SOUP:大規模言語モデルのためのトークンレベル単一サンプル混合ポリシー強化学習
大規模言語モデルの強化学習において、従来のオンポリシー手法が抱えていた「探索の多様性の欠如」と、既存のオフポリシー手法が抱えていた「学習の不安定性」という二律背反の課題を解決するため、単一のサンプル内で過去のポリシーと現在のポリシーをトークン単位で統合する新フレームワーク「SOUP」が提案されました。
TL;DR(結論)
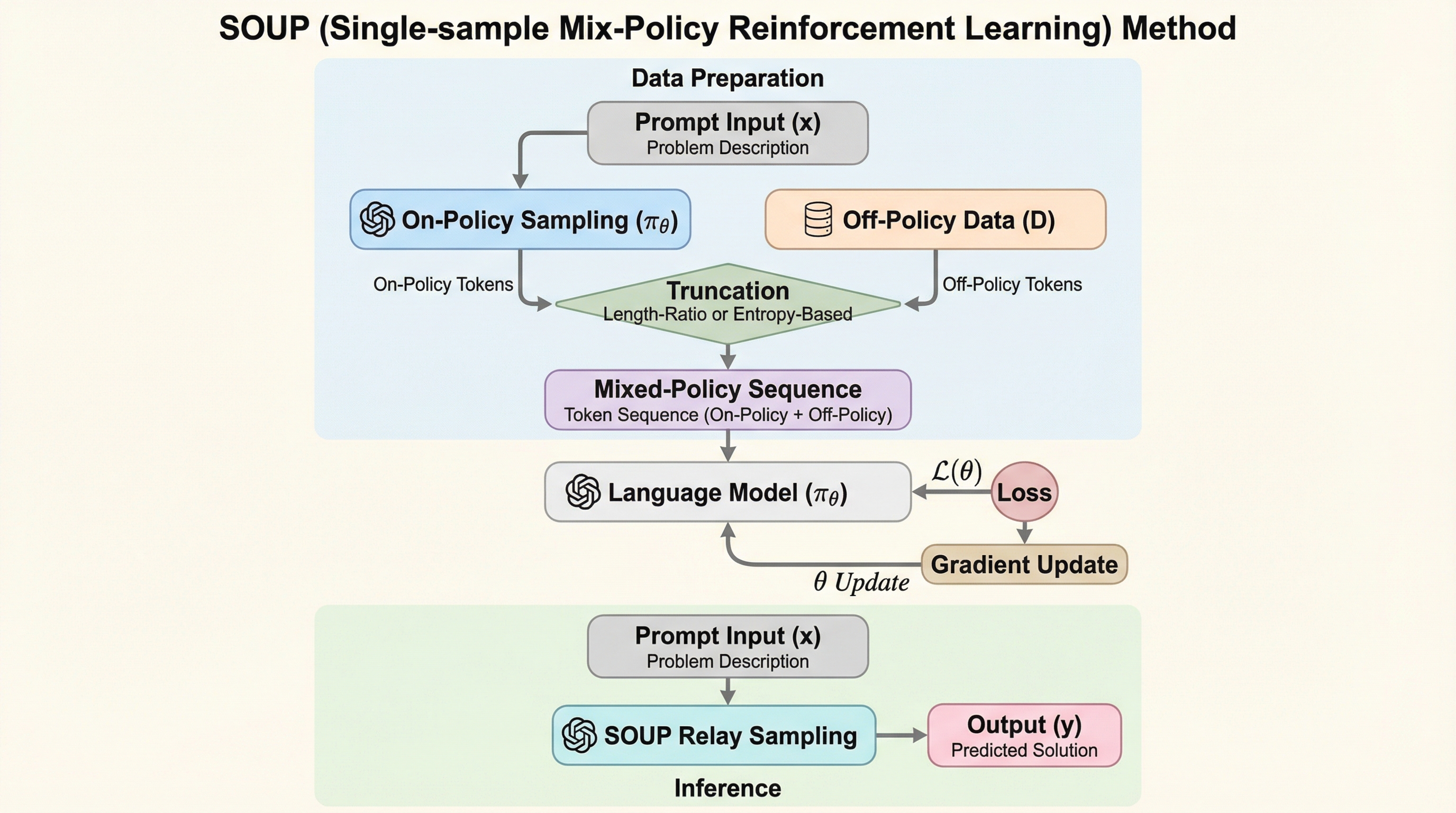
大規模言語モデルの強化学習において、従来のオンポリシー手法が抱えていた「探索の多様性の欠如」と、既存のオフポリシー手法が抱えていた「学習の不安定性」という二律背反の課題を解決するため、単一のサンプル内で過去のポリシーと現在のポリシーをトークン単位で統合する新フレームワーク「SOUP」が提案されました。 この手法は、生成されるシーケンスの前半部分(プレフィックス)を過去の履歴ポリシーからサンプリングし、後半部分(コンティニュエーション)を現在の最新ポリシーで生成することで、オフポリシーによる広範な探索とオンポリシーによる安定した最適化を同一サンプル内で両立させることに成功しています。 数学的推論ベンチマークを用いた実験では、Qwen2.5-Math-7BやDeepSeek-R1-Distill-Qwen-1.5Bといったモデルにおいて、標準的なオンポリシー学習や既存のオフポリシー拡張手法であるLUFFYやM2POを安定して上回る性能を記録し、学習の収束速度と最終的な推論精度の両面で有効性が確認されました。
なぜこの問題か
大規模言語モデル(LLM)のポストトレーニングにおいて、人間のフィードバックや検証可能な報酬を用いた強化学習(RL)は、モデルの性能を向上させるための中核的な技術となっています。特に、価値関数ネットワークの訓練を不要にするGroup Relative Policy Optimization(GRPO)などの手法は、計算コストを抑えつつ高い性能を維持できるため、広く注目を集めています。しかし、現在のLLM向け強化学習手法の多くは、現在のポリシーモデルから生成されたサンプルのみを用いて勾配を推定する「オンポリシー」学習に依存しています。このオンポリシー学習には、理論的な収束の保証がある一方で、モデルが既に持っている行動パターンを過剰に強化してしまい、確率の低い未知のサンプルを抑制し続けるという欠点があります。 このサンプリングの多様性の欠如は、モデルの学習が早期に飽和してしまう原因となり、モデルが本来持っている能力の限界を超えて進化することを妨げます。この問題を解決するために、過去のポリシーや外部の強力なモデルから得られた「オフポリシー」データを取り入れる試みも行われていますが、既存の手法には設計上の限界が存在します。…
核心:何を提案したのか
本論文では、オフポリシー学習とオンポリシー学習を単一のサンプル内でトークンレベルで統合する新しいフレームワーク「Single-sample Mix-pOlicy Unified Paradigm(SOUP)」を提案しています。SOUPの核心的なアイデアは、生成されるテキストの「プレフィックス(接頭辞)」部分にのみオフポリシーの影響を限定し、それに続く「コンティニュエーション(継続部分)」をオンポリシーで生成するという戦略にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related