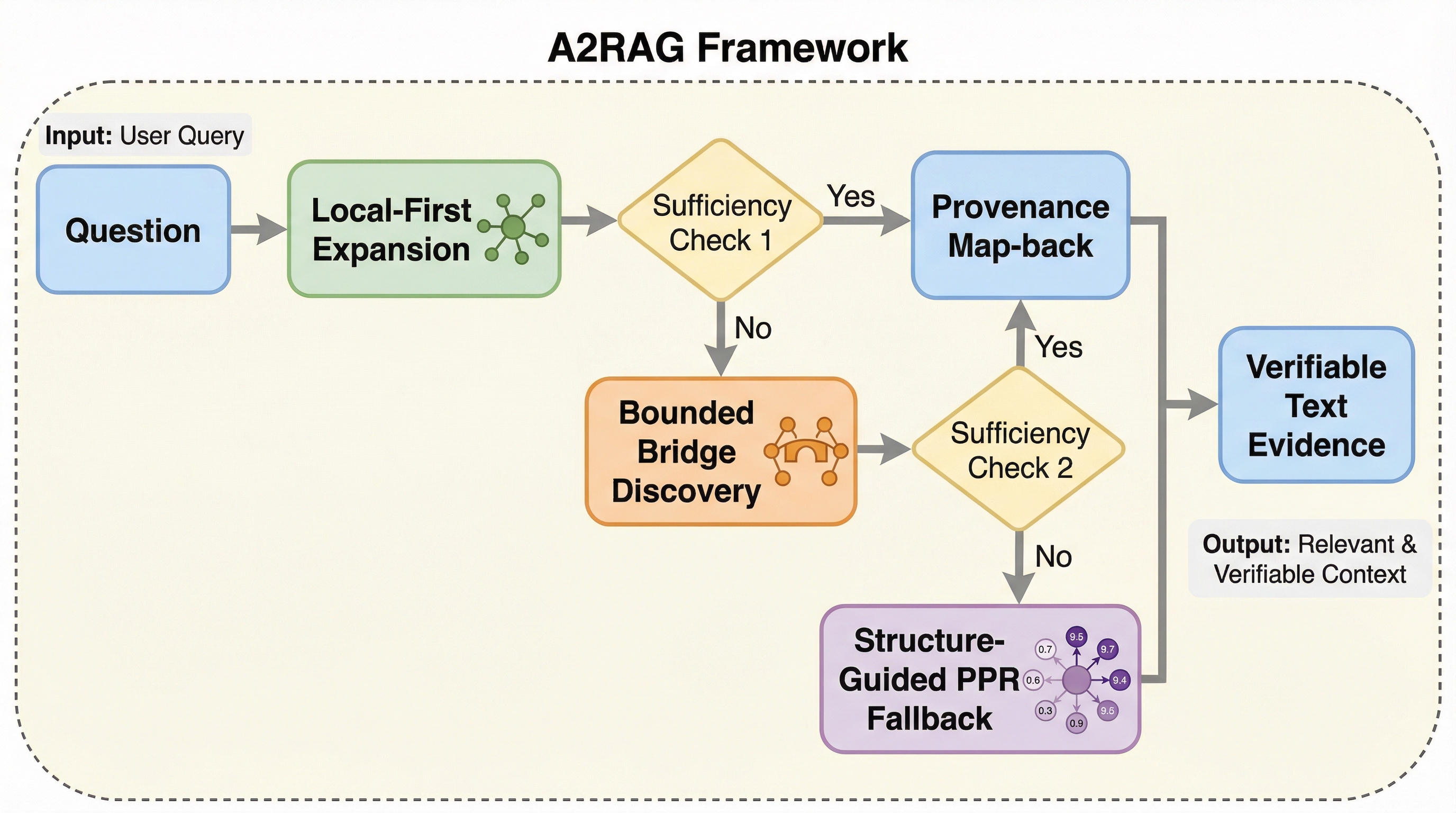
従来のGraphRAGは、全ての質問に対して一律の高度な検索を行うため、簡単な質問での過剰なコスト消費と、複雑な質問におけるグラフ化の際の情報欠落という二つの課題を抱えていました。 本研究が提案するA2RAGは、回答の妥当性を検証して必要時のみ再試行する「適応型制御ループ」と、局所から広域へ段階的に探索範囲を広げつつ元のテキストから詳細を復元する「エージェント型検索機」を統合したフレームワークです。 