オンラインとオフラインの“いいとこ取り”:マルチターンコード生成をコンテキスト付きバンディットで学習する
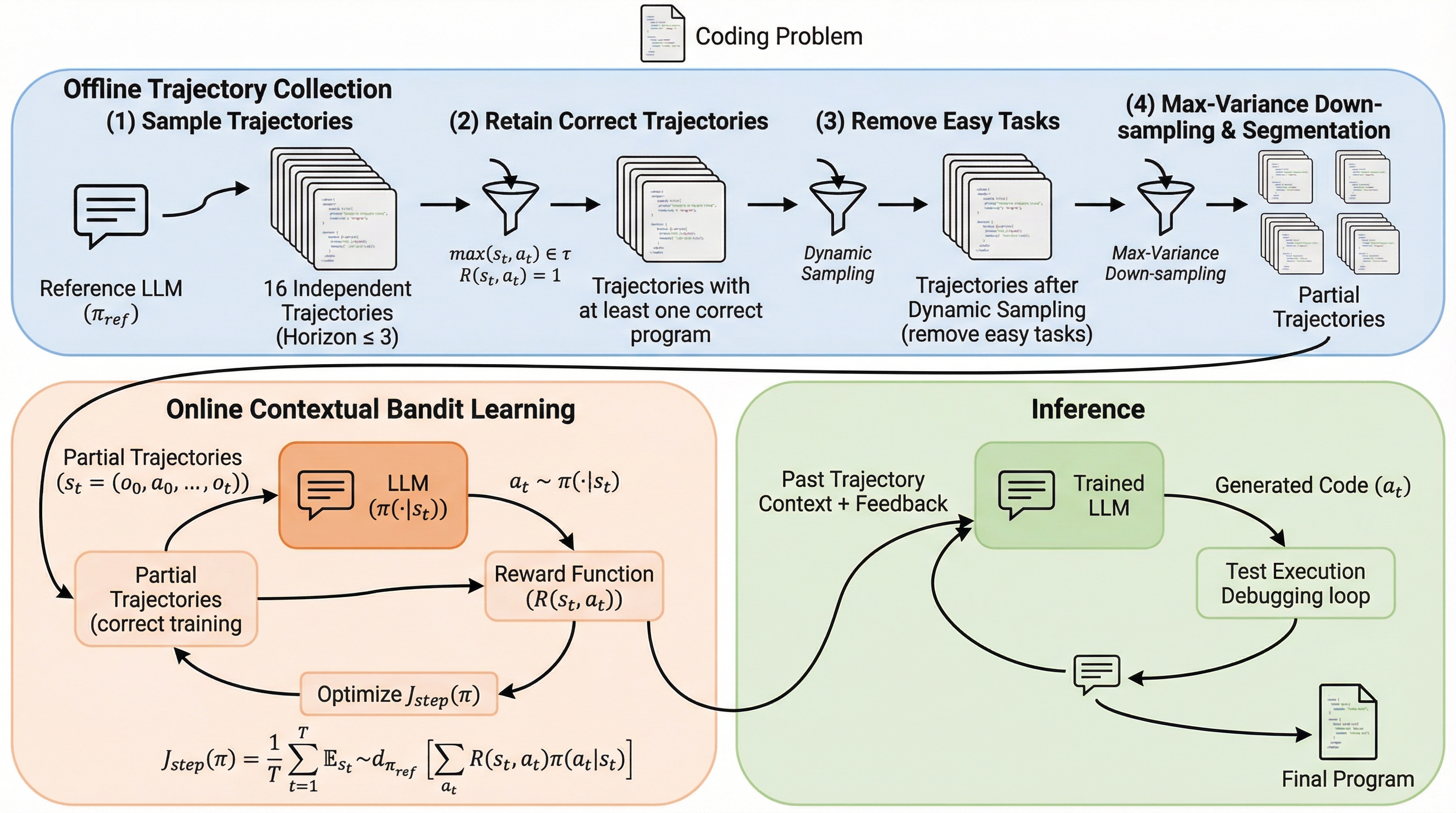
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。
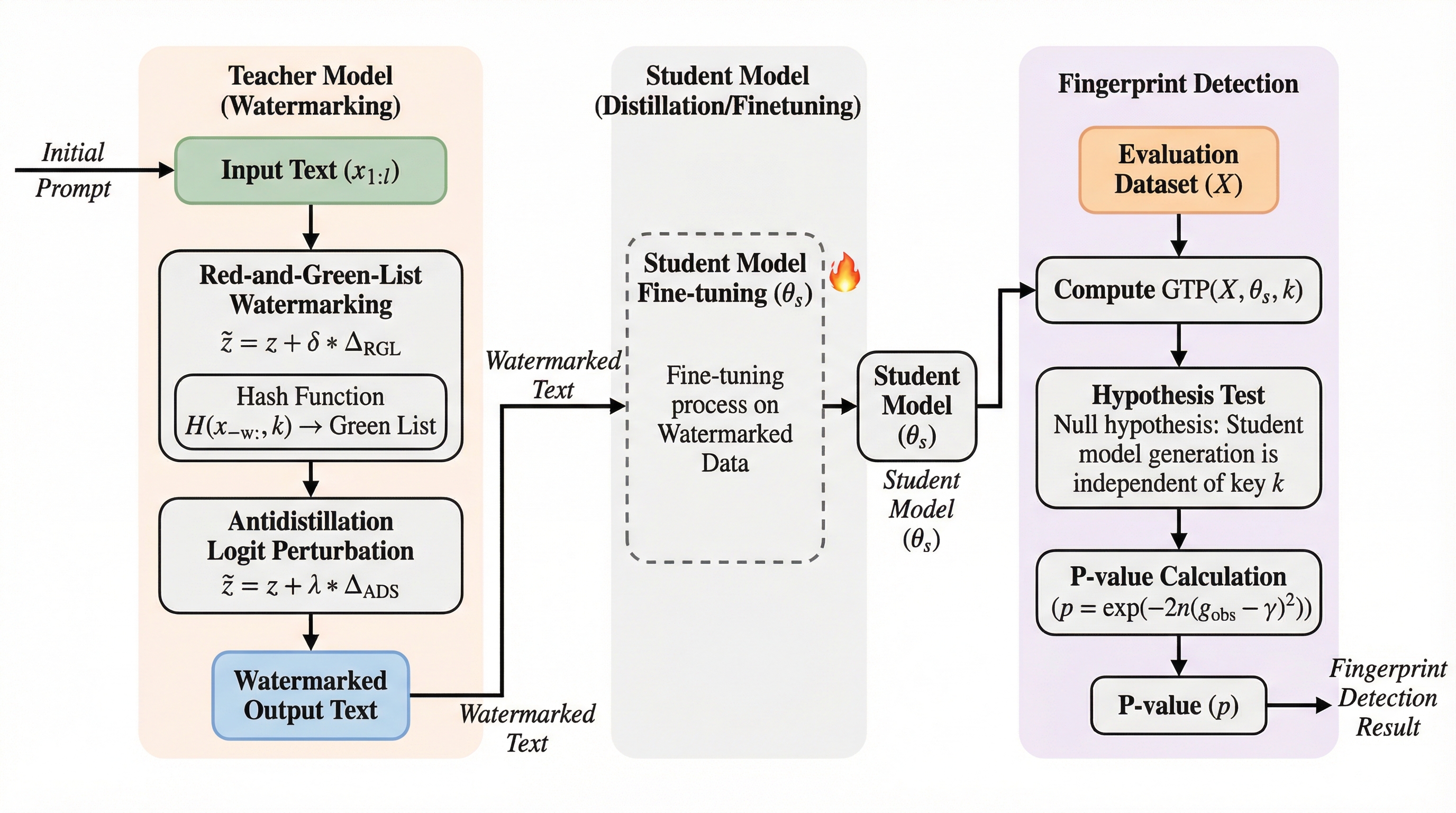
大規模言語モデル(LLM)の出力を無断で学習して模倣する「モデル蒸留」を検知するため、生徒モデルの学習力学に適合した信号を埋め込む新手法「ADFP」が提案されました。 従来のウォーターマーク手法は生成品質を大幅に低下させる課題がありましたが、ADFPはプロキシモデルを用いて検知可能性を最大化するトークンを動的に選択することで、品質維持と強力な検知能力を両立します。 数学的推論(GSM8K)や対話タスク(OASST1)の検証において、生徒モデルの構造が未知であっても、従来手法を凌駕する精度で蒸留の有無を判定できることが実証されました。
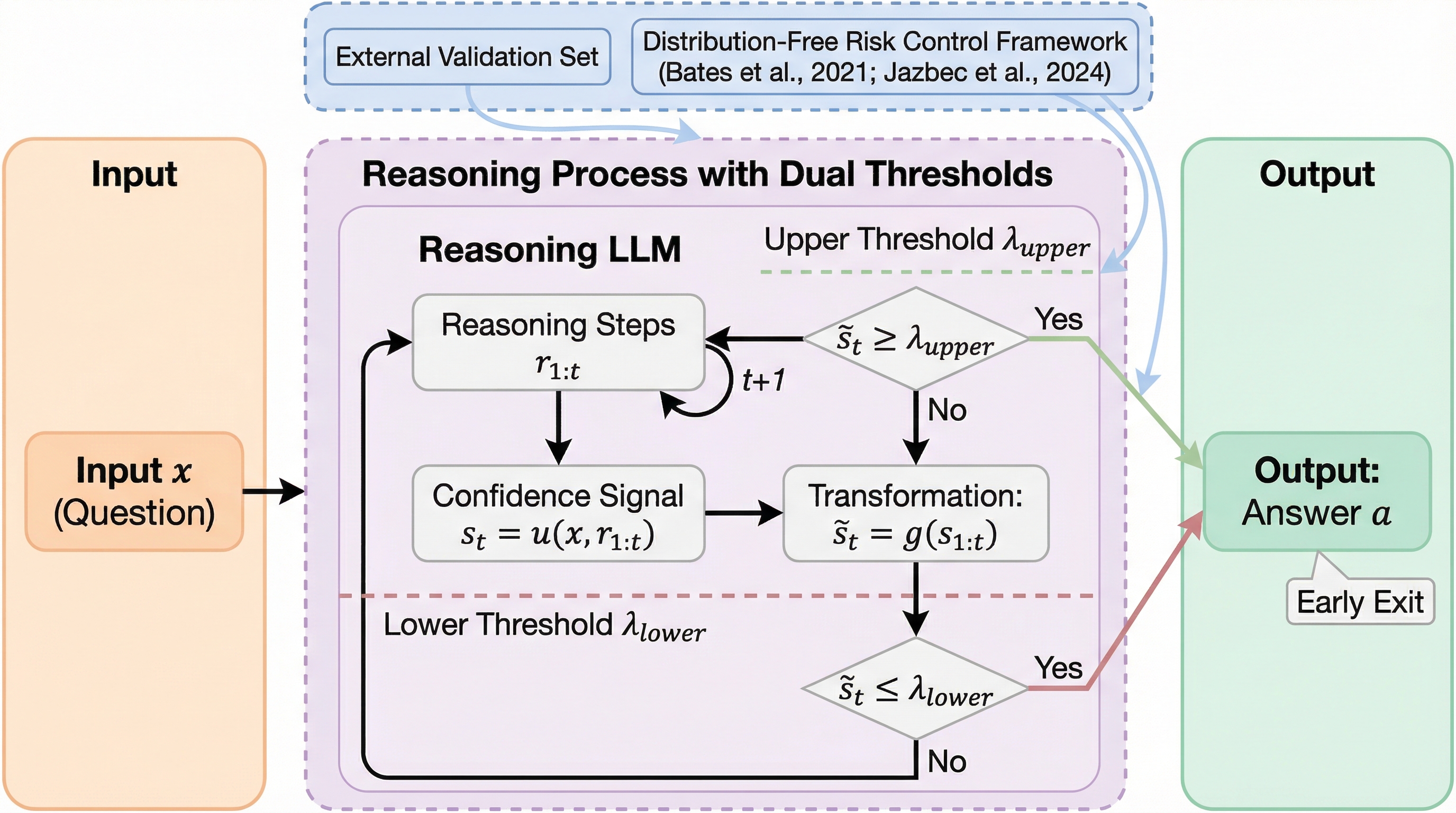
推論LLMは、どこまで考えさせれば“十分”なのでしょうか? 実は「トークン数を決める問題」は、しきい値を決める問題に姿を変えるだけで、悩みは残ります。 この記事では、計算予算の設定を“リスク(誤り率)制御”に言い換える論文の狙いと仕組みを追います。
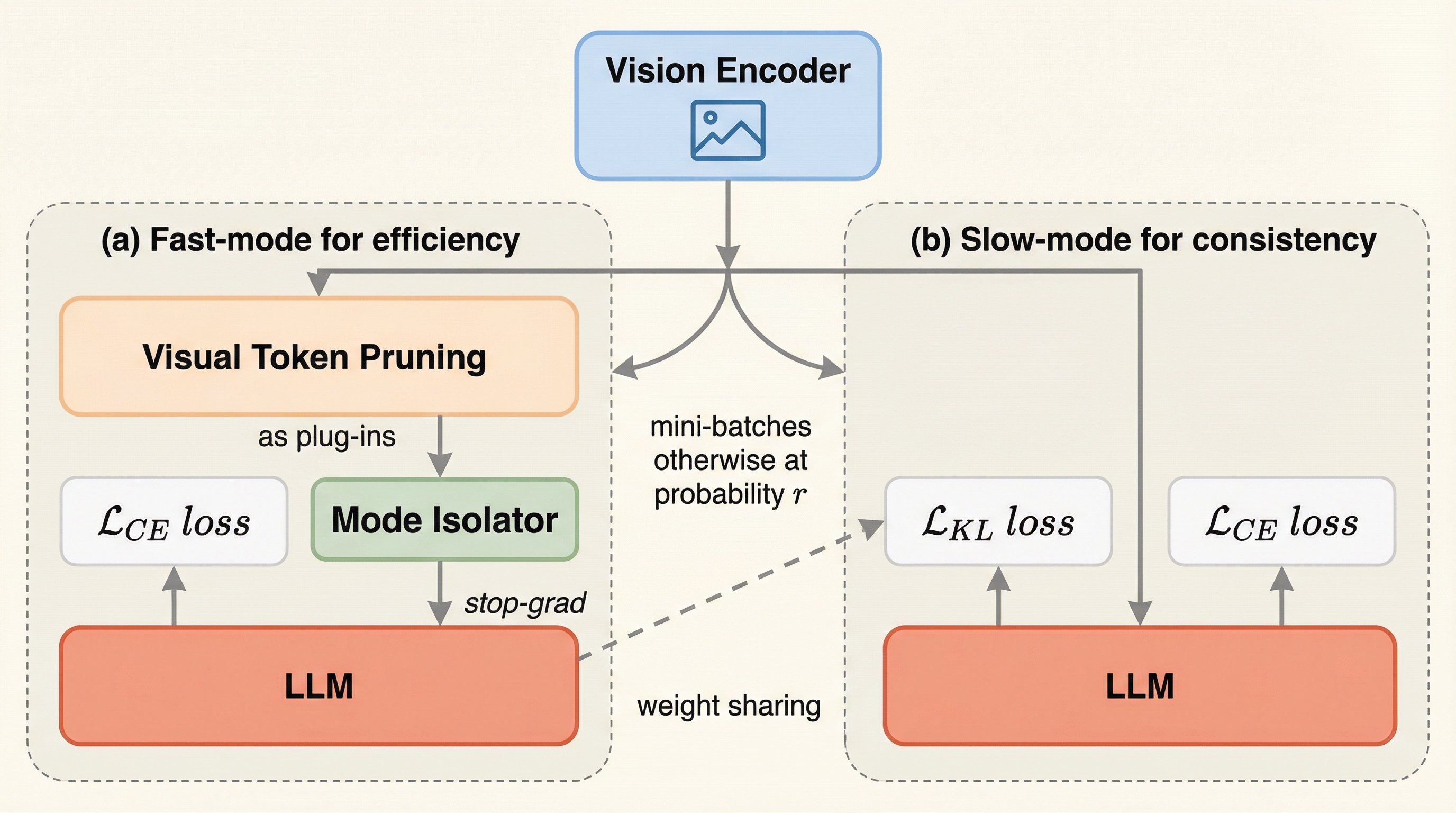
マルチモーダルLLMは、なぜ「学習」だけがこんなに重くなりがちなのでしょうか? 