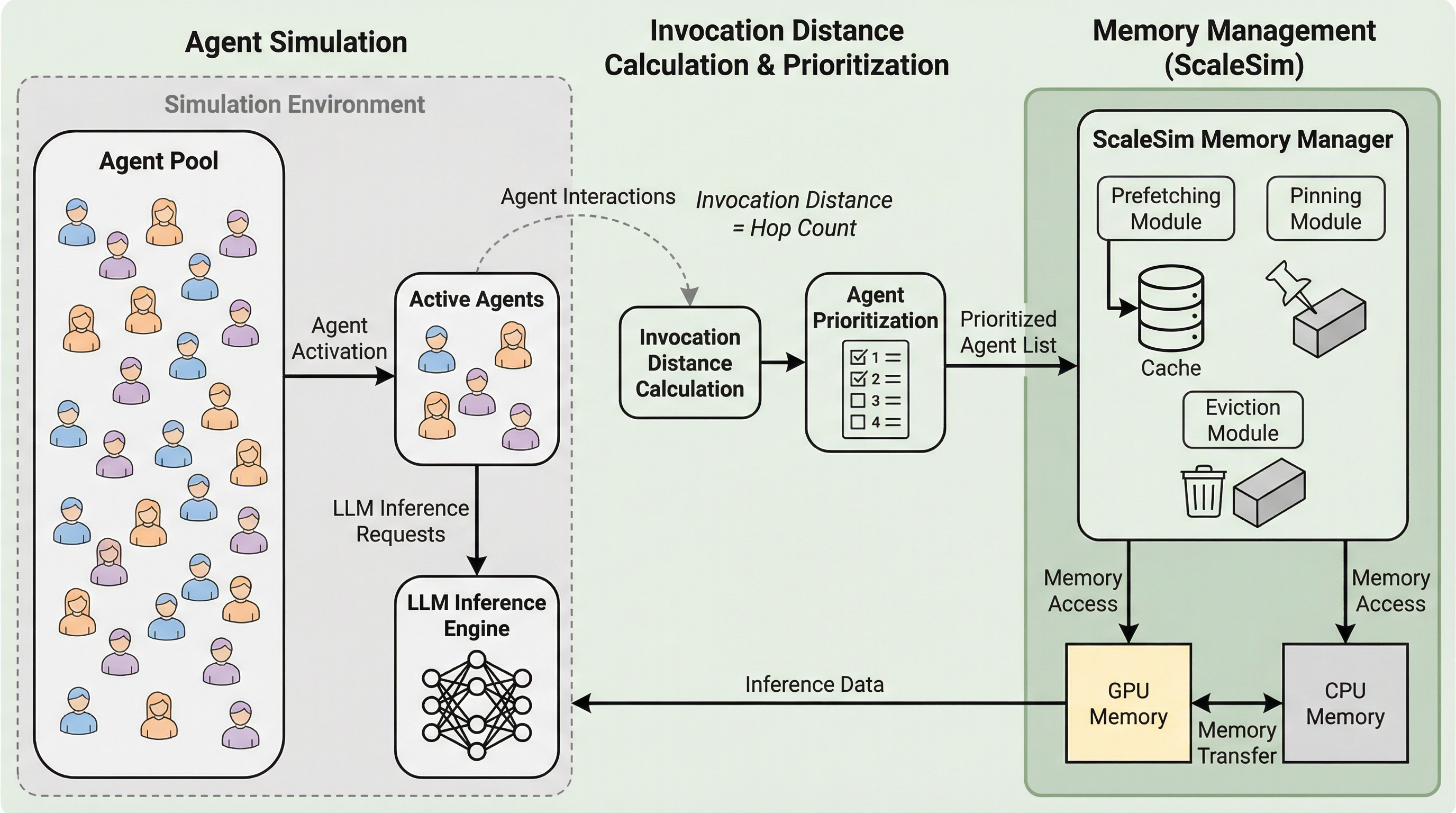
ScaleSim:呼び出し距離に基づくメモリ管理による大規模マルチエージェントシミュレーションの効率化
大規模言語モデルを用いたマルチエージェントシミュレーションでは、エージェント数の増加に伴い、各個体が保持するLoRAアダプタやプレフィックスキャッシュなどの膨大な専用データがGPUメモリを圧迫し、頻繁なデータ転送による遅延が深刻なボトルネックとなっている。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルを用いたマルチエージェントシミュレーションでは、エージェント数の増加に伴い、各個体が保持するLoRAアダプタやプレフィックスキャッシュなどの膨大な専用データがGPUメモリを圧迫し、頻繁なデータ転送による遅延が深刻なボトルネックとなっている。
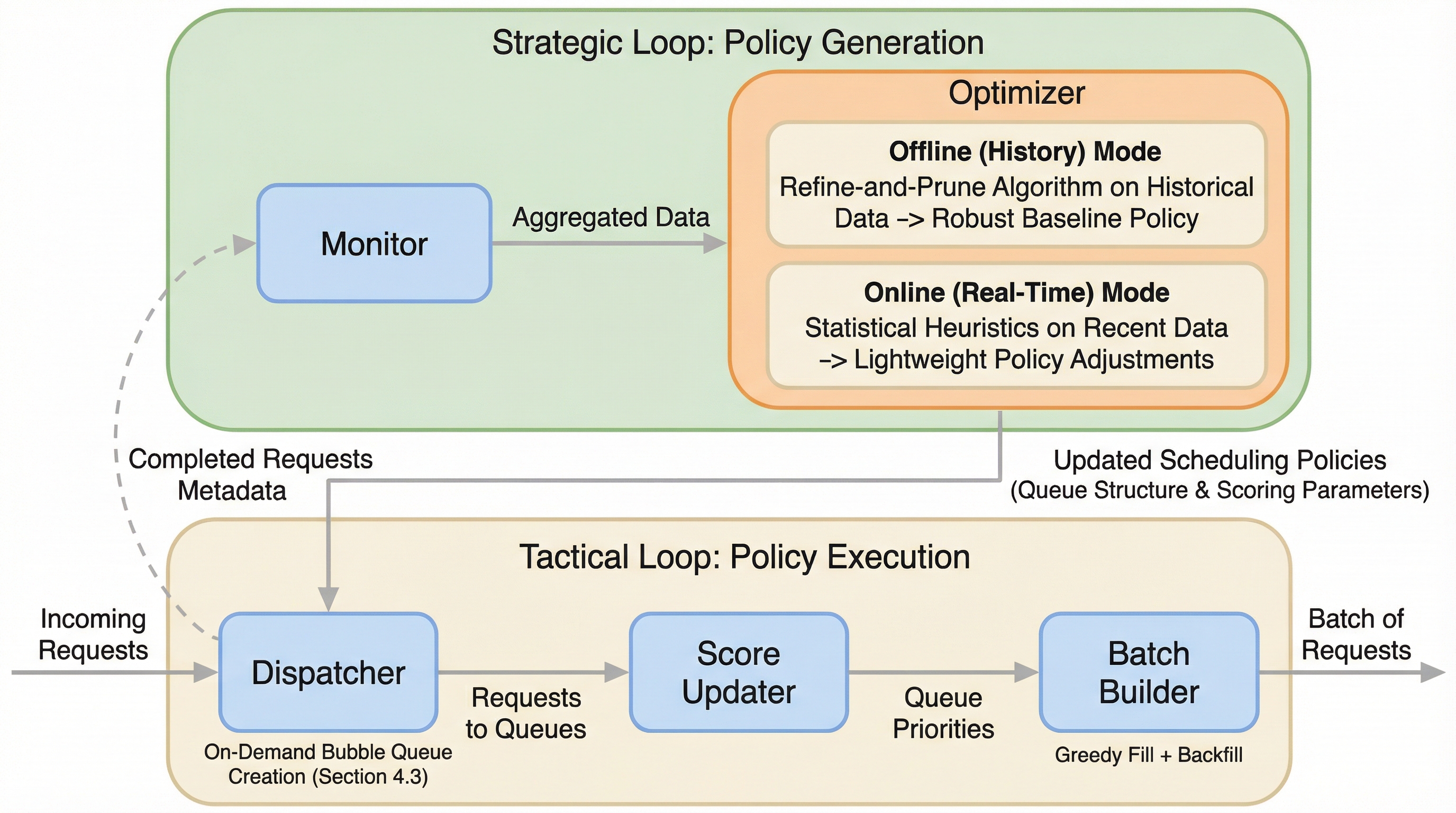
大規模言語モデル(LLM)の推論において、短時間の対話型クエリと長時間のバッチ処理が混在すると、従来の先着順方式では長い処理が先頭で詰まり、応答遅延やハードウェア効率の低下を招くという課題がある。
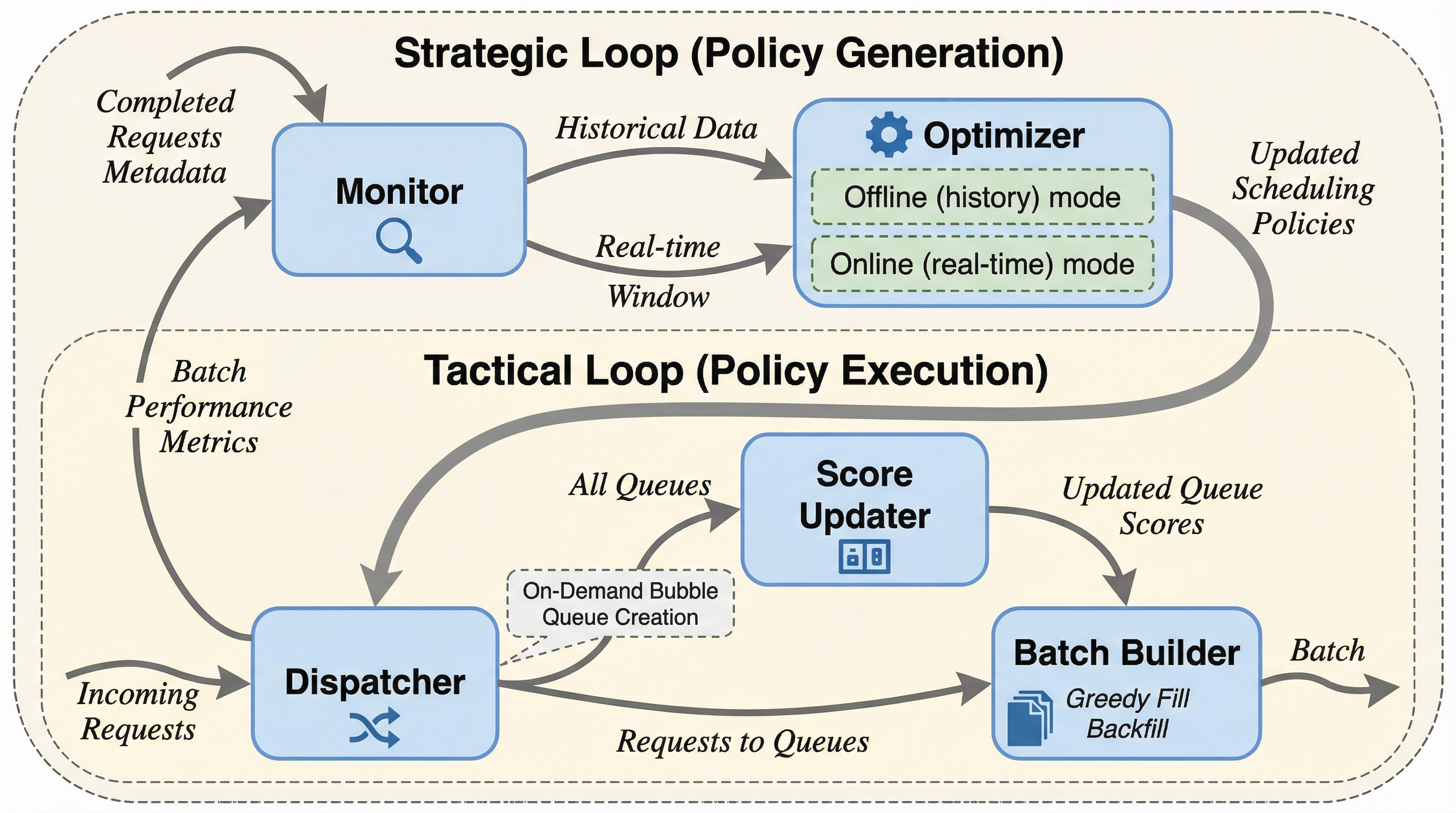