ベンチマークを用いた検証では、従来の反復的な手法と比較して検索精度を最大11.8ポイント向上させつつ、トークン消費量と処理遅延を約50パーセント削減することに成功し、実用的な効率と信頼性の両立を証明しました。
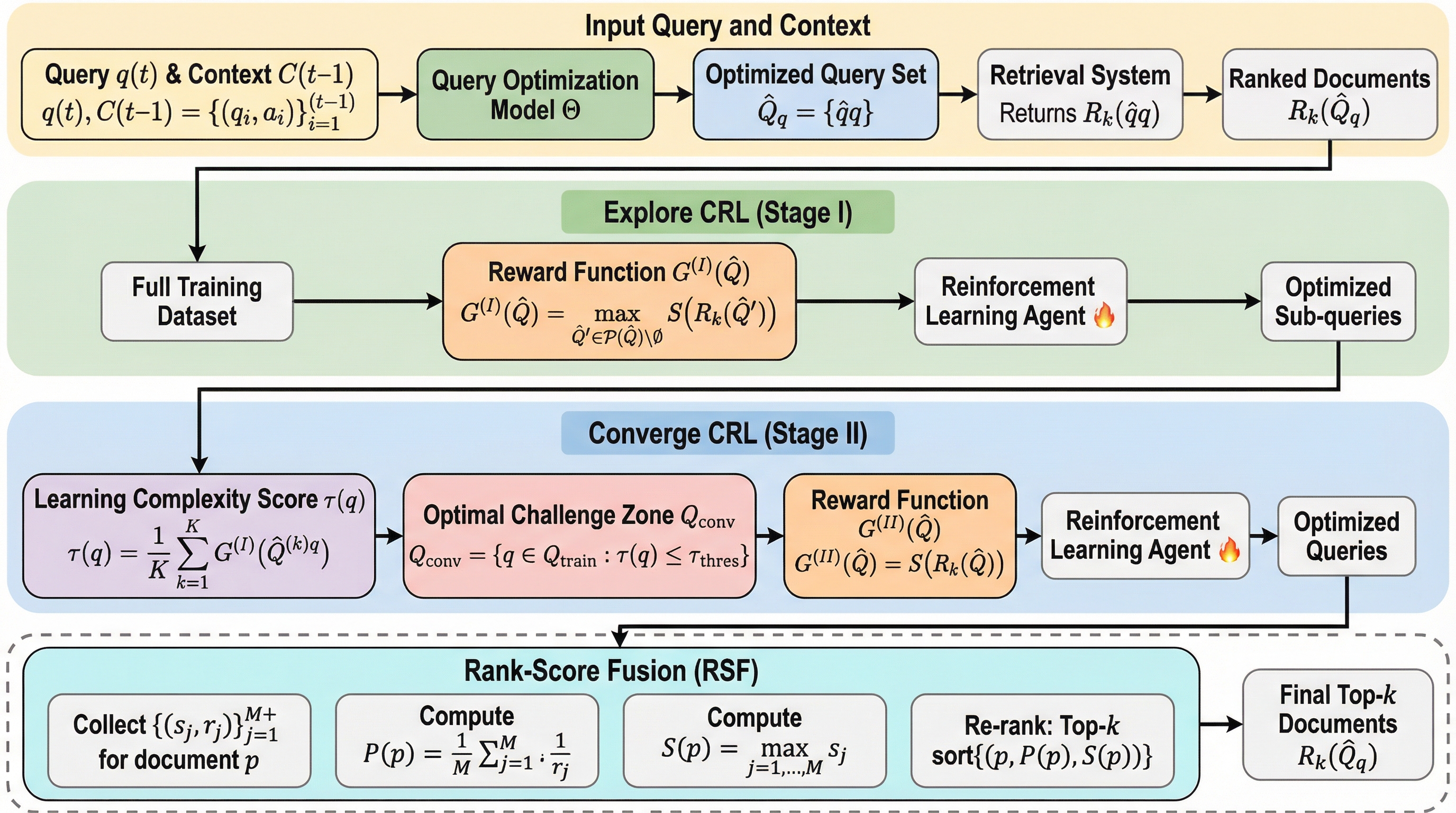
検索拡張生成(RAG)において、複雑なユーザーの質問を適切に分解・明確化して