計算予算の中で「推論の誤り率」を握る——Conformal Thinkingという発想
推論LLMは、どこまで考えさせれば“十分”なのでしょうか? 実は「トークン数を決める問題」は、しきい値を決める問題に姿を変えるだけで、悩みは残ります。 この記事では、計算予算の設定を“リスク(誤り率)制御”に言い換える論文の狙いと仕組みを追います。
論文図解
TL;DR(結論)
- 論文の中心メッセージは、こう言い換えられます。
- 「トークン予算をいくつにするか」を直接決めるのではなく、許容するリスク(誤り率)ϵをユーザーが指定し、そのϵを満たしつつ計算を最小化する停止ルールを、検証用データから選ぶ。
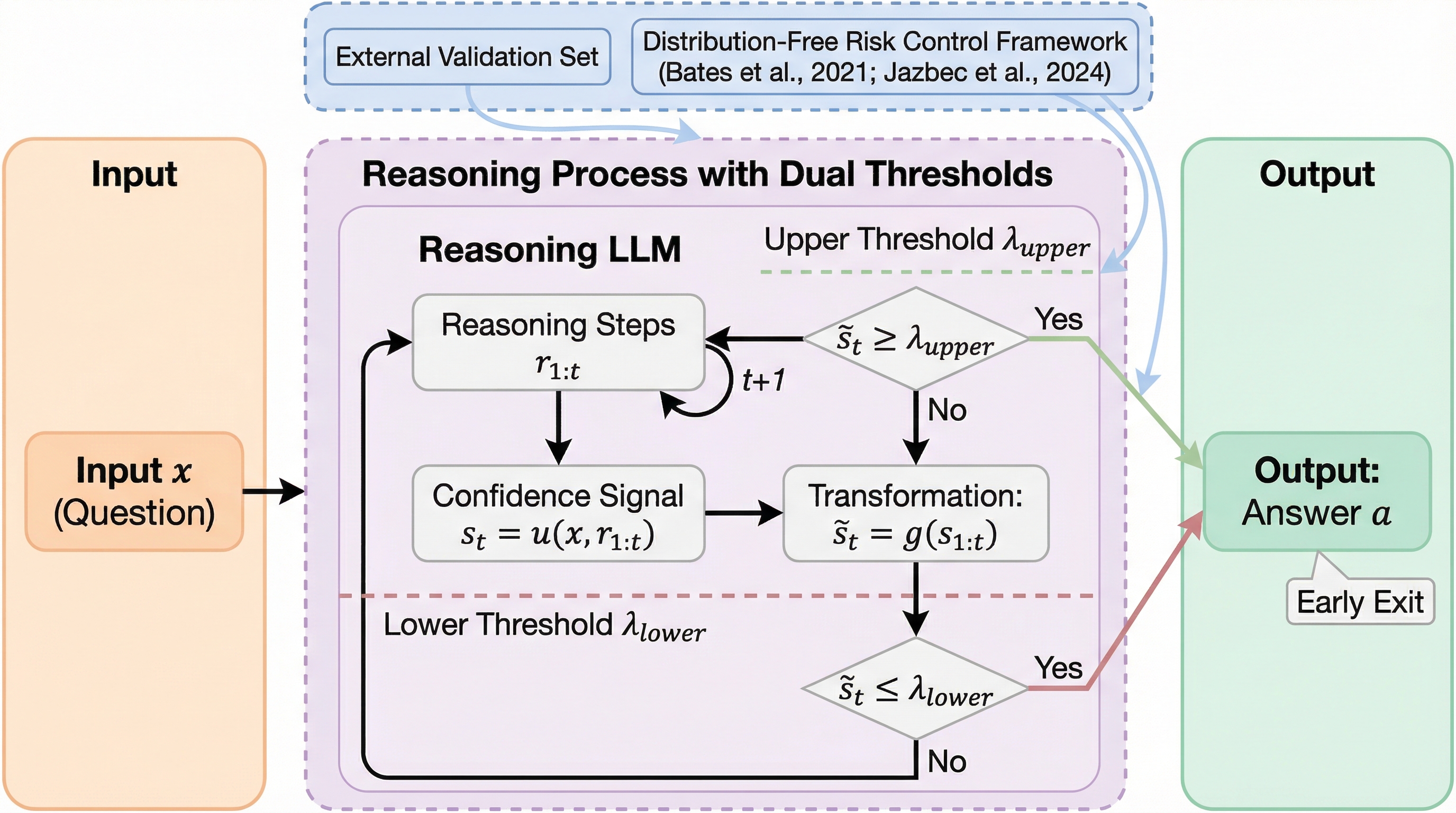
- まず前提として、推論はステップ(あるいは“thought chunk”)を積み上げて進みます。
なぜこの問題か
推論に強いLLMは、テスト時に“考える量”を増やすほど、データセット全体の正解率が上がりやすい。つまり、トークン予算を積めば性能が伸びる局面があり、これがいわゆるテスト時スケーリングの魅力になっています。 一方で、その伸びがいつまでも続くわけではなく、「追加の計算がもう効かない」領域に入ってもトークンを支払い続けてしまう、という実務的な痛点が残ります。
核心:何を提案したのか
論文の中心メッセージは、こう言い換えられます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related