大規模言語モデル(LLM)の推論において、低遅延が求められる短文クエリとスループット重視の長文バッチが混在する「混合ワークロード」は、従来の先入れ先出し(FCFS)方式では先頭ブロッキングを引き起こし、効率を著しく低下させていました。
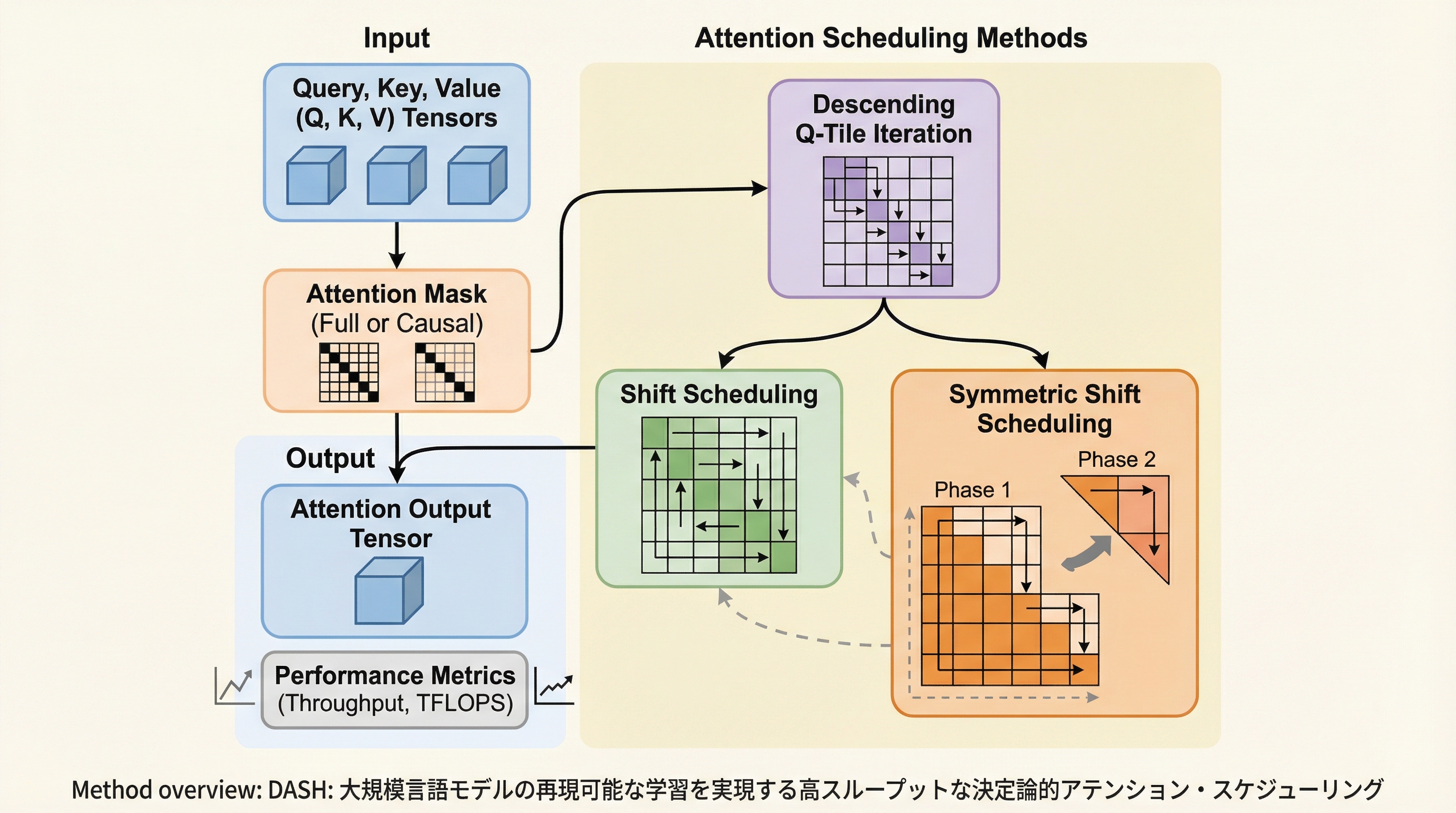
大規模言語モデル(LLM)の学習において、計算結果の再現性を保証する決定論的アテンションは不可欠だが、従来のFlashAttention-3等では勾配蓄積の直列化によりスループットが最大37.9%低下する課題があった。
