動的モデル補間によるシステム1と2の相乗効果
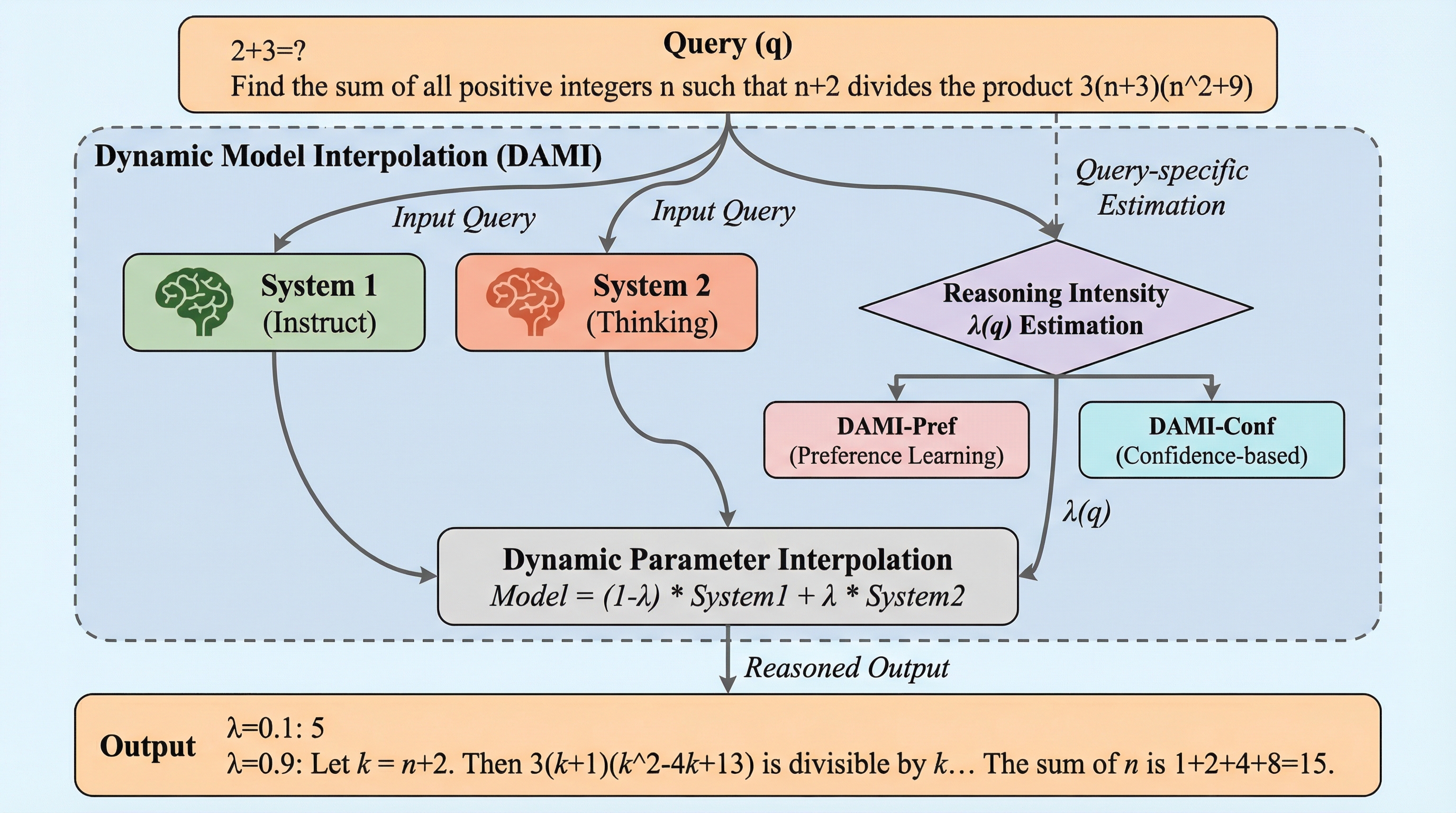
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合するため、出力の長さではなく「思考能力」そのものを制御する動的モデル補間手法「DAMI」が提案されました。 既存の指示追従モデルと推論モデルのパラメータを線形補間することで、追加学習なしにクエリごとの最適な推論強度を調整し、表現空間の連続性と構造的結合性を維持しながら性能を制御することが可能です。 数学的推論ベンチマークにおいて、従来の推論モデルより高い精度を維持しつつ、トークン消費量を29〜40%削減することに成功し、効率性と推論の深さの最適なバランスを実現しました。
TL;DR(結論)
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合するため、出力の長さではなく「思考能力」そのものを制御する動的モデル補間手法「DAMI」が提案されました。 既存の指示追従モデルと推論モデルのパラメータを線形補間することで、追加学習なしにクエリごとの最適な推論強度を調整し、表現空間の連続性と構造的結合性を維持しながら性能を制御することが可能です。 数学的推論ベンチマークにおいて、従来の推論モデルより高い精度を維持しつつ、トークン消費量を29〜40%削減することに成功し、効率性と推論の深さの最適なバランスを実現しました。
なぜこの問題か
現在の大規模言語モデル(LLM)の発展において、軽量で迅速な応答を得意とする「システム1」的な挙動と、複雑な推論ステップを経て高い精度を実現する「システム2」的な挙動の使い分けが重要な課題となっています。理想的には、単純な質問には素早く答え、難解な問題には深く思考する統一されたモデルが求められますが、これらを同時に学習させることは困難です。その理由は、簡潔な応答を求めるデータと詳細な思考プロセスを伴うデータの間に「ゼロサム」的な干渉が発生し、一方の性能が向上すると他方が低下するというトレードオフが生じるためです。このため、現在の最先端モデルの多くは、思考用と指示追従用で別々のチェックポイントとして公開されるのが一般的となっています。 これまでの研究では、システム2モデルの効率を高めるために「出力制御」というアプローチが取られてきました。具体的には、トークン数の制限、早期終了、あるいは強化学習による長さのペナルティ付与などが試みられてきました。しかし、本論文の著者らは、出力の長さはモデルの認知構成の結果として現れる「症状」に過ぎず、根本的な原因ではないと指摘しています。…
核心:何を提案したのか
本研究では、出力の長さではなくモデルの認知能力を直接制御する「能力制御(Capability Control)」という概念を導入し、それを実現するためのフレームワーク「DAMI(Dynamic Model Interpolation)」を提案しました。DAMIの核心は、既存の「指示追従(Instruct)モデル」と「思考(Thinking)モデル」という2つの異なるチェックポイントのパラメータを、クエリごとに動的に補間(インターポレーション)することにあります。これにより、追加の学習コストをかけることなく、モデルの推論強度を連続的に調整することが可能になります。 著者らは予備調査において、パラメータの線形補間がモデルの挙動にどのような影響を与えるかを詳細に分析しました。その結果、補間係数(λ)を0(指示追従モデル)から1(思考モデル)の間で変化させると、精度と効率の間に滑らかで単調なパレート境界が形成されることを発見しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related