オンラインとオフラインの“いいとこ取り”:マルチターンコード生成をコンテキスト付きバンディットで学習する
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。
論文図解
TL;DR(結論)
- 論文が提案するのは COBALT(contextual bandit learning with offline trajectories) です。
- 狙いは明快で、オンラインとオフラインのRLの「良いところ」を同時に引き出す、とされています。
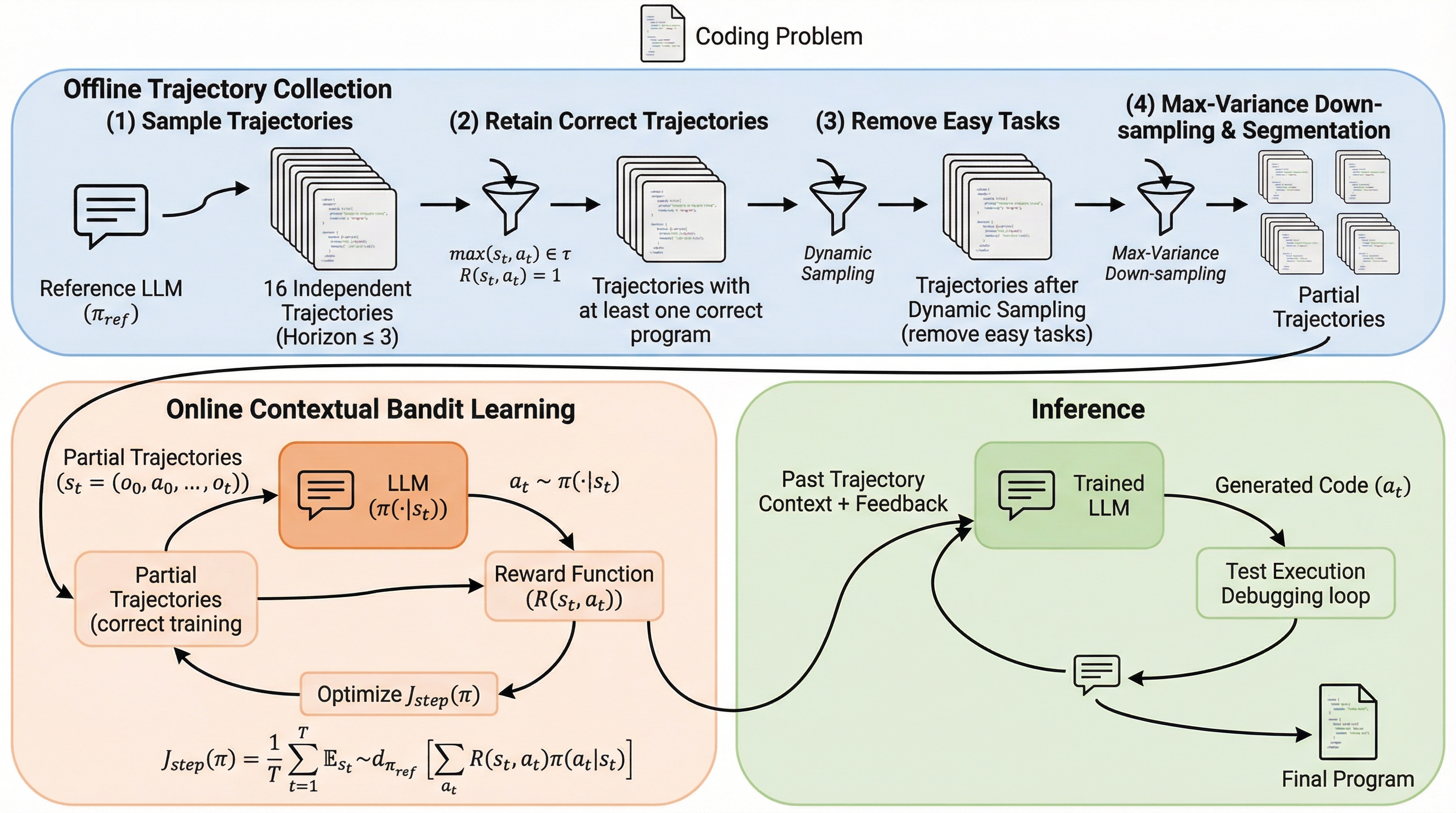
- COBALTの流れは大きく二段です。
なぜこの問題か
LLMに「コードを書いて、テストで直して、また直して……」をやらせる。いわゆるマルチターンのコード生成は、現実の開発に近いぶん、学習も評価も難しくなります。 一回で正解を出すより、“途中で外しても戻れる”ことや、“フィードバックをどう解釈して次の一手を選ぶか”が前面に出てくるため、単純な生成能力だけでは語りにくい領域になります。
核心:何を提案したのか
論文が提案するのは COBALT(contextual bandit learning with offline trajectories) です。狙いは明快で、オンラインとオフラインのRLの「良いところ」を同時に引き出す、とされています。 ここでの肝は、オンラインとオフラインを“混ぜる”というより、両者の境界にあったボトルネック(高コスト・不安定、分布ずれ・探索不足)を、別の切り方で迂回する点にあります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related