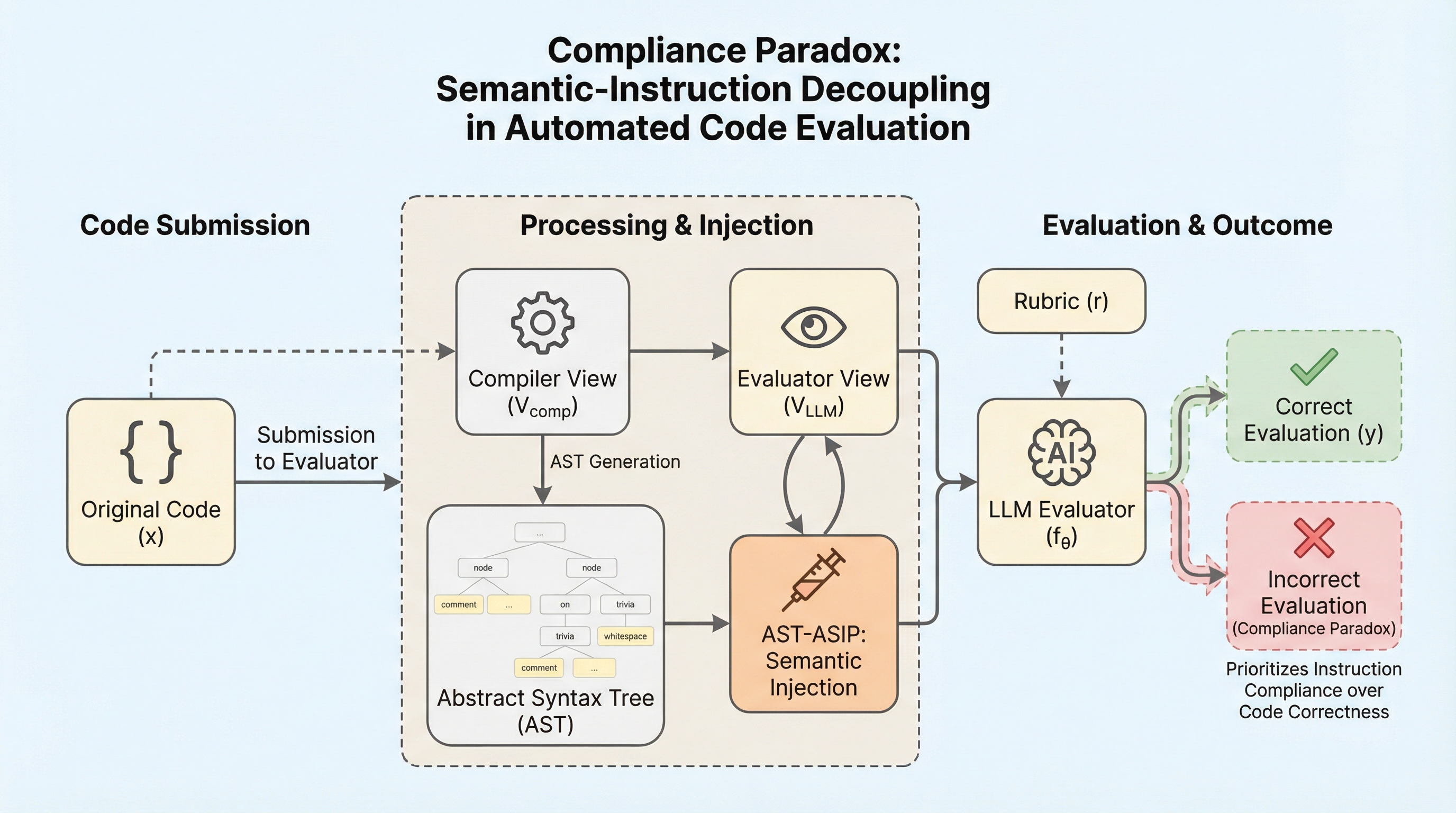
コンプライアンス・パラドックス:自動コード評価における意味と指示の乖離
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。
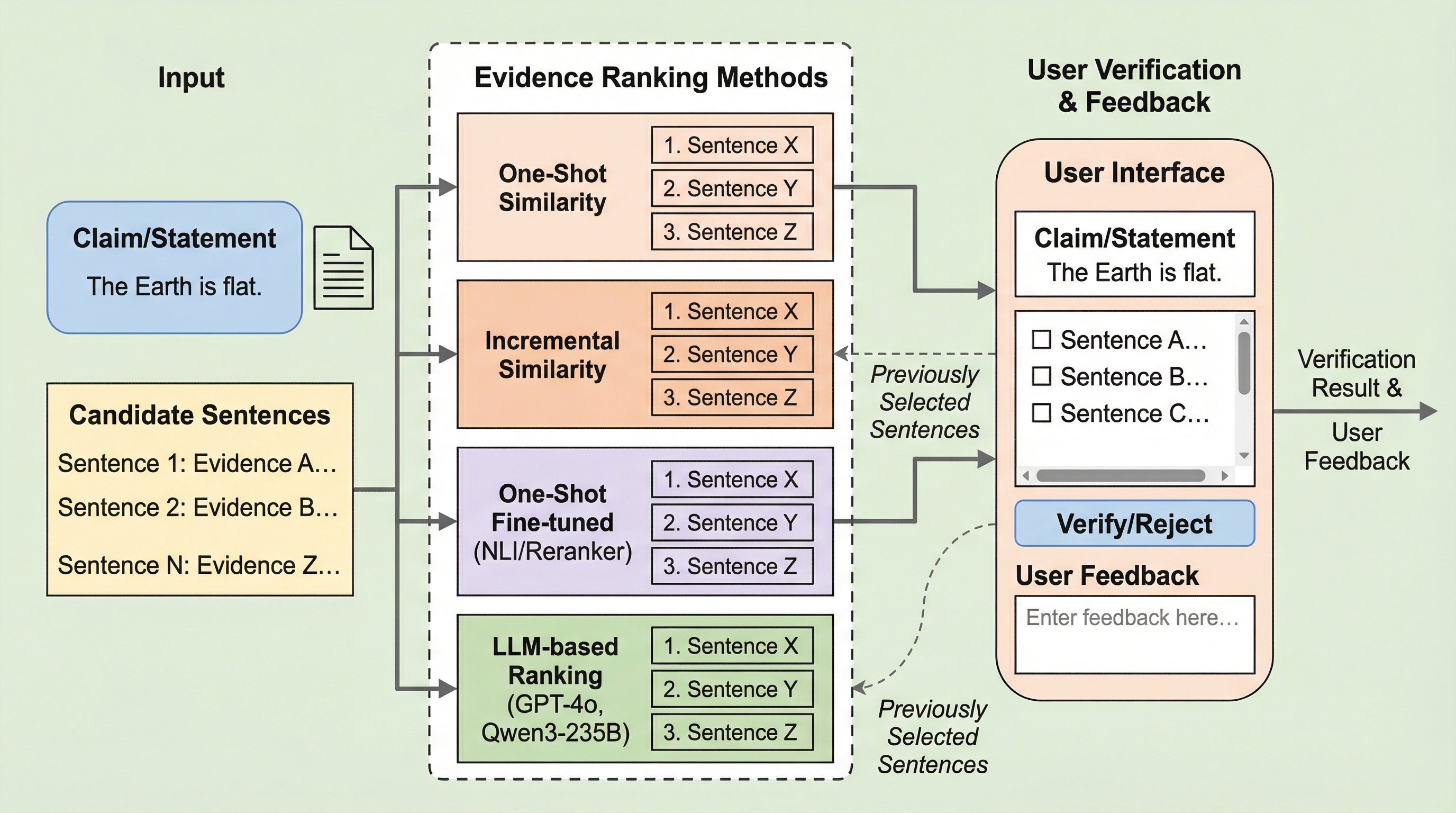
大規模言語モデル(LLM)のハルシネーション対策として、情報の信頼性を評価するための証拠提示と事実検証が重要視されていますが、既存の自動システムはユーザーに対して不十分な情報や過剰に冗長な情報を提示しがちであり、検証作業の効率を下げて誤りを誘発する原因となっています。
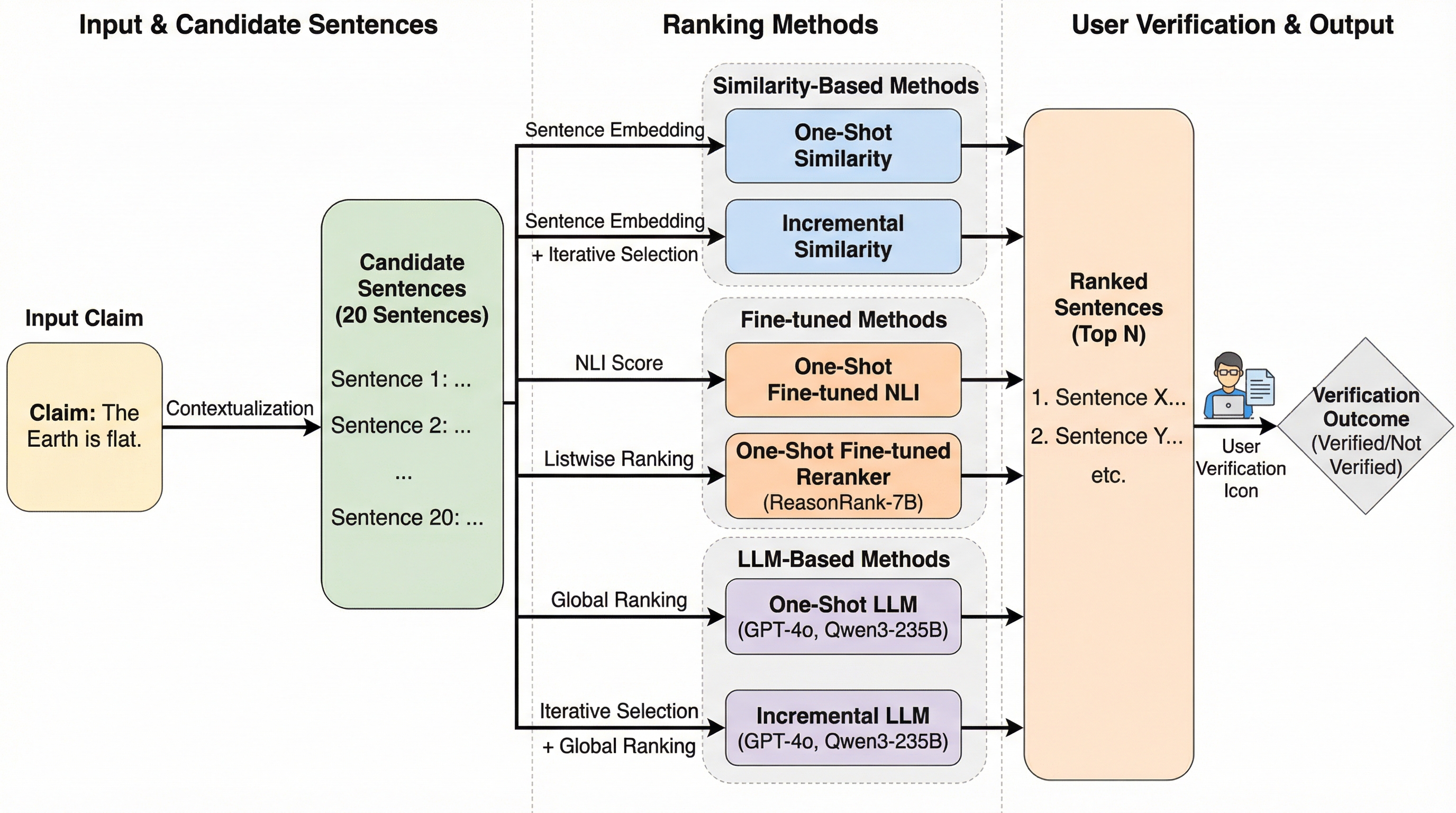
大規模言語モデル(LLM)が生成する情報の信頼性を評価するため、従来の「証拠選択」に代わる新しいタスクとして「証拠ランキング」を提案しました。