鍵はモデルの巨大さだけでなく、画像が生む“視覚トークンの多さ”にあります。 とはいえ、ただ削れば速くなる一方で、推論の場面で別の問題が噴き出す——そこが話を難しくします。
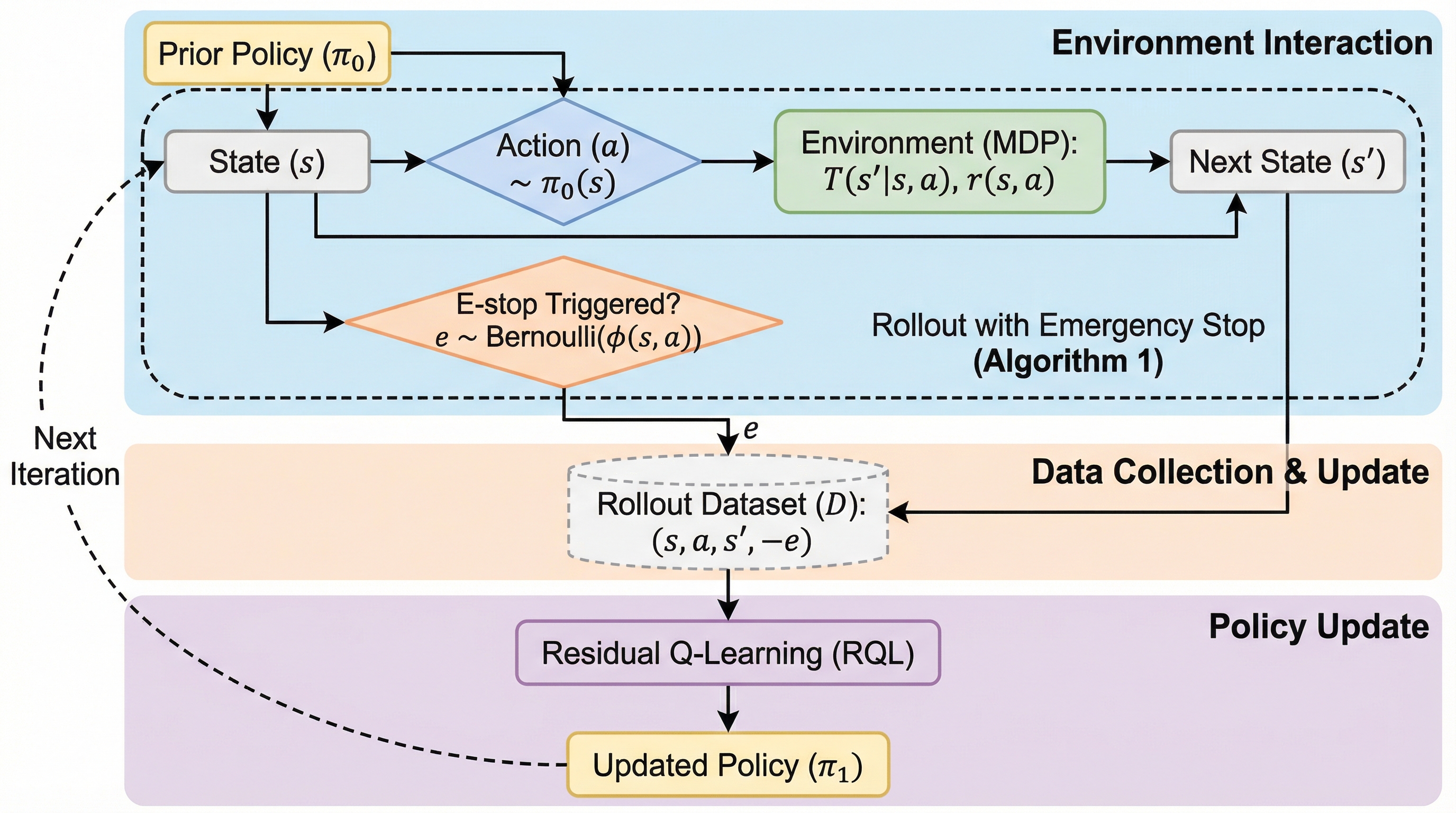
「危ない!」という緊急停止(e-stop)しか手がかりがないとき、ロボットは本当に上達できる? しかも現場で起きるのは、丁寧な指示や正解例ではなく、とっさの停止や介入であることが多いはずです。 実は、“止められないようにする”だけでは、うまくいくとは限りません。