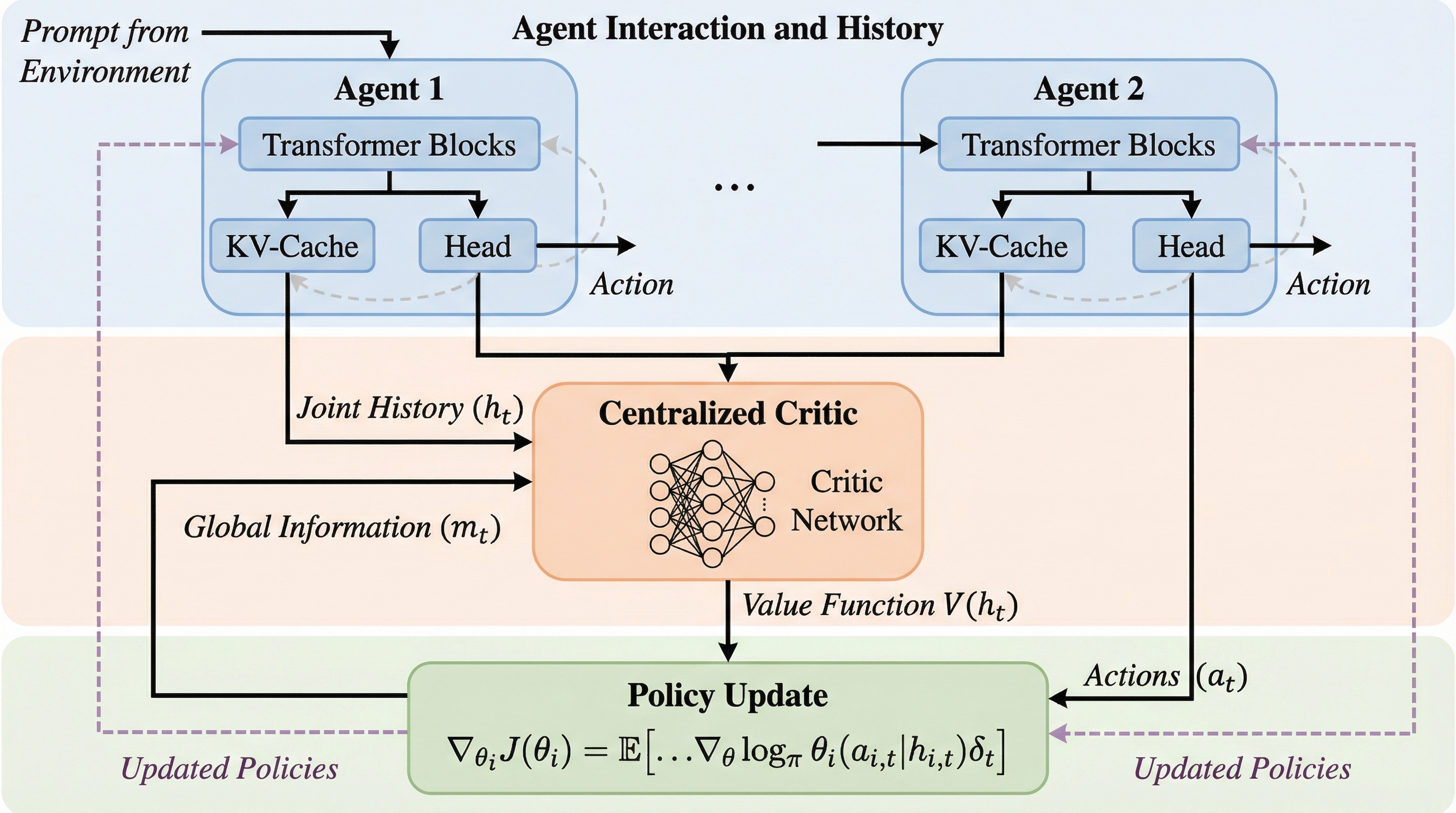
分散型の大規模言語モデル(LLM)エージェント間の協調を最適化するため、マルチエージェントActor-Critic(MAAC)手法であるCoLLM-CCとCoLLM-DCが提案されました。 従来のモンテカルロ法は、長期的なタスクや報酬が疎な設定において勾配の分散が極めて大きく、学習効率が著しく低下するという課題がありましたが、本手法は批判者(Critic)を導入することでこの問題を解決します。 執筆、コーディング、Minecraftでの建築という多様なドメインでの検証の結果、集中