事前学習モデルの“余り”を使って忘却を抑える――データなし継続学習アダプタPLATE
継続学習で「昔のタスクのデータなし」に、どうやって忘却を防ぐのでしょうか。 鍵は追加データでも特別な記憶でもなく、事前学習済みネットワークに潜む“幾何学的な余り”でした。 この記事では、PLATEがどんな発想で更新を制御し、可塑性と保持のトレードオフを扱おうとしているのかを追います。
論文図解
TL;DR(結論)
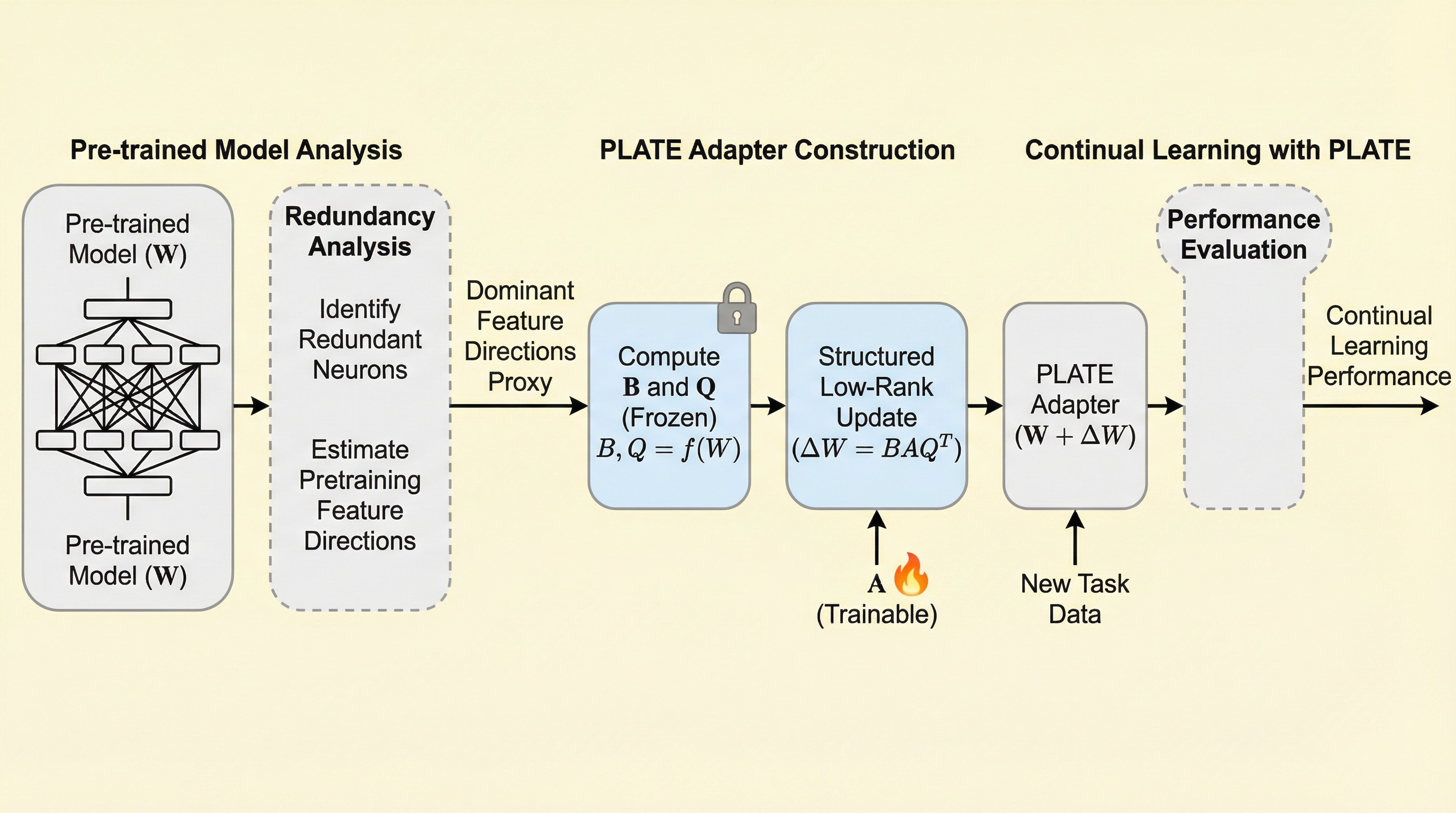
- 提案の中心は PLATE(Plasticity-Tunable Efficient Adapters for Geometry-Aware Continual Learning)です。
- 名前が示す通り、焦点は「可塑性(plasticity)」を調整可能にしつつ、「効率的なアダプタ(efficient adapters)」として実装し、さらに「幾何(geometry)」に基づいて継続学習を扱うところにあります。
- 鍵は追加データでも特別な記憶でもなく、事前学習済みネットワークに潜む“幾何学的な余り”でした。
なぜこの問題か
大きなバックボーンを巨大で不透明な分布で事前学習し、その後に instruction tuning・domain adaptation・reinforcement learning などで下流適応します。現代の現場では、これが自然な流れになっていると論文は述べ、その状況認識から書き起こしています。しかもこの「不透明さ」は、単にデータ量が大きいという話にとどまらず、分布そのものが手元にない/再現できないという形で、後段の適応や評価に影を落とします。
核心:何を提案したのか
提案の中心は PLATE(Plasticity-Tunable Efficient Adapters for Geometry-Aware Continual Learning)です。名前が示す通り、焦点は「可塑性(plasticity)」を調整可能にしつつ、「効率的なアダプタ(efficient adapters)」として実装し、さらに「幾何(geometry)」に基づいて継続学習を扱うところにあります。ここで“幾何”という言葉が前に出ているのは、保持や忘却を、データ上の損失だけでなく、重み空間の構造として捉え直したい、という姿勢の表れとして読めます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related