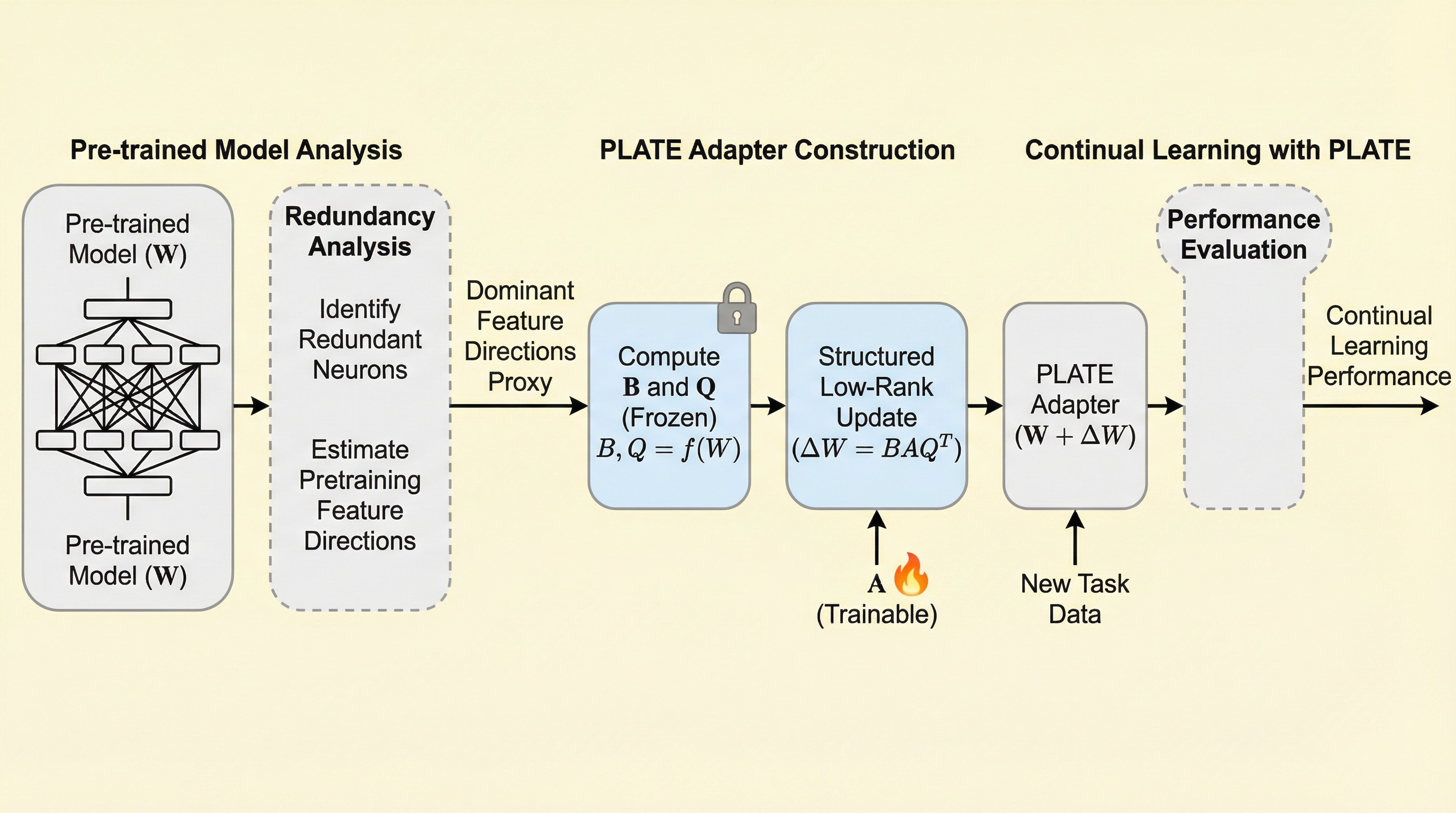
継続学習で「昔のタスクのデータなし」に、どうやって忘却を防ぐのでしょうか。 鍵は追加データでも特別な記憶でもなく、事前学習済みネットワークに潜む“幾何学的な余り”でした。 この記事では、PLATEがどんな発想で更新を制御し、可塑性と保持のトレードオフを扱おうとしているのかを追います。
「このタスク、どのLLMを使うのが正解?」 