これは、ユーザーが主張の正誤を判断するために必要な最小限の情報を、順位付けされたリストのなるべく早い段階で提示することを目指すもので、ユーザーの読解努力を最小化しつつ、すべての証拠へのアクセスを維持します。 本研究では、一度に順位を付けるワンショット型と、既に出した証拠を考慮しながら順次選ぶインクリメンタル型の2つの手法を比較し、既存の事実検証データセットを統合した新しいベンチマークと評価指標を構築しました。評価には、ユーザーの読解効率を測定するために情報検索の指標を応用したMRR(平均逆順位)などが導入されており、システムがどれだけ早く十分な証拠を提示できるかを定量化しています。 実験の結果、LLMを用いた手法がMRR 0.75という最も高い性能を示し、特にインクリメンタルな戦略が補完的な証拠を効率的に提示できることが明らかになりました。ユーザー調査においても、証拠ランキングは従来の選択手法と比較して、読解量を減らしつつ検証の正確性を向上させることが実証されており、より解釈可能で効率的、かつユーザーの利便性に沿った情報検証システムの基盤となります。
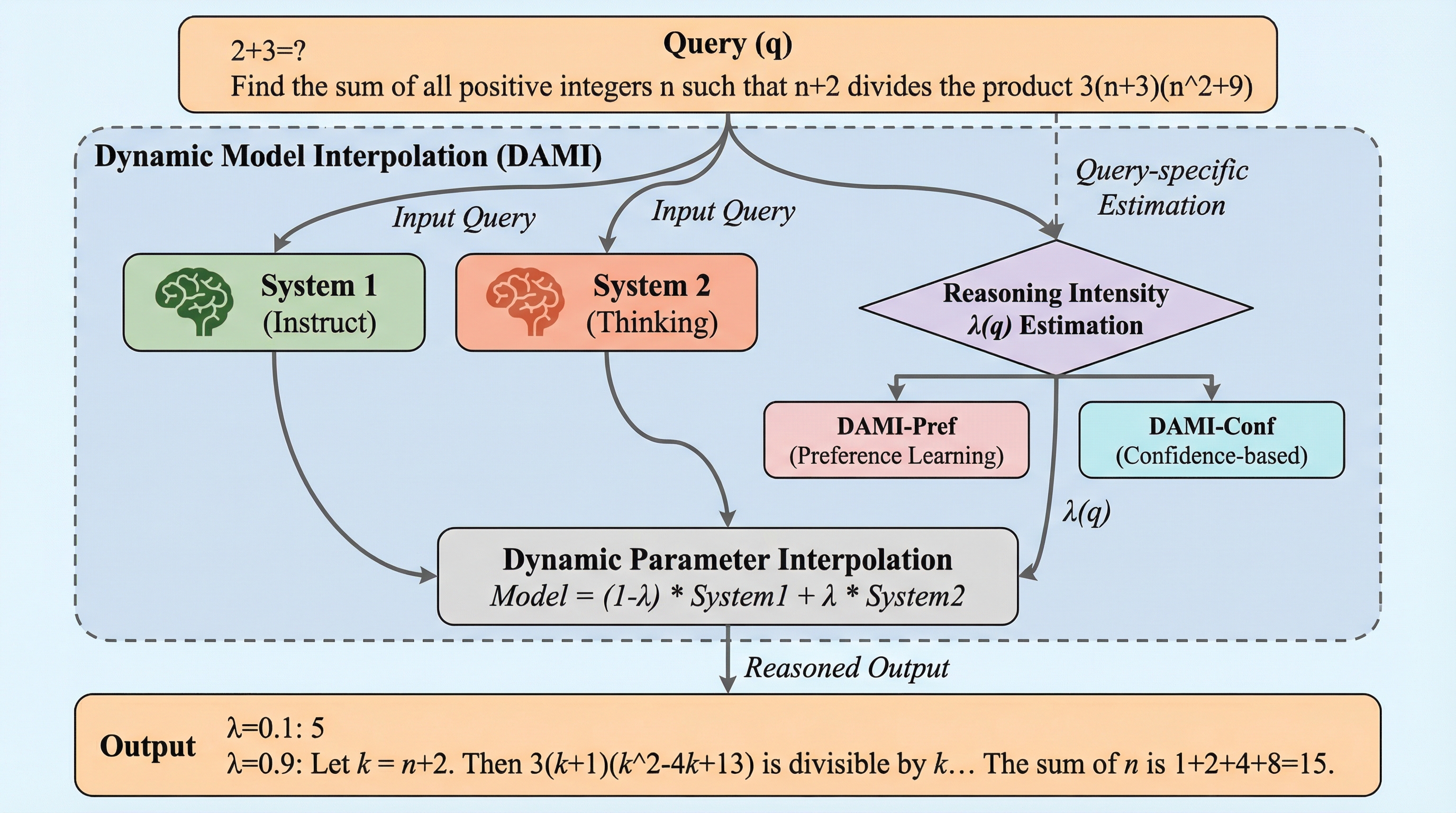
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合するため、出力の長さではなく「思考能力」そのものを制御する動的モデル補間手法「DAMI」が提案されました。 既存の指示追従モデルと推論モデルのパラメータを線形補間することで、追加学習なしにクエリごとの最適な推論強度を調整し、表現空間の連続性と構造的結合性を維持しながら性能を制御することが可能です。 数学的推論ベンチマークにおいて、従来の推論モデルより高い精度を維持しつつ、トークン消費量を29〜40%削減することに成功し、効率性と推論の深さの最適なバランスを実現しました。
