緊急停止だけで賢くする:不完全な介入信号から学ぶ「残差」微調整
「危ない!」という緊急停止(e-stop)しか手がかりがないとき、ロボットは本当に上達できる? しかも現場で起きるのは、丁寧な指示や正解例ではなく、とっさの停止や介入であることが多いはずです。 実は、“止められないようにする”だけでは、うまくいくとは限りません。
論文図解
TL;DR(結論)
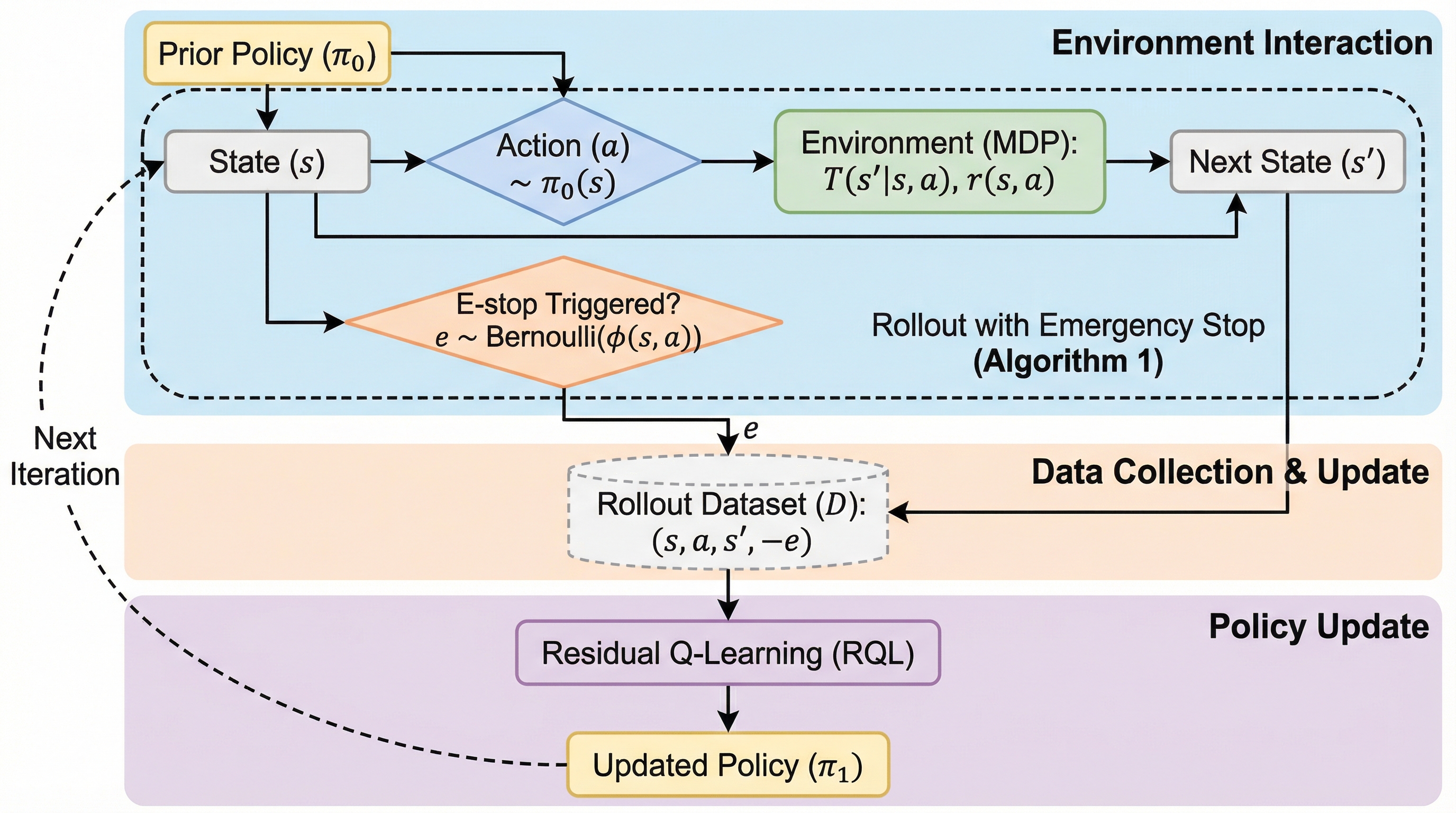
- 論文が提示する中心の提案は、介入学習を「方策の置き換え」ではなく 微調整(fine-tuning) として捉え直すことです。
- 介入フィードバックは、方策を丸ごと作り直すための完全な教師ではない。
- 論文は問題設定として、Markov decision process(MDP)を置きます。
なぜこの問題か
自律システムのテスト中、人が介入するデータはよく集まります。危険を感じたら止める、あるいは制御を奪う。実験室の外に出るほど、こうした「人が安全側に倒す瞬間」は自然に発生しやすく、データとしても現実的に手に入りやすい部類です。だからこそ、介入を学習に使いたいという発想はとても素直に見えます。
核心:何を提案したのか
論文が提示する中心の提案は、介入学習を「方策の置き換え」ではなく 微調整(fine-tuning) として捉え直すことです。介入フィードバックは、方策を丸ごと作り直すための完全な教師ではない。ここを認めると、学習の設計は自然に変わります。「介入が教えていない部分」を無理に埋めようとして暴走するより、すでに持っている知識を活かして、必要なところだけを直すほうが筋が通るからです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related