高いモデルほど良さそう──でも“何が得意か”が見えないまま、お金だけが溶ける。 この記事では、スキルの粒度でモデルを選び、しかも理由を言葉で説明する枠組み「BELLA」を読み解く。選択の精度だけでなく、選択そのものを信じられる形に整える、という発想に焦点を当てる。
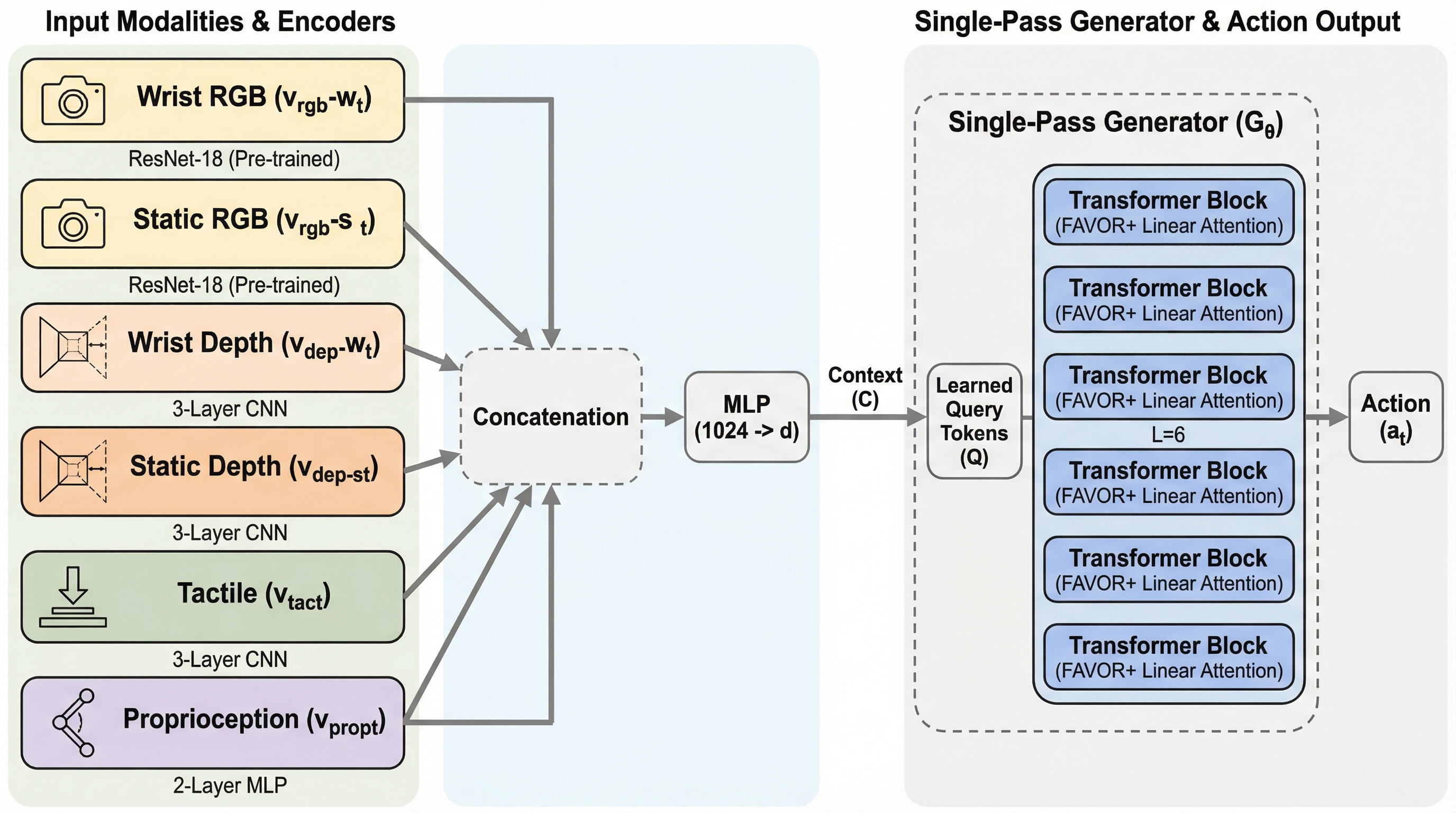
PRISMは、拡散モデルのような反復的な計算を必要とせず、単一のパスで多感覚情報を統合して複雑な動作を生成する新しい模倣学習フレームワークである。 