帰属と事実検証のためのユーザー中心の根拠ランキング
大規模言語モデル(LLM)が生成する情報の信頼性を評価するため、従来の「証拠選択」に代わる新しいタスクとして「証拠ランキング」を提案しました。これは、ユーザーが主張の正誤を判断するために必要な最小限の情報を、順位付けされたリストのなるべく早い段階で提示することを目指すもので、ユーザーの読解努力を最小化しつつ、すべての証拠へのアクセスを維持します。 本研究では、一度に順位を付けるワンショット型と、既に出した証拠を考慮しながら順次選ぶインクリメンタル型の2つの手法を比較し、既存の事実検証データセットを統合した新しいベンチマークと評価指標を構築しました。評価には、ユーザーの読解効率を測定するために情報検索の指標を応用したMRR(平均逆順位)などが導入されており、システムがどれだけ早く十分な証拠を提示できるかを定量化しています。 実験の結果、LLMを用いた手法がMRR 0.75という最も高い性能を示し、特にインクリメンタルな戦略が補完的な証拠を効率的に提示できることが明らかになりました。ユーザー調査においても、証拠ランキングは従来の選択手法と比較して、読解量を減らしつつ検証の正確性を向上させることが実証されており、より解釈可能で効率的、かつユーザーの利便性に沿った情報検証システムの基盤となります。
TL;DR(結論)
大規模言語モデル(LLM)が生成する情報の信頼性を評価するため、従来の「証拠選択」に代わる新しいタスクとして「証拠ランキング」を提案しました。これは、ユーザーが主張の正誤を判断するために必要な最小限の情報を、順位付けされたリストのなるべく早い段階で提示することを目指すもので、ユーザーの読解努力を最小化しつつ、すべての証拠へのアクセスを維持します。 本研究では、一度に順位を付けるワンショット型と、既に出した証拠を考慮しながら順次選ぶインクリメンタル型の2つの手法を比較し、既存の事実検証データセットを統合した新しいベンチマークと評価指標を構築しました。評価には、ユーザーの読解効率を測定するために情報検索の指標を応用したMRR(平均逆順位)などが導入されており、システムがどれだけ早く十分な証拠を提示できるかを定量化しています。 