反蒸留フィンガープリンティング
大規模言語モデル(LLM)の出力を無断で学習して模倣する「モデル蒸留」を検知するため、生徒モデルの学習力学に適合した信号を埋め込む新手法「ADFP」が提案されました。 従来のウォーターマーク手法は生成品質を大幅に低下させる課題がありましたが、ADFPはプロキシモデルを用いて検知可能性を最大化するトークンを動的に選択することで、品質維持と強力な検知能力を両立します。 数学的推論(GSM8K)や対話タスク(OASST1)の検証において、生徒モデルの構造が未知であっても、従来手法を凌駕する精度で蒸留の有無を判定できることが実証されました。
TL;DR(結論)
大規模言語モデル(LLM)の出力を無断で学習して模倣する「モデル蒸留」を検知するため、生徒モデルの学習力学に適合した信号を埋め込む新手法「ADFP」が提案されました。 従来のウォーターマーク手法は生成品質を大幅に低下させる課題がありましたが、ADFPはプロキシモデルを用いて検知可能性を最大化するトークンを動的に選択することで、品質維持と強力な検知能力を両立します。 数学的推論(GSM8K)や対話タスク(OASST1)の検証において、生徒モデルの構造が未知であっても、従来手法を凌駕する精度で蒸留の有無を判定できることが実証されました。
なぜこの問題か
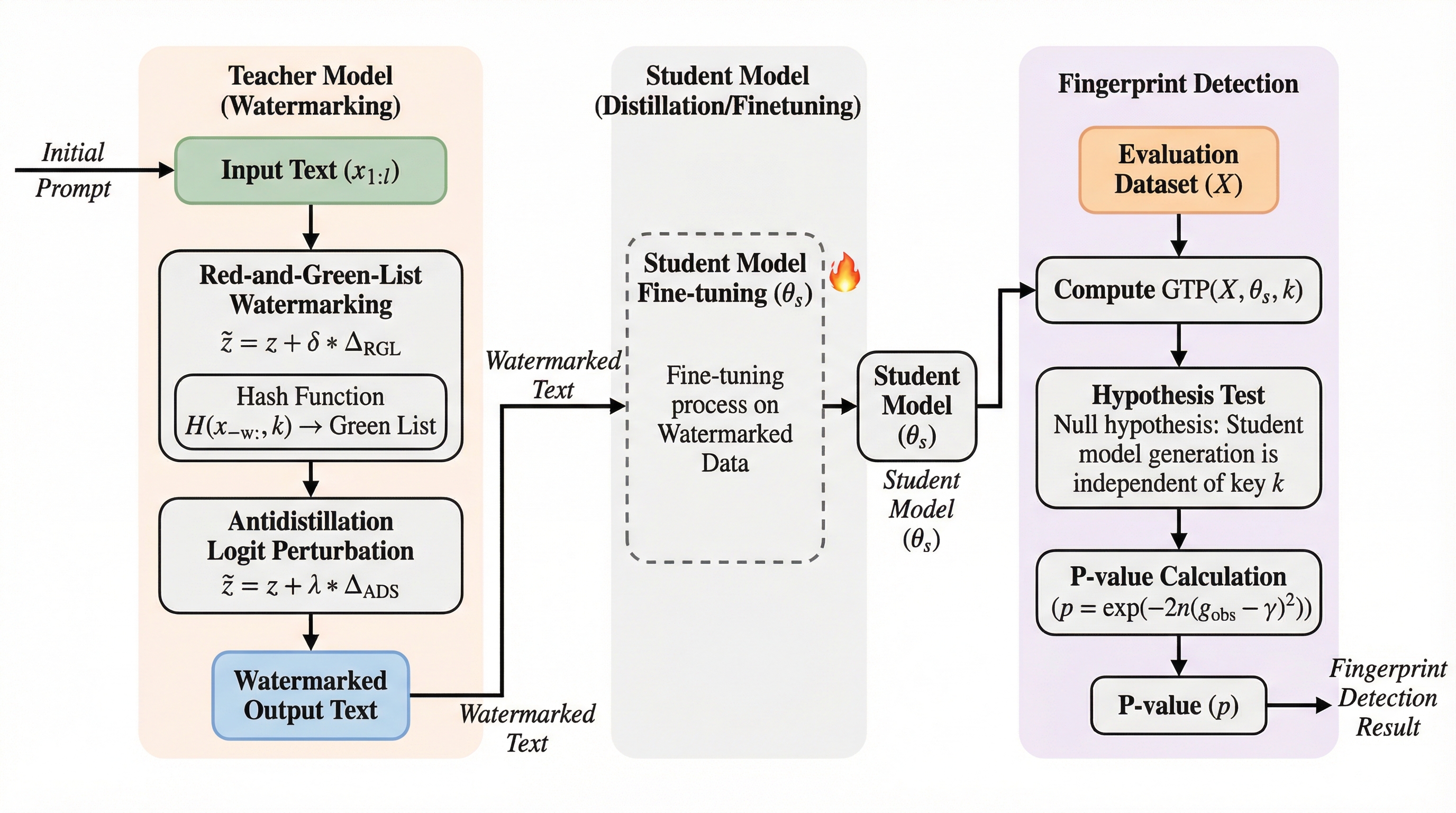
最先端の大規模言語モデル(LLM)の開発には、膨大な計算資源と莫大な投資が必要であり、これを利用できる機関は極めて限られています。その一方で、公開された高性能なモデルの出力を学習データとして利用し、低コストでその能力を模倣する「モデル蒸留」が大きな課題となっています。モデルの所有者は、自社の知的財産を守るために、第三者の生徒モデルが自社モデルの出力を微調整に使用したかどうかを確実に判断できる技術を必要としています。既存のフィンガープリンティング技術やウォーターマーク手法は、特定のトークン群(グリーンリスト)を選択する確率を静的に高めるヒューリスティックな摂動に依存してきました。しかし、これらの単純な手法は、生成されるテキストの品質と検知能力の間に厳しいトレードオフを生じさせます。検知感度を高めようとすると、モデル本来の性能や出力の自然さが著しく損なわれるという問題がありました。 また、従来のウォーターマークは、生徒モデルが学習プロセスを通じてどのように信号を内部パラメータに取り込むかという動的な側面を考慮していませんでした。…
核心:何を提案したのか
本研究では、生徒モデルの学習力学にフィンガープリンティングの目的を適合させる、原理に基づいたアプローチである「反蒸留フィンガープリンティング(ADFP)」を提案しました。この手法は、従来の静的なウォーターマークとは異なり、生徒モデルが教師モデルの出力を学習する際の最適化プロセスを直接的に考慮に入れています。具体的には、プロキシ(代理)モデルを活用して、微調整後の生徒モデルにおいてフィンガープリントの検知可能性を最大化するようなトークンを特定し、サンプリングを行う手法です。ADFPは、単に特定のトークンをランダムに強調するのではなく、生徒モデルがその信号を効率的に内部化できるような「学習しやすい」信号を選択的に埋め込みます。これにより、教師モデルの出力品質への影響を最小限に抑えながら、生徒モデルがその出力を学習した際に強力な識別信号が残るように設計されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related