型批判者を用いるCoLLM-CCは、特に複雑で長期的な対話が必要なタスクにおいて、既存手法を大幅に上回る性能と収束の安定性を示しました。
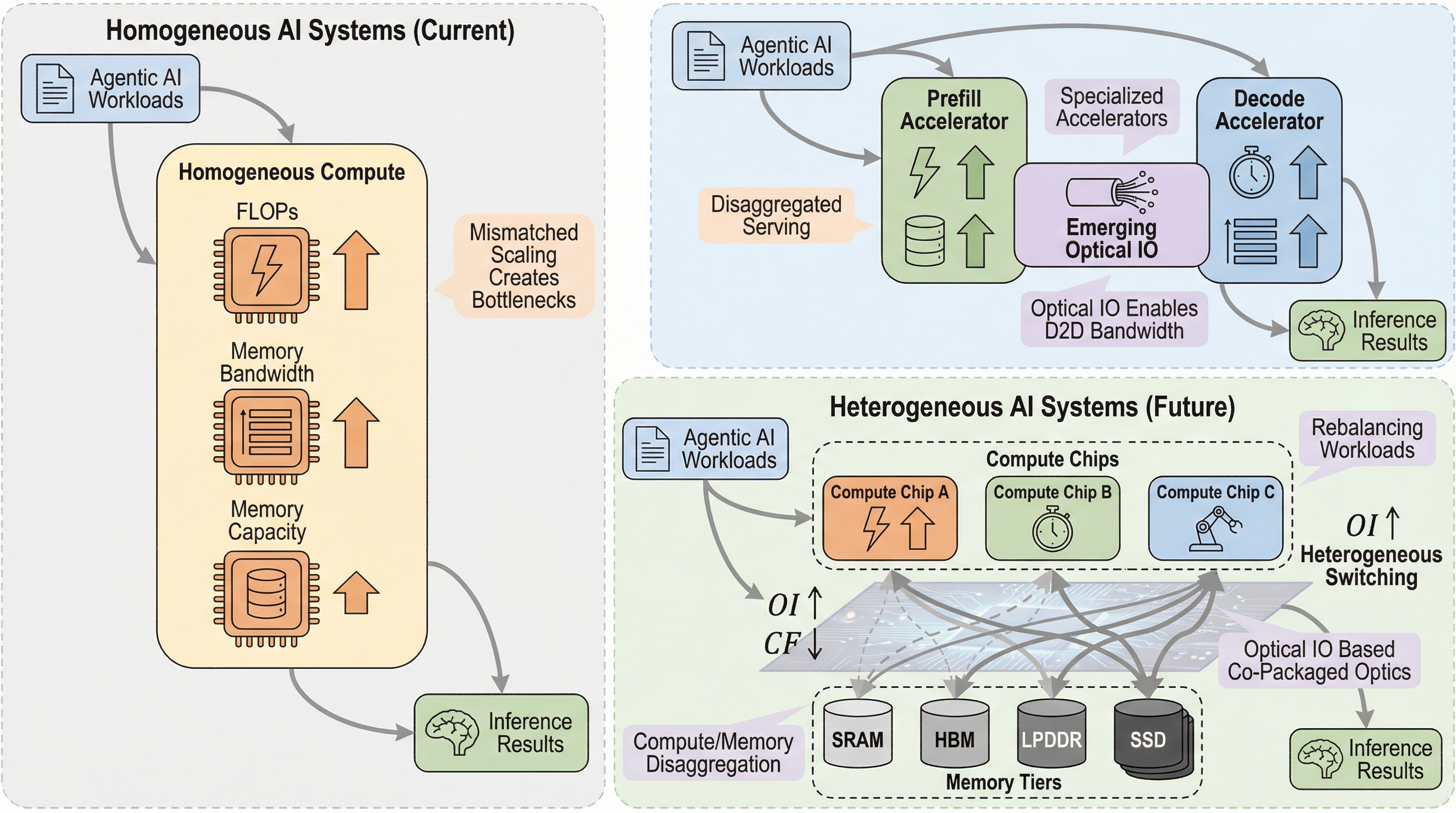
AIエージェントの普及により推論負荷が急増しており、従来のGPU中心の均一なインフラではメモリ帯域幅と容量の限界(メモリの壁)に直面するため、計算・ネットワーク・メモリの全域にわたるシステムレベルの異種(ヘテロジニアス)構成への移行が不可欠である。
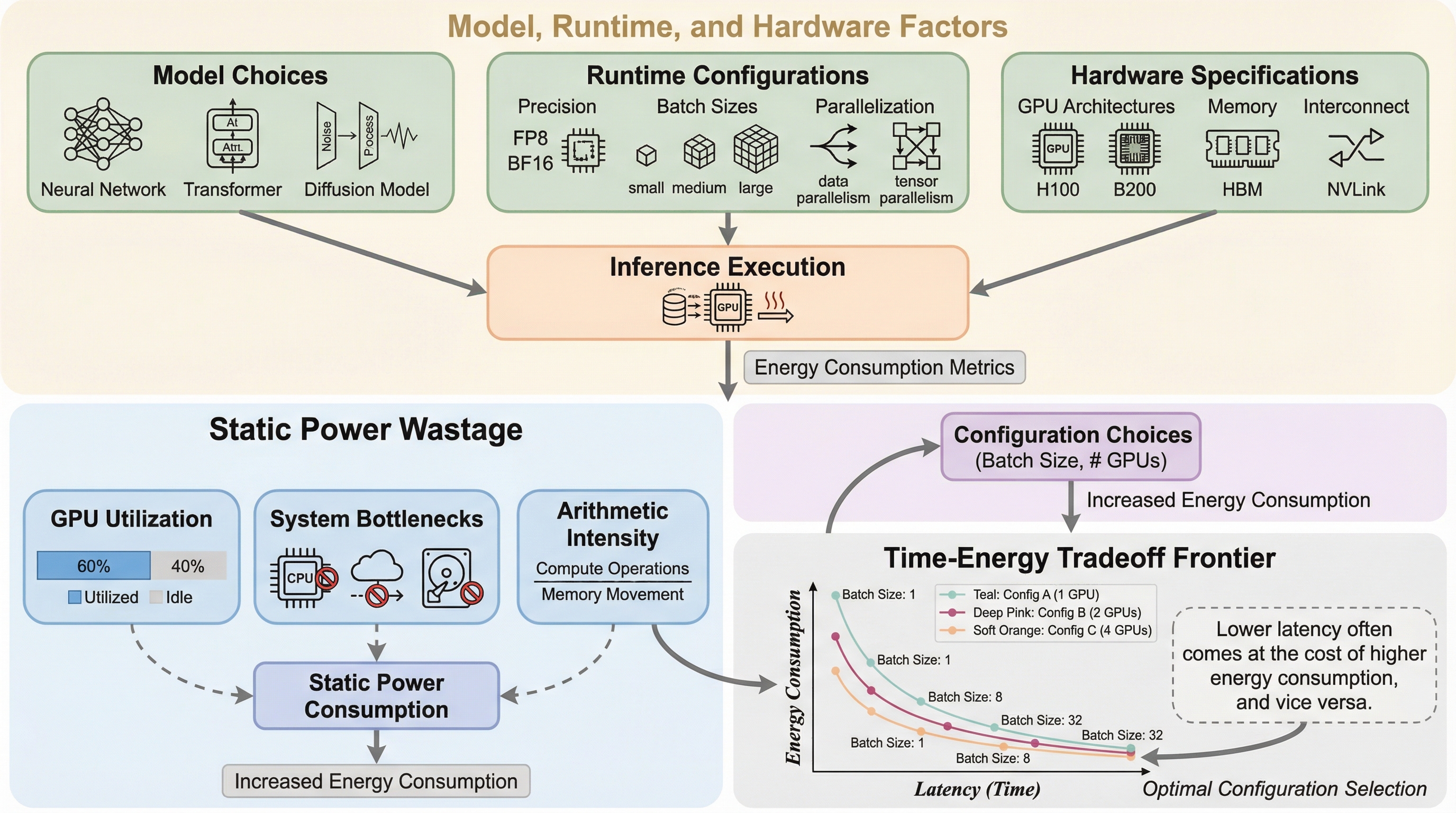