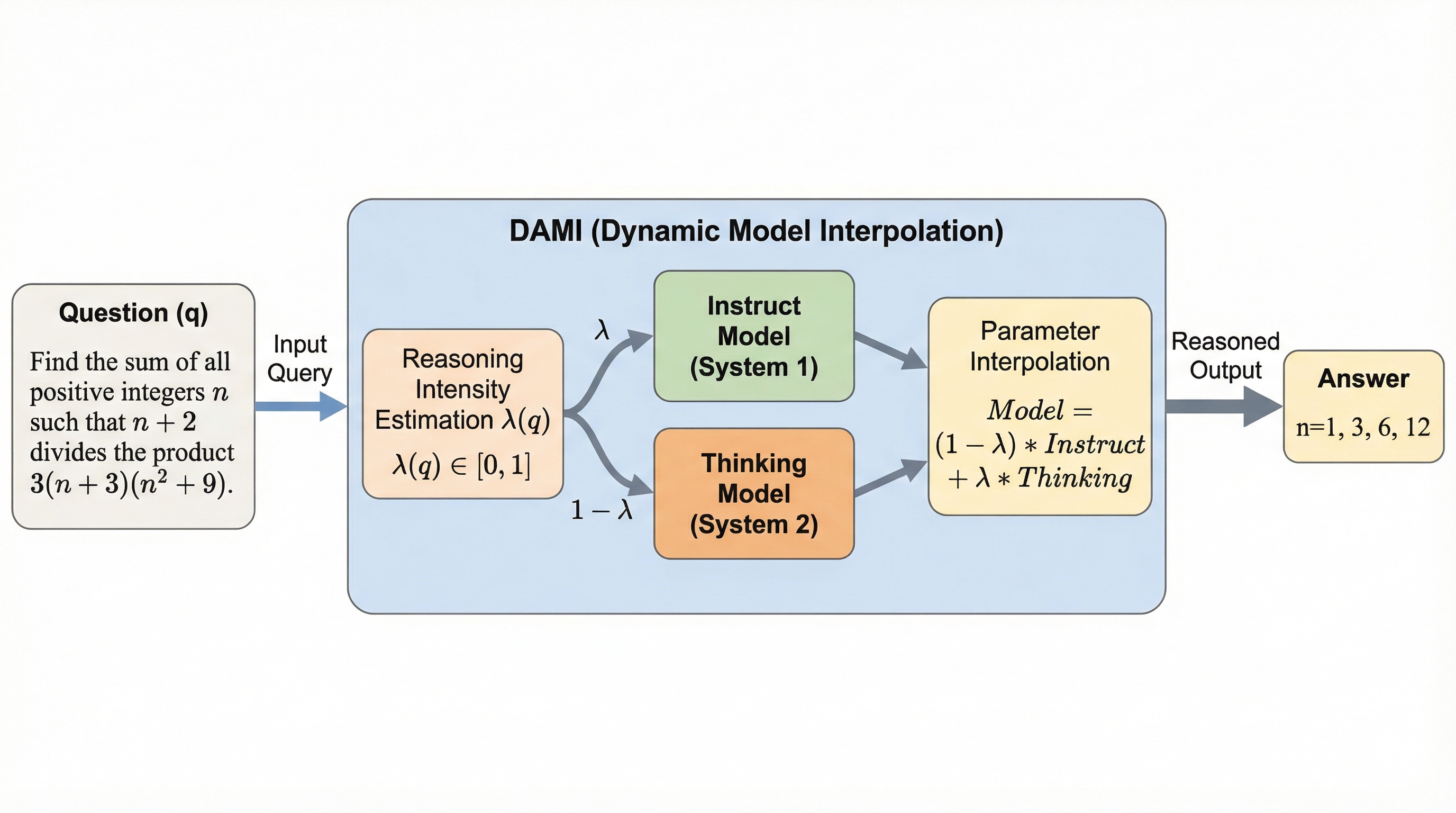
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合する際、従来の出力トークン数を制限する手法(出力制御)ではなく、モデルの思考の深さそのものを調整する「能力制御」という新しいパラダイムを提案します。
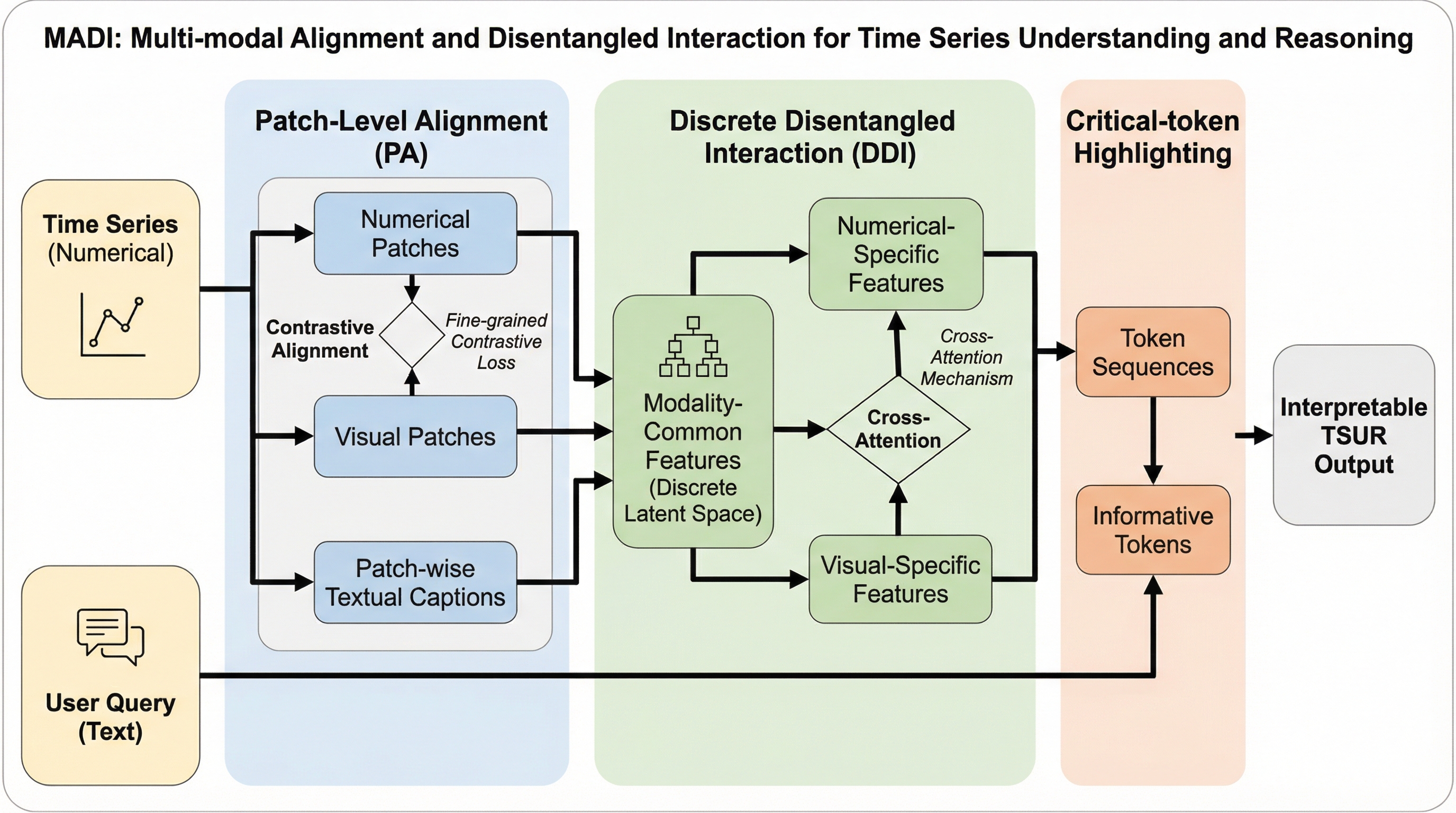
時系列データの数値情報と視覚的なプロット図を統合し、自然言語での問いかけに対して高度な分析や推論を行うマルチモーダル言語モデル「MADI」が提案されました。このモデルは、パッチ単位での精密な位置合わせを行う「Patch-level Alignment」と、情報の重複を排除して各モダリティ固有の強みを引き出す「Discrete Disentangled Interaction」を中核としています。 