動的モデル補間によるシステム1と2の相乗効果:DAMIフレームワークの提案
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合する際、従来の出力トークン数を制限する手法(出力制御)ではなく、モデルの思考の深さそのものを調整する「能力制御」という新しいパラダイムを提案します。
TL;DR(結論)
大規模言語モデルにおいて、直感的な「システム1」と熟考的な「システム2」を統合する際、従来の出力トークン数を制限する手法(出力制御)ではなく、モデルの思考の深さそのものを調整する「能力制御」という新しいパラダイムを提案します。 既存の指示追従モデルと思考モデルのパラメータを、クエリの難易度に応じて動的に線形補間するフレームワーク「DAMI(Dynamic Model Interpolation)」を開発し、追加学習を一切行わずにモデルの認知強度を連続的に制御することを可能にしました。 数学的推論ベンチマークを用いた検証では、思考モデル単体と比較して、正解率を1.6〜3.4%向上させつつ、トークン消費量を29〜40%も削減することに成功し、推論の効率性と精度の両面で既存のルーティングや静的マージ手法を凌駕する性能を実証しました。
なぜこの問題か
大規模言語モデル(LLM)の進化において、迅速で直感的な応答を返す「システム1」と、長い思考連鎖(Chain-of-Thought)を用いて深い推論を行う「システム2」の使い分けが重要な課題となっています。理想的なモデルは、単純な質問には即座に答え、複雑な問題には時間をかけて熟考するという、人間のような柔軟な認知の切り替えを行うべきです。しかし、単一のモデルでこれら二つのモードを同時に最適化しようとすると、学習データの性質が相反するために「ゼロサム」的な干渉が起こります。具体的には、システム2の冗長で自己反省的なスタイルと、システム1の簡潔なスタイルが互いに性能を削り合ってしまうため、現在の最先端モデルでも思考用と指示追従用のチェックポイントを分けて公開せざるを得ないのが現状です。 この困難に対し、これまでの研究ではシステム2モデルを効率化するために「出力制御」というアプローチが取られてきました。これは、トークン予算の制限、早期終了、あるいは強化学習による長さへのペナルティ付与など、モデルが生成する「結果」を物理的に制限する手法です。…
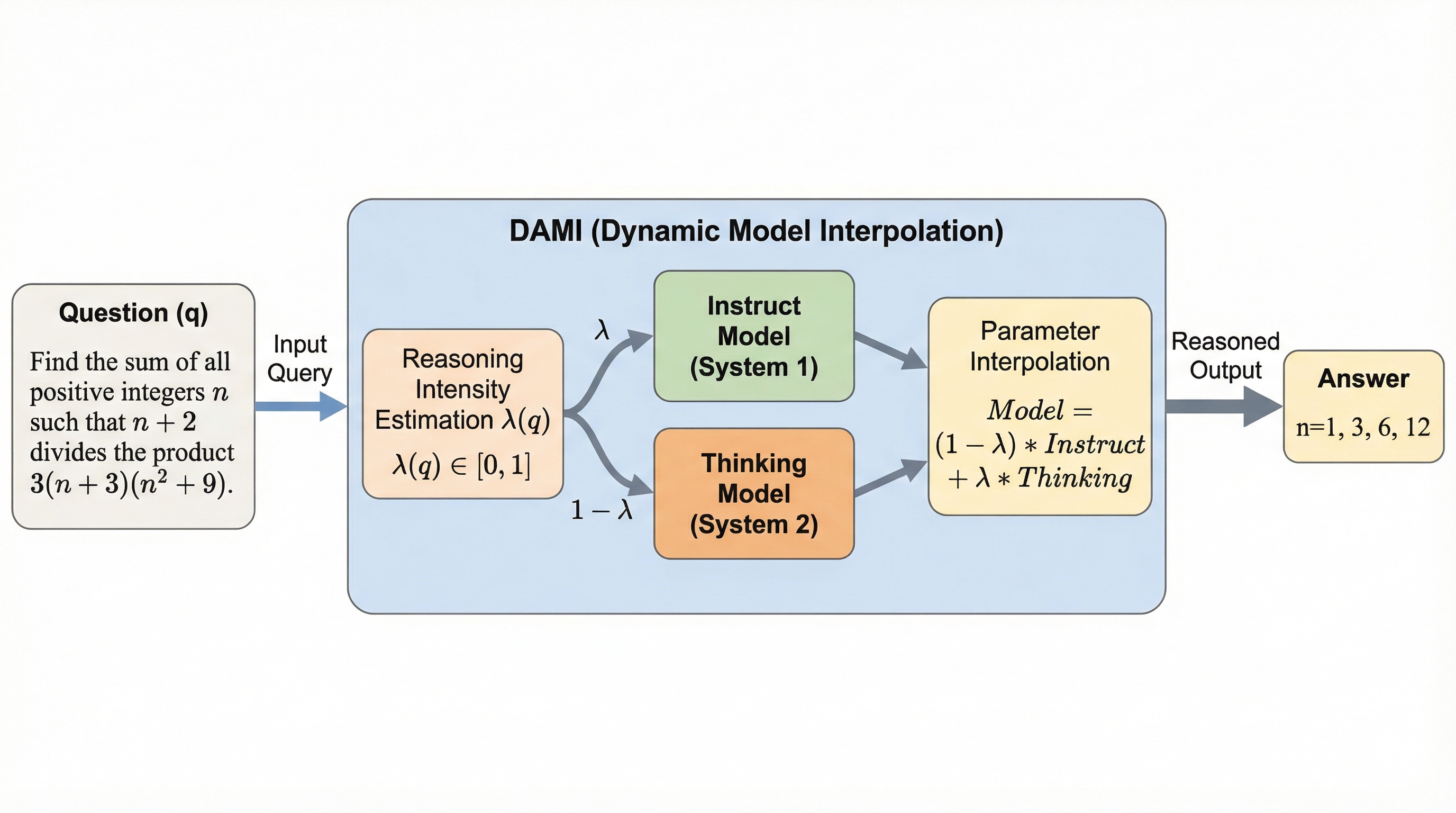
核心:何を提案したのか
本研究は、既存の指示追従モデル(システム1)と思考モデル(システム2)のパラメータを、入力されたクエリごとに動的に補間するフレームワーク「DAMI(Dynamic Model Interpolation)」を提案しました。これは、出力の内容を後から制限するのではなく、モデルの「推論能力」そのものをクエリごとに最適化する「能力制御」という概念を具現化したものです。具体的には、二つのモデルのパラメータを線形補間し、その混合比率を決定する「推論強度(Reasoning Intensity)」という係数λを、入力されるクエリの難易度や性質に応じて動的に推定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related