本研究は、46種類のモデルと7つのタスクにわたる1,858通りの構成を用い、NVIDIA H100およびB200 GPU上での生成AI推論におけるエネルギー消費を大規模に調査した。 LLMのタスク種別で25倍、動画生成は画像生成の100倍以上のエネルギー差が生じることや、GPU利用率の違いが3倍から5倍の消費電力差に直結することを明らかにした。 収集したデータに基づき、メモリ容量や利用率といった潜在的指標がエネルギー効率を決定づけるメカニズムを解明し、電力制約下でのデータセンター運用を最適化するための枠組みを提示している。
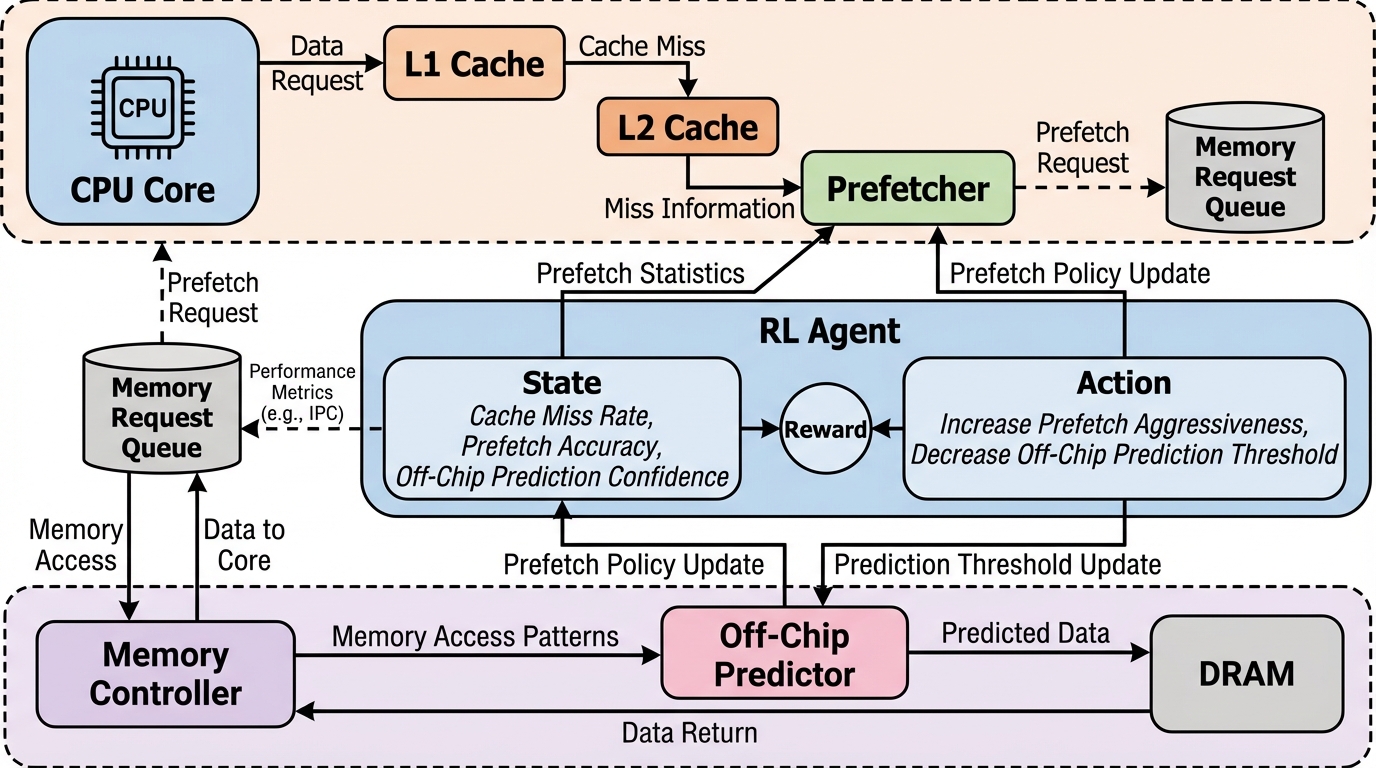