実験の結果、LLMを用いた手法がMRR 0.75という最も高い性能を示し、特にインクリメンタルな戦略が補完的な証拠を効率的に提示できることが明らかになりました。ユーザー調査においても、証拠ランキングは従来の選択手法と比較して、読解量を減らしつつ検証の正確性を向上させることが実証されており、より解釈可能で効率的、かつユーザーの利便性に沿った情報検証システムの基盤となります。
なぜこの問題か
大規模言語モデル(LLM)は、一見するともっともらしいが信頼できる証拠に基づかない主張、いわゆる「ハルシネーション(幻覚)」を引き起こすことが多々あります。このような現象は誤情報の拡散を招き、ユーザーが提示された内容の真偽を判断することを困難にしています。この問題に対処するため、LLMには自己引用などの証拠を付与して主張の根拠を示す「アトリビューション(帰属)」が求められるようになっています。しかし、ユーザーがこれらの証拠を読み込んで内容を確認する作業は、非常に時間がかかり、ミスが発生しやすいという課題があります。 既存の自動事実検証システムやLLMを用いた証拠選択の手法は、主張を支持または反論するための簡潔な証拠を特定することを目指しています。しかし、これらのシステムはユーザーに対して、不十分な情報しか提供できなかったり、逆に過剰で冗長な情報を提示してしまったりすることが頻繁にあります。証拠が不足していれば検証ができず、冗長すぎればユーザーは膨大なテキストを読む負担を強いられます。…
核心:何を提案したのか
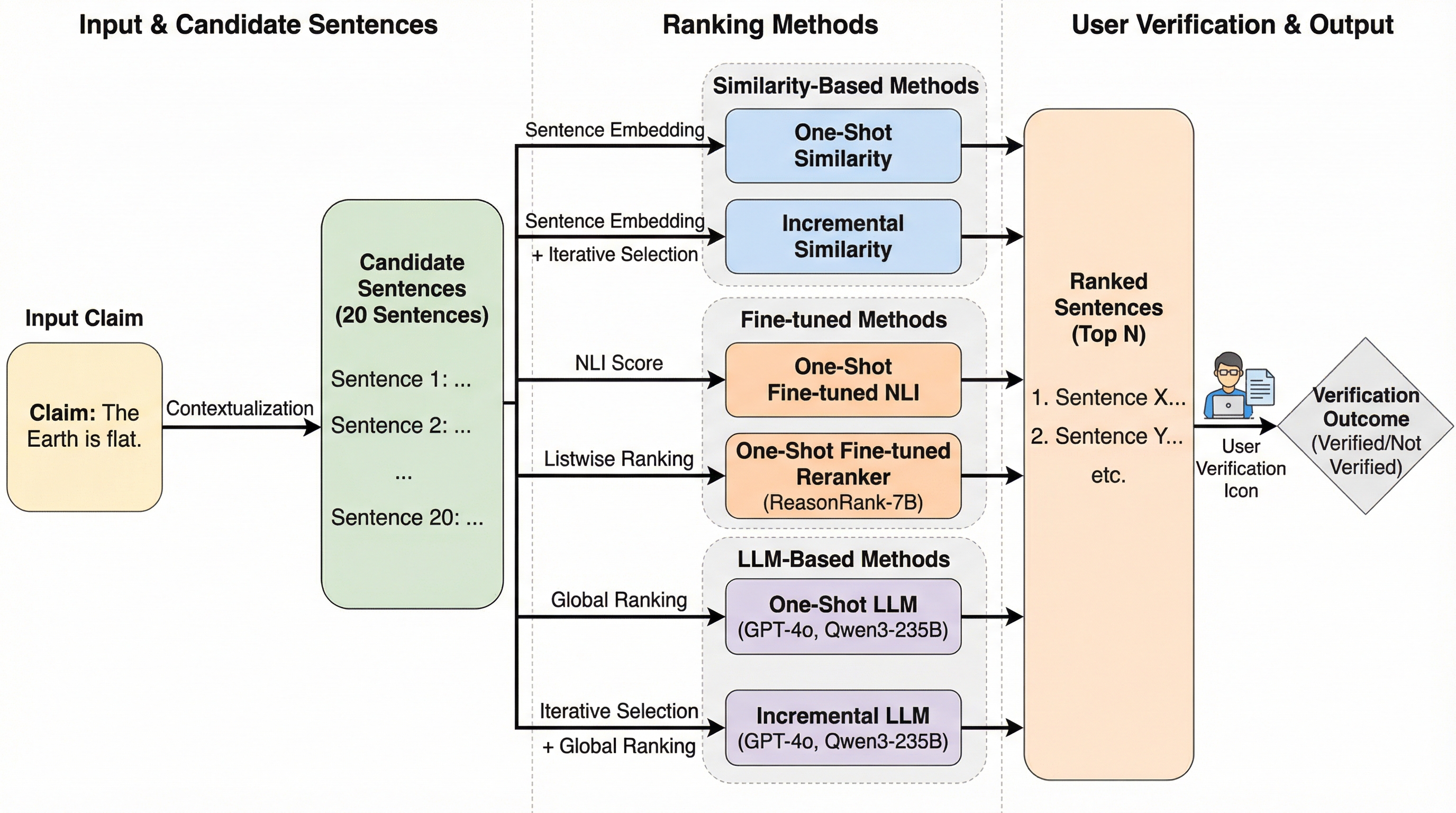
本研究では、従来のバイナリな証拠選択(選ぶか選ばないか)という枠組みを、ユーザーの行動に即した「証拠ランキング」という新しいタスクへと再定義しました。このタスクの目的は、候補となるすべての証拠文に順位を付け、主張の検証に十分な情報のセット(最小十分セット)ができるだけ上位に現れるようにすることです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related