バッチ全体での棄却サンプリング(Batch-global RS-IMLE)と線形注意機構(Performer)を組み合わせることで、リアルタイム性と多様な行動分布の表現を高い次元で両立することに成功した。 実際のロボットやシミュレーションにおいて、従来の拡散ポリシーを成功率で10〜25%上回り、動作の滑らかさを20〜50倍向上させつつ、30〜50Hzの高速な閉ループ制御を実現している。
本研究は、能動学習の初期段階で重要となるシードデータの選択を最適化するため、既存の関連データセットから得られる知識を転移させる新手法「Active-Transfer Bagging(ATBagging)」を提案した。
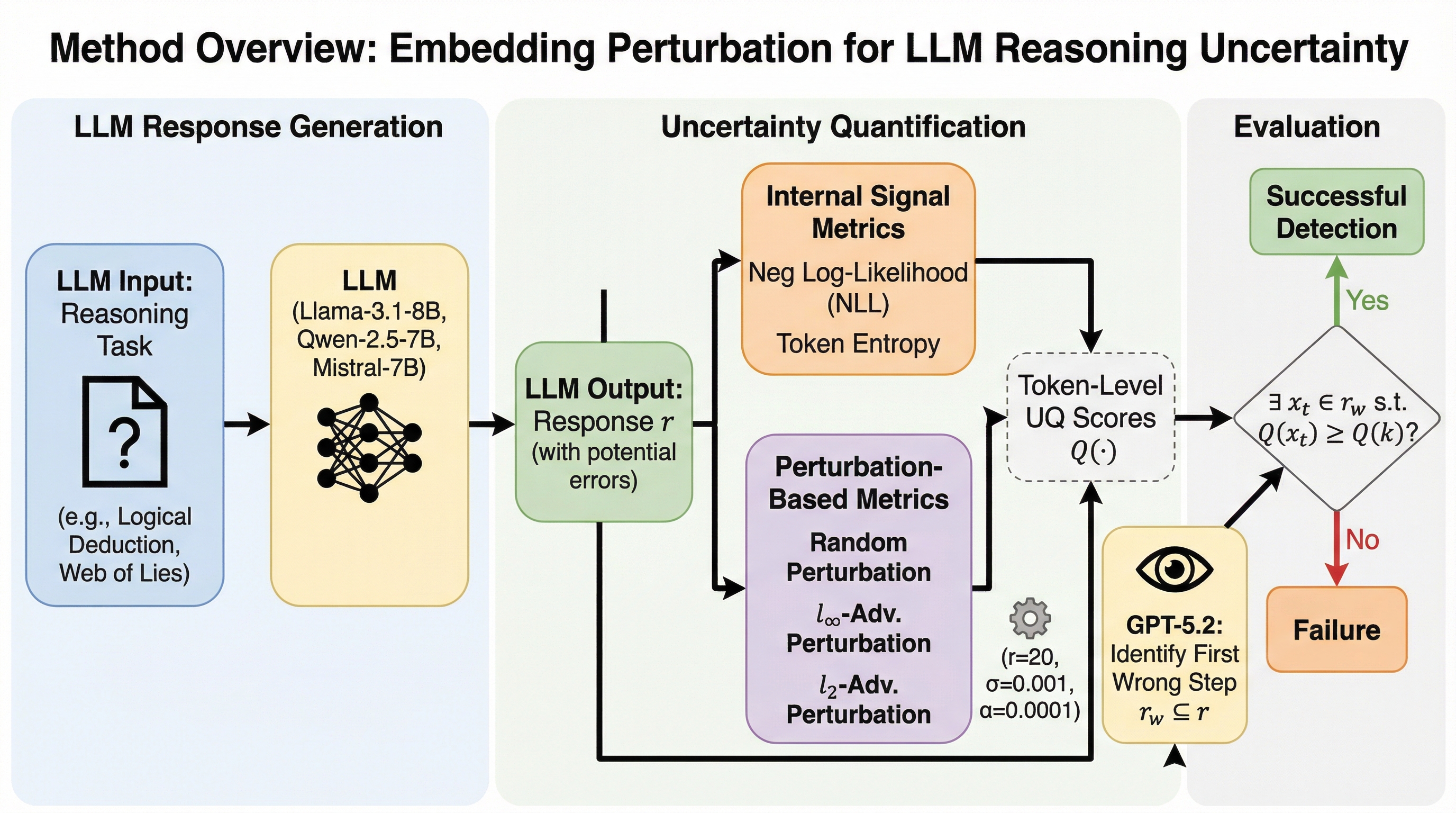
LLMが答えを間違えるとき、どの“推論の一歩”から崩れたのかを見分けられる? 実は「答えの自信」より、「途中のトークンがどれだけ揺れやすいか」が手がかりになるかもしれません。 この記事では、埋め込み摂動によるトークン単位UQが“中間の不確かさ”をどう捉えるのかを読み解きます。