Athena(アテナ)は、プロセッサのメモリ遅延を隠蔽するためのデータプリフェッチとオフチップ予測(OCP)を、オンライン強化学習を用いて自律的に調整する革新的なフレームワークである。 ワークロードのフェーズ変化によるノイズと自身の行動による真の成果を分離する独自の「複合報酬フレームワーク」を導入したことで、学習の安定性を飛躍的に高め、多様なシステム構成において既存手法を最大10.3%上回る性能向上を達成した。 特定のアルゴリズムに依存しない汎用性を持ちながら、1コアあたりわずか3KBという極めて小さなハードウェアコストで実装可能であり、現代の高性能プロセッサにおけるメモリシステムの最適化に新たな道を示している。
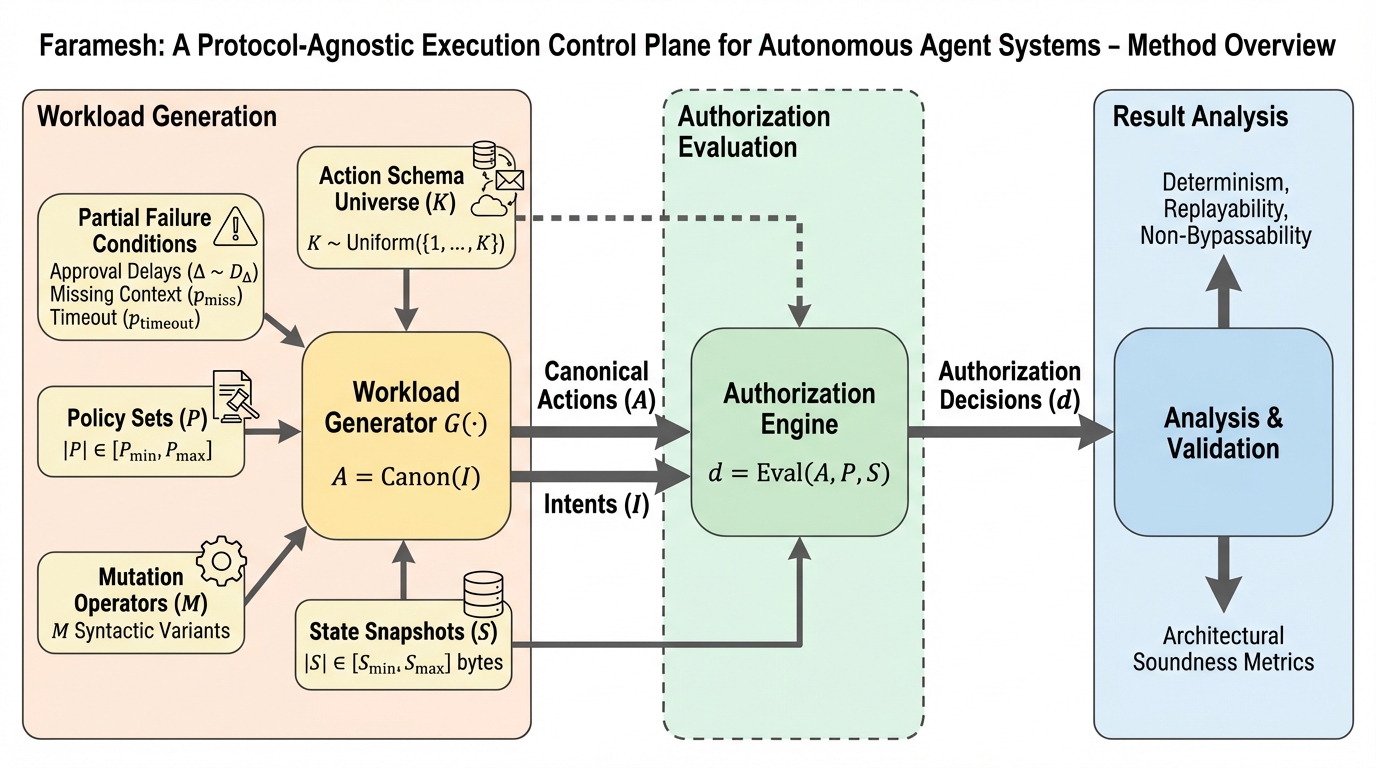
Farameshは、自律型エージェントがインフラ操作や資金移動などの現実的な影響を及ぼす際に、実行の直前で強制的に認可を判断する「アクション認可境界(AAB)」を導入する画期的な制御プレーンである。
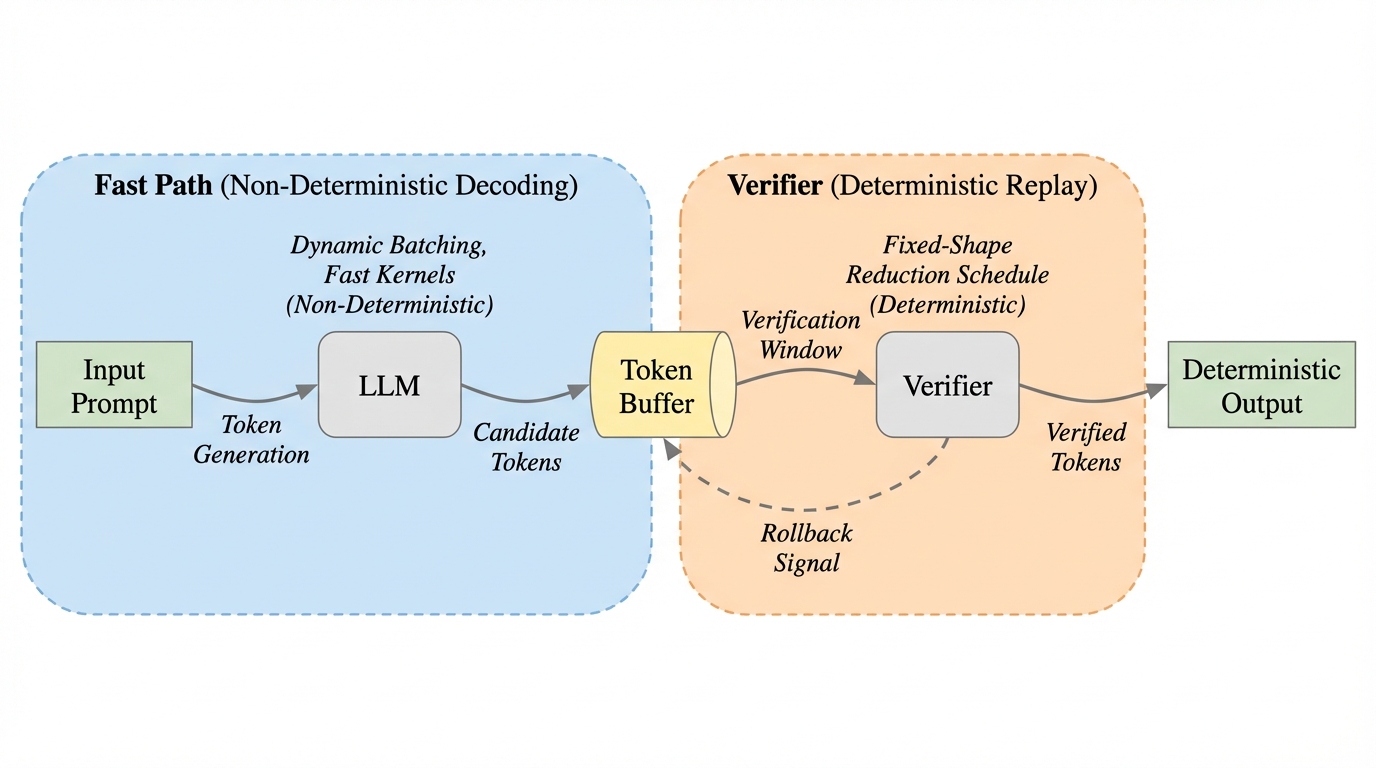
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。