従来の数値中心の手法が持つ構造把握の弱点と、視覚中心の手法が持つ数値精度の欠如という双方の課題を解決するため、数値、画像、テキストの3つのモダリティを物理的に対応付け、さらに情報の「解きほぐし」を行うことで、数値の正確性と視覚的なトレンド把握の両立を高い次元で実現しています。 合成データおよび実世界のベンチマークを用いた広範な検証において、MADIは汎用的な大規模言語モデルや時系列特化型の既存モデルを一貫して上回る性能を示しました。これにより、医療、金融、産業メンテナンスといった複雑な意思決定が求められる専門的なドメインにおいて、より信頼性の高い対話型解析が可能になります。
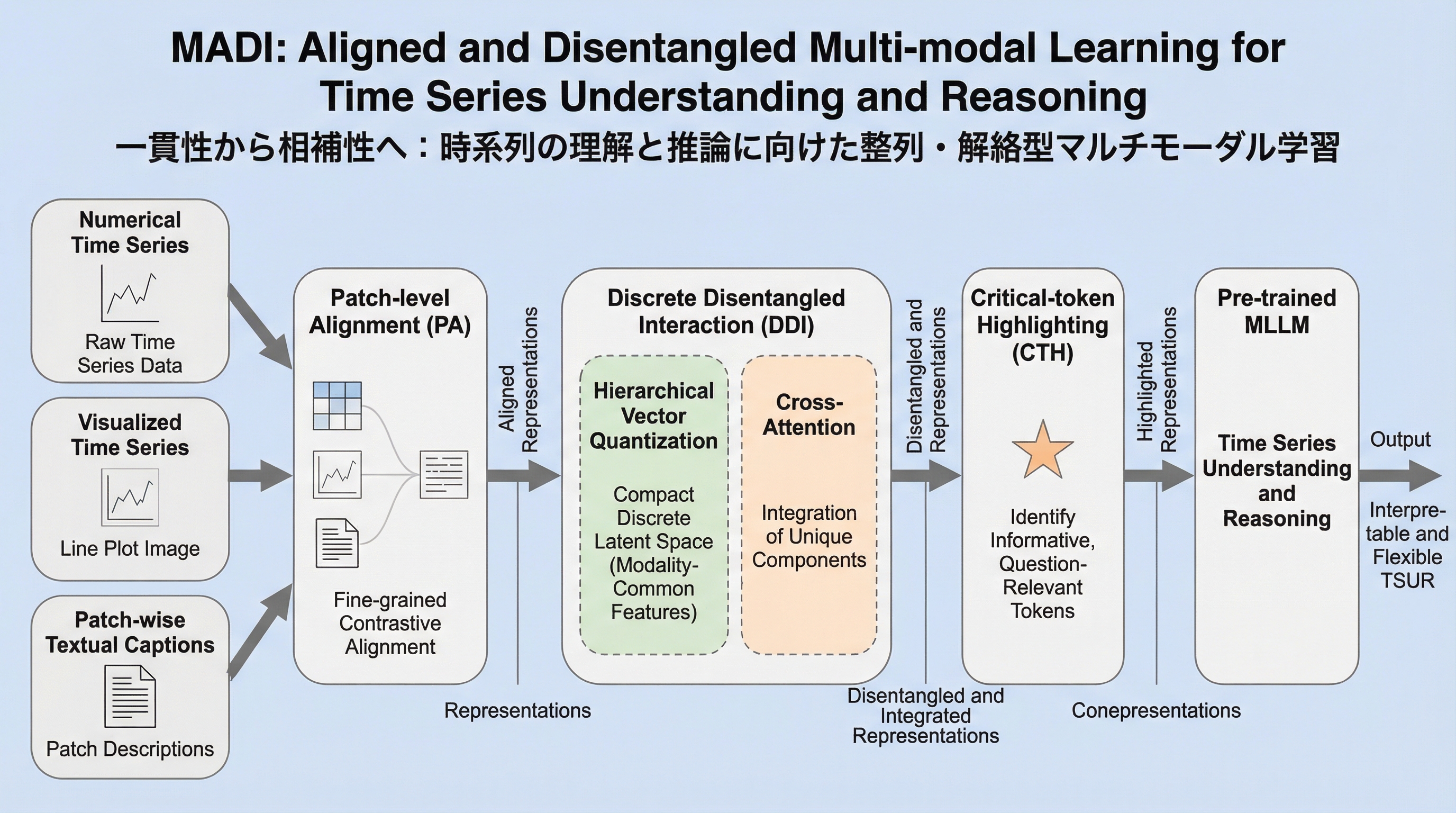
時系列データの数値的な正確性と視覚的な構造把握を両立させるため、パッチ単位での精密な位置合わせを行う「Patch-level