検索精度を高めるための新しい強化学習フレームワーク「ACQO」が提案されました。従来の単一クエリの拡張手法とは異なり、クエリの複雑さに応じて適応的に検索プロセスを拡張するかどうかを判断し、複数のサブクエリを生成する仕組みを備えています。
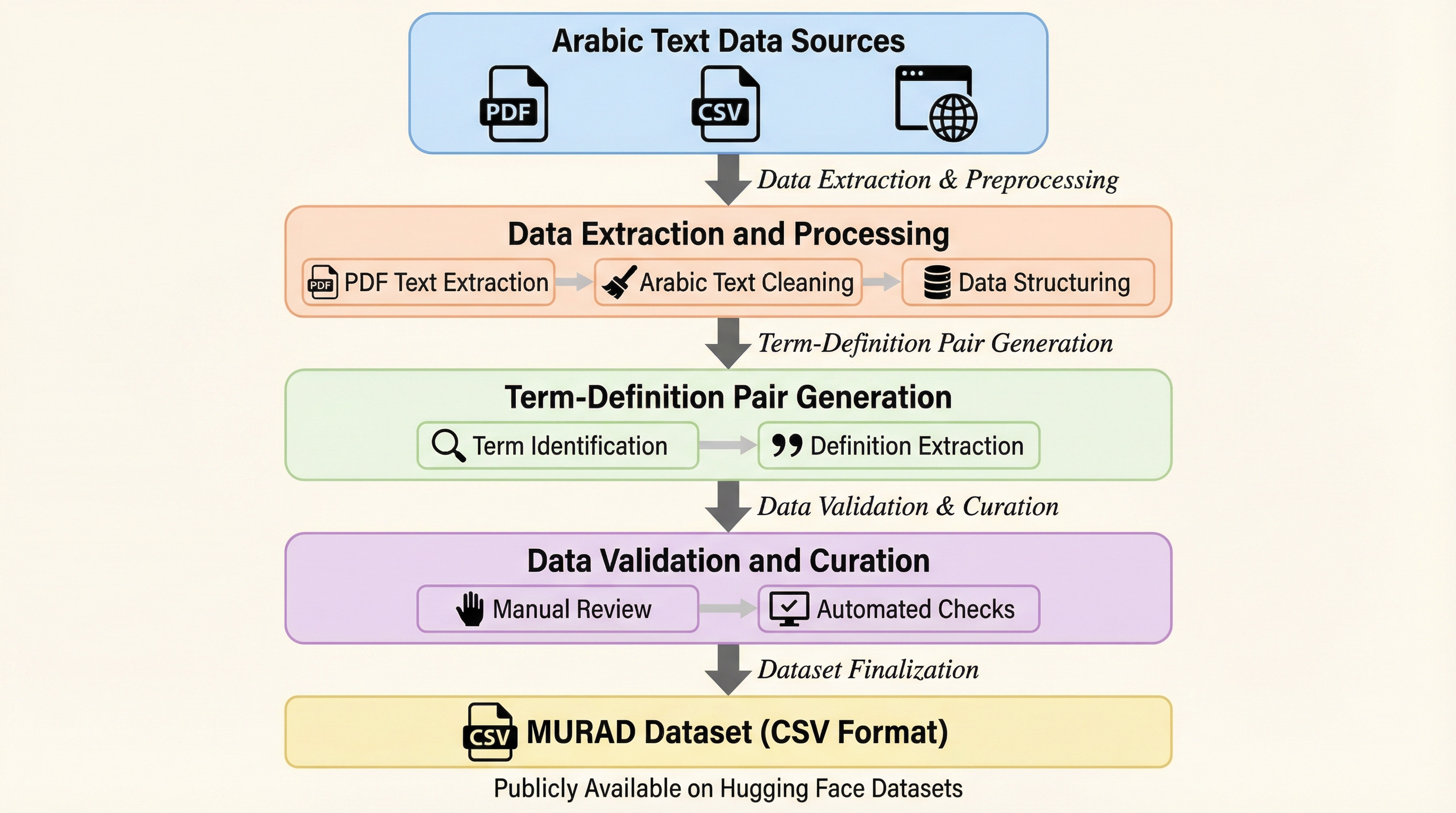
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.