視覚トークンを“間引いても崩れない”——マルチモーダルLLM学習を速くするDualSpeed
マルチモーダルLLMは、なぜ「学習」だけがこんなに重くなりがちなのでしょうか? 鍵はモデルの巨大さだけでなく、画像が生む“視覚トークンの多さ”にあります。 とはいえ、ただ削れば速くなる一方で、推論の場面で別の問題が噴き出す——そこが話を難しくします。
論文図解
TL;DR(結論)
- 論文が提案するのは、DualSpeedという「fast-slow」フレームワークです。