Alignment」と、共有情報と固有情報を分離して統合する「Discrete Disentangled Interaction」を備えたマルチモーダル大型言語モデル「MADI」が提案されました。 このモデルは、数値データ、プロット図、統計テキストを物理的に対応付けることで、従来のモデルが抱えていた局所的なハルシネーションを抑制し、トレンドや周期性といった高レベルな特徴と微細な数値変動の両方を正確に捉えることに成功しています。 合成データおよび医療や金融などの現実世界のデータセットを用いた広範な検証の結果、MADIは汎用的な言語モデルや時系列特化型の既存モデルを一貫して上回る性能を示し、複雑な時間的動態に対する柔軟で解釈可能な推論能力を証明しました。
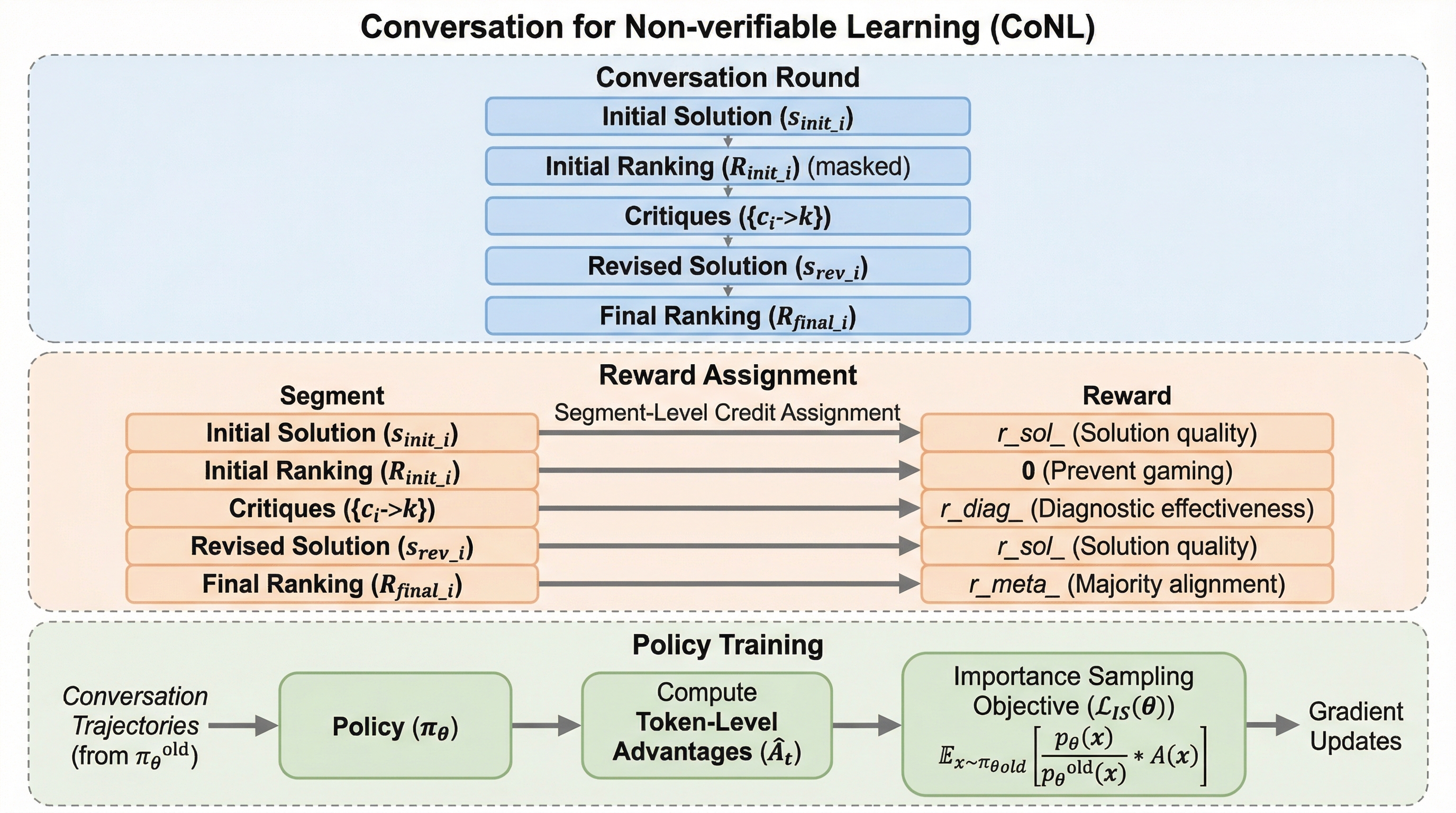
