帰属と事実検証のためのユーザー中心の証拠ランキング
大規模言語モデル(LLM)のハルシネーション対策として、情報の信頼性を評価するための証拠提示と事実検証が重要視されていますが、既存の自動システムはユーザーに対して不十分な情報や過剰に冗長な情報を提示しがちであり、検証作業の効率を下げて誤りを誘発する原因となっています。
TL;DR(結論)
大規模言語モデル(LLM)のハルシネーション対策として、情報の信頼性を評価するための証拠提示と事実検証が重要視されていますが、既存の自動システムはユーザーに対して不十分な情報や過剰に冗長な情報を提示しがちであり、検証作業の効率を下げて誤りを誘発する原因となっています。 本研究では、検証に必要な十分な情報をランキング形式で可能な限り早期に提示する「証拠ランキング(Evidence Ranking)」という新しいタスクを提案し、ユーザーがリストを順次読み進める際に最小限の読解努力で事実の正誤を判断できる仕組みを構築するとともに、既存のデータセットを統合した評価ベンチマークを開発しました。 多様なモデルを用いた実験の結果、証拠を逐次的に選択するインクリメンタルなランキング戦略が補完的な証拠を捉えるのに有効であり、特にLLMベースの手法がMRR 0.75という高い性能を達成して、従来の証拠選択手法と比較してユーザーの読解負担を軽減しつつ検証の正確性を向上させることが実証されました。
なぜこの問題か
大規模言語モデル(LLM)は、一見すると説得力があるものの、信頼できる証拠に基づかない主張、いわゆるハルシネーションを生成することが頻繁にあります。このような現象は誤情報の拡散を招き、ユーザーが提示された内容の真偽を判断することを困難にしています。この問題に対処するため、LLMには自己引用などの証拠を付与して主張の根拠を示すことが求められていますが、ユーザーはその証拠を実際に読み込んで内容を確認しなければなりません。同様の課題は、自動ファクトチェックシステムを利用する人間のファクトチェッカーにも共通しており、膨大な情報の中から主張を裏付ける、あるいは反論するための最小限の証拠を特定することが求められています。 しかし、従来の証拠選択システムには大きな課題が存在します。現在の多くのシステムは、証拠となる文を「選択するかしないか」というバイナリ(二値)の判断に基づいています。このアプローチでは、適合率(Precision)を高めようとすると重要な証拠を切り捨ててしまうリスクがあり、逆に再現率(Recall)を高めようとするとユーザーに過剰な情報を提示してしまい、検証作業を煩雑にするというトレードオフが生じます。…
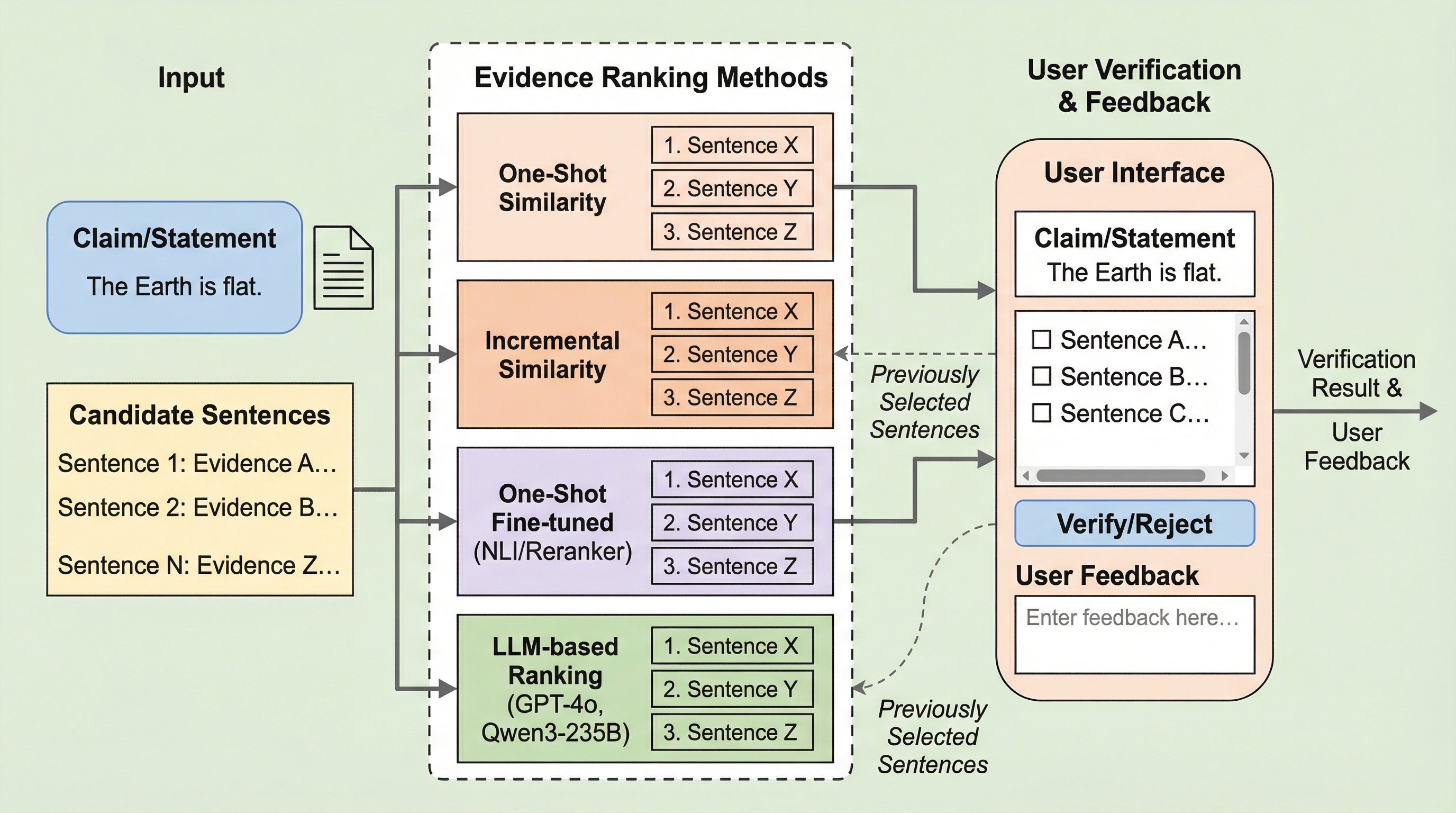
核心:何を提案したのか
本研究の核心的な提案は、証拠選択を従来の二値分類タスクから、ユーザーの利便性を最優先した「ランキングタスク」へと再定義したことです。これを「証拠ランキング(Evidence Ranking)」と呼びます。このタスクの目的は、候補となるすべての証拠文に対してグローバルな順位付けを行い、主張を検証するために「十分な」証拠のセットがランキングの可能な限り上位に現れるようにすることです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related