アクティブ・トランスファー・バギング:転移学習とバギングに基づくモデルの組み合わせによる、能動学習のデータ取得を加速する新手法
本研究は、能動学習の初期段階で重要となるシードデータの選択を最適化するため、既存の関連データセットから得られる知識を転移させる新手法「Active-Transfer Bagging(ATBagging)」を提案した。
TL;DR(結論)
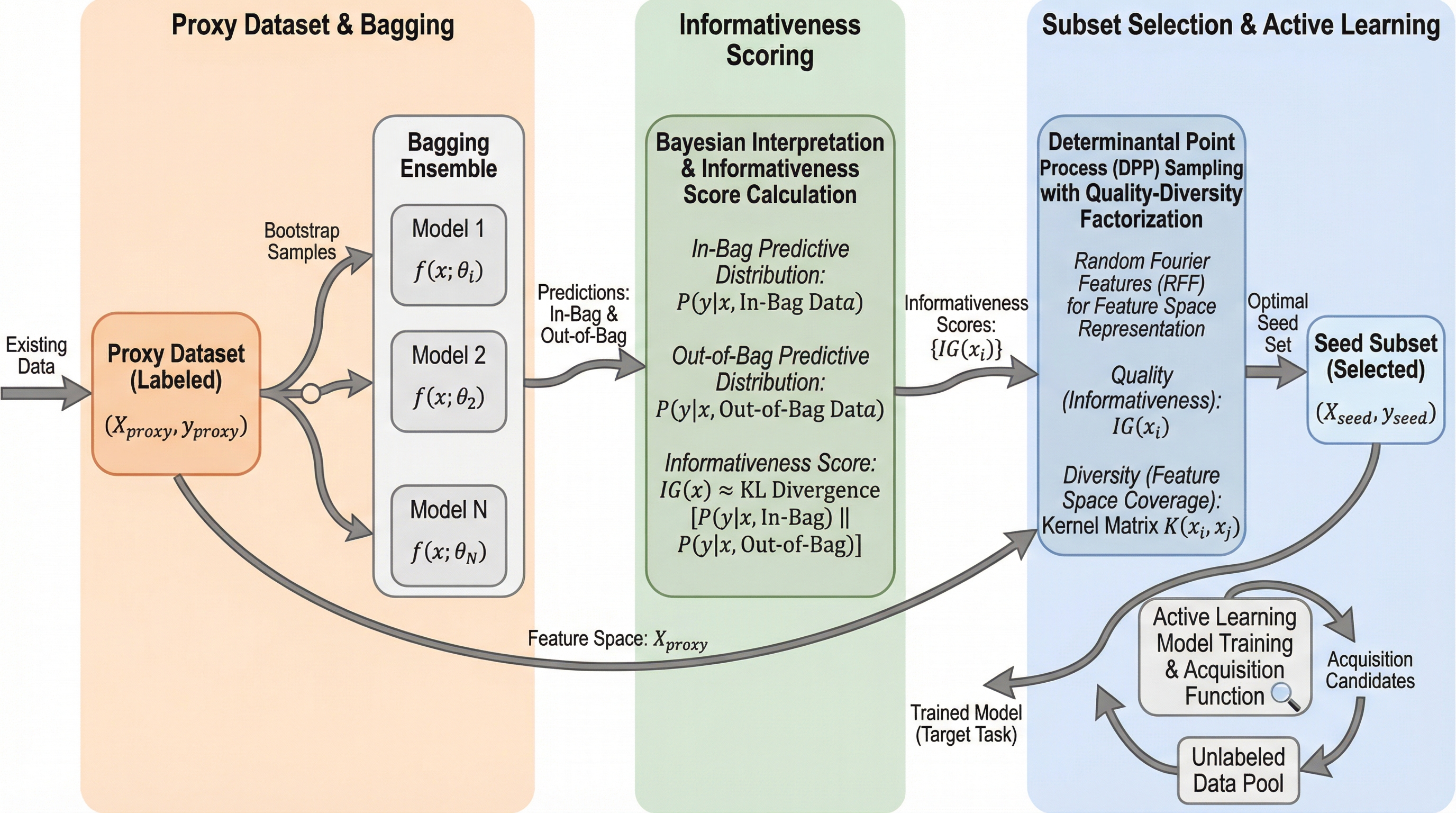
本研究は、能動学習の初期段階で重要となるシードデータの選択を最適化するため、既存の関連データセットから得られる知識を転移させる新手法「Active-Transfer Bagging(ATBagging)」を提案した。 この手法は、バギングアンサンブルモデルをベイズ的に解釈して各データの情報利得を推定する「情報量スコア」と、行列式点過程(DPP)を用いて特徴空間の多様性を確保する「不均一性」を数学的に統合し、重複が少なくかつモデルの学習に最も寄与するデータ群を抽出する。 4つの実世界データセットを用いた検証の結果、ATBaggingは従来のランダムサンプリングやコアセット手法と比較して、特にデータが極めて少ない初期段階において学習曲線の曲線下面積(AUC)を有意に向上させ、効率的なデータ収集の開始を可能にすることが確認された。
なぜこの問題か
現代の機械学習が直面している最大の障壁の一つは、高性能なモデルの構築に膨大なラベル付きデータを必要とする点にある。特に、医療画像の診断における専門医の判断や、複雑な物理現象のシミュレーション、あるいは高度な実験測定など、ラベルの付与自体に多大なコストや時間、専門知識が要求される分野では、データの収集がプロジェクト全体のボトルネックとなっている。能動学習はこの課題を解決するための有力な枠組みであり、モデルにとって最も価値のあるデータを選択的にラベル付けすることで、学習効率を最大化することを目指している。しかし、能動学習のプロセスにおいて、最初に選択される「シードデータ」の質が、その後の学習曲線の立ち上がりや最終的な精度を決定づける極めて重要な要因であることが知られている。 従来、このシードデータは一様ランダムサンプリングによって選ばれることが一般的であった。ランダムサンプリングは実装が容易で偏りがないように見えるが、実際にはモデルにとって情報量が少ないデータや、特徴空間内で重複したデータが選ばれるリスクを孕んでおり、初期段階の学習効率を著しく低下させる原因となっている。…
核心:何を提案したのか
本論文が提案する「Active-Transfer Bagging(ATBagging)」は、既存のラベル付きソースデータセットから、新しい学習タスクであるターゲットタスクのための最適なシードデータを抽出するための革新的な手法である。この手法の核心は、データの「情報量(Informativeness)」と「不均一性(Heterogeneity)」という、能動学習において相反しがちな2つの特性を高度に融合させた点にある。情報量とは、そのデータを学習に加えることでモデルの予測分布がどれだけ劇的に変化するか、すなわちモデルの知識をどれだけ更新できるかを示す指標である。一方で不均一性とは、選択されたデータが特徴空間全体をどれだけ広く、かつ重複なくカバーしているかを示す指標である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related