クリエイティブな執筆や倫理的推論といった正解が検証不可能なタスクにおいて、大規模言語モデルを訓練することは、客観的な正解ラベルが存在しないため非常に困難である。既存の「LLM-as-Judge」手法は評価者自身の能力やバイアスに性能が制限されるという課題を抱えていたが、本研究は他者の回答を改善させたかどうかで批判の質を測定する「診断的報酬」を導入した。 提案手法「CoNL」は、マルチエージェントの自己対話を通じて生成、評価、メタ評価を統合するフレームワークであり、外部の評価者や正解データに頼ることなく、対話の力学から得られる信号を用いてモデルを自律的に進化させる。5つのベンチマークを用いた実験の結果、CoNLは従来の自己報酬型手法を最大8.3パーセント上回る性能向上を達成し、学習の安定性を維持しながら正解報酬を用いた強化学習に近い成果を収めた。 この手法は、ピアレビューのような相互監視のプロセスを学習信号に変えることで、検証不可能な領域におけるモデルの限界を突破し、より高品質で信頼性の高い回答の生成を可能にするものである。従来の自己報酬型モデルが陥りがちだった回答の肥大化(冗長性バイアス)を抑制し、評価能力そのものを訓練可能なスキルとして定義した点に大きな革新性がある。
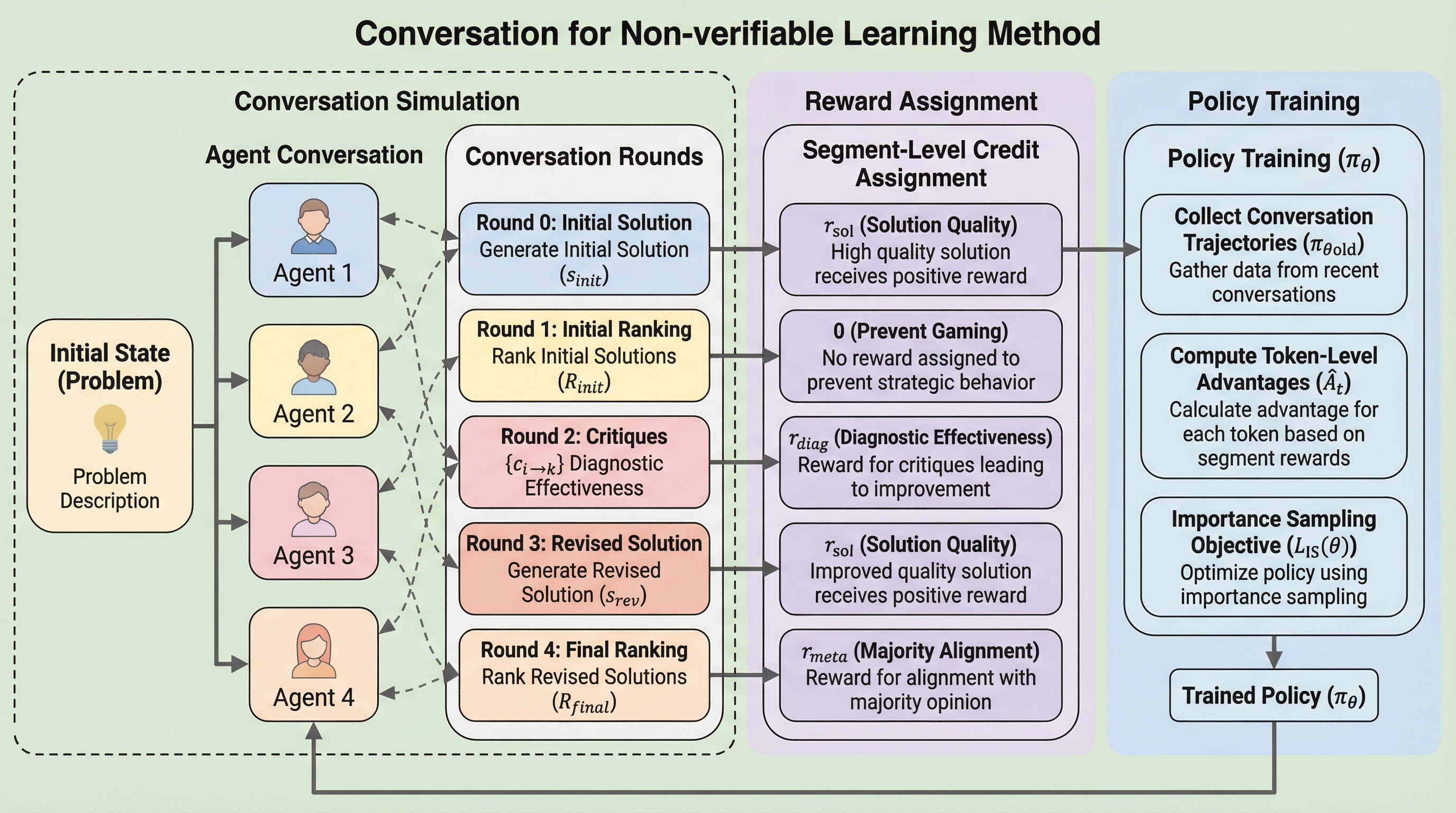
数学やプログラミングのような明確な正解がない「検証不可能なタスク」において、大規模言語モデル(LLM)が自身の評価能力を自律的に向上させるための新しい学習フレームワーク「CoNL」が提案されました。
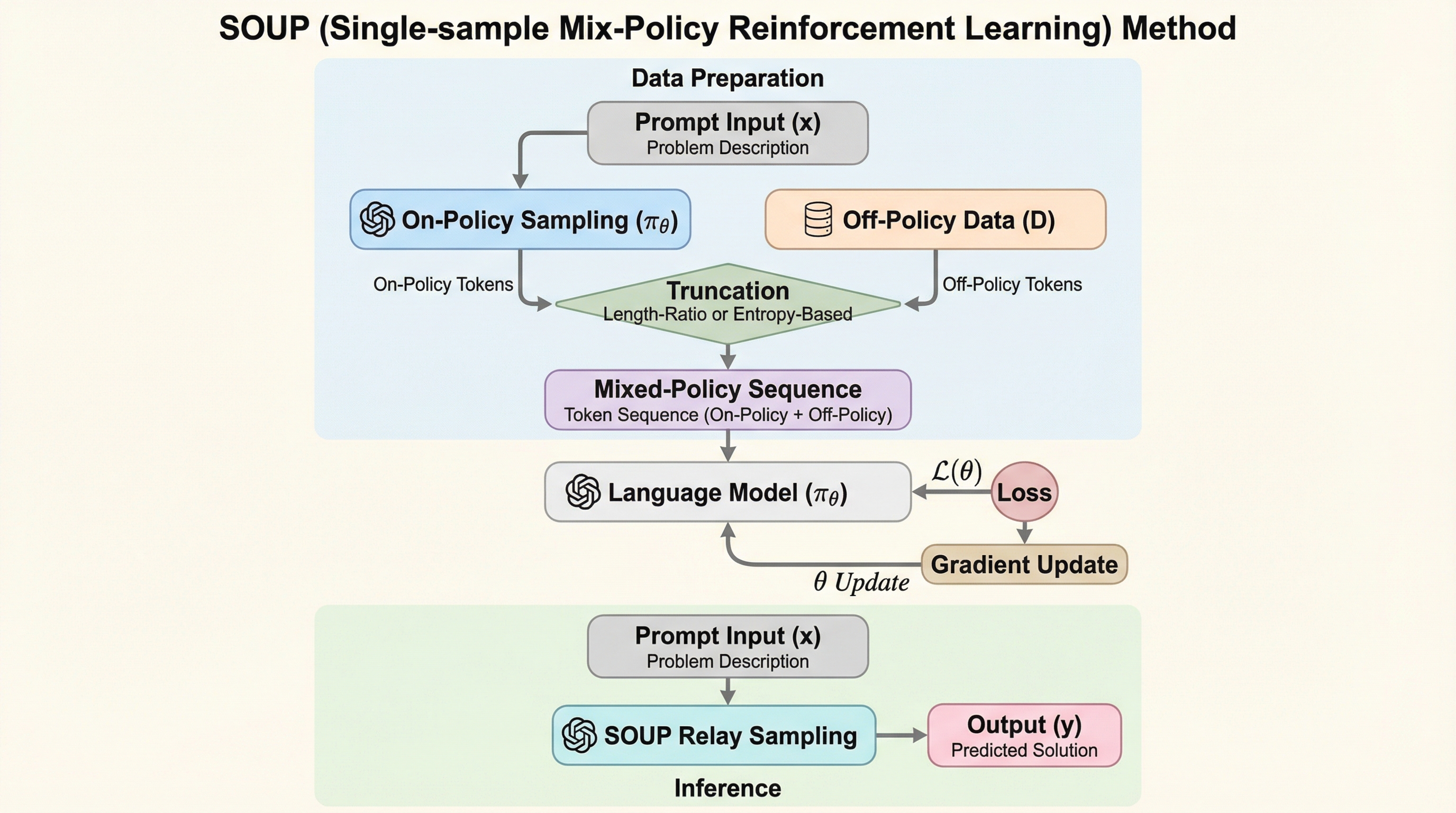
大規模言語モデルの強化学習において、従来のオンポリシー手法が抱えていた「探索の多様性の欠如」と、既存のオフポリシー手法が抱えていた「学習の不安定性」という二律背反の課題を解決するため、単一のサンプル内で過去のポリシーと現在のポリシーをトークン単位で統合する新フレームワーク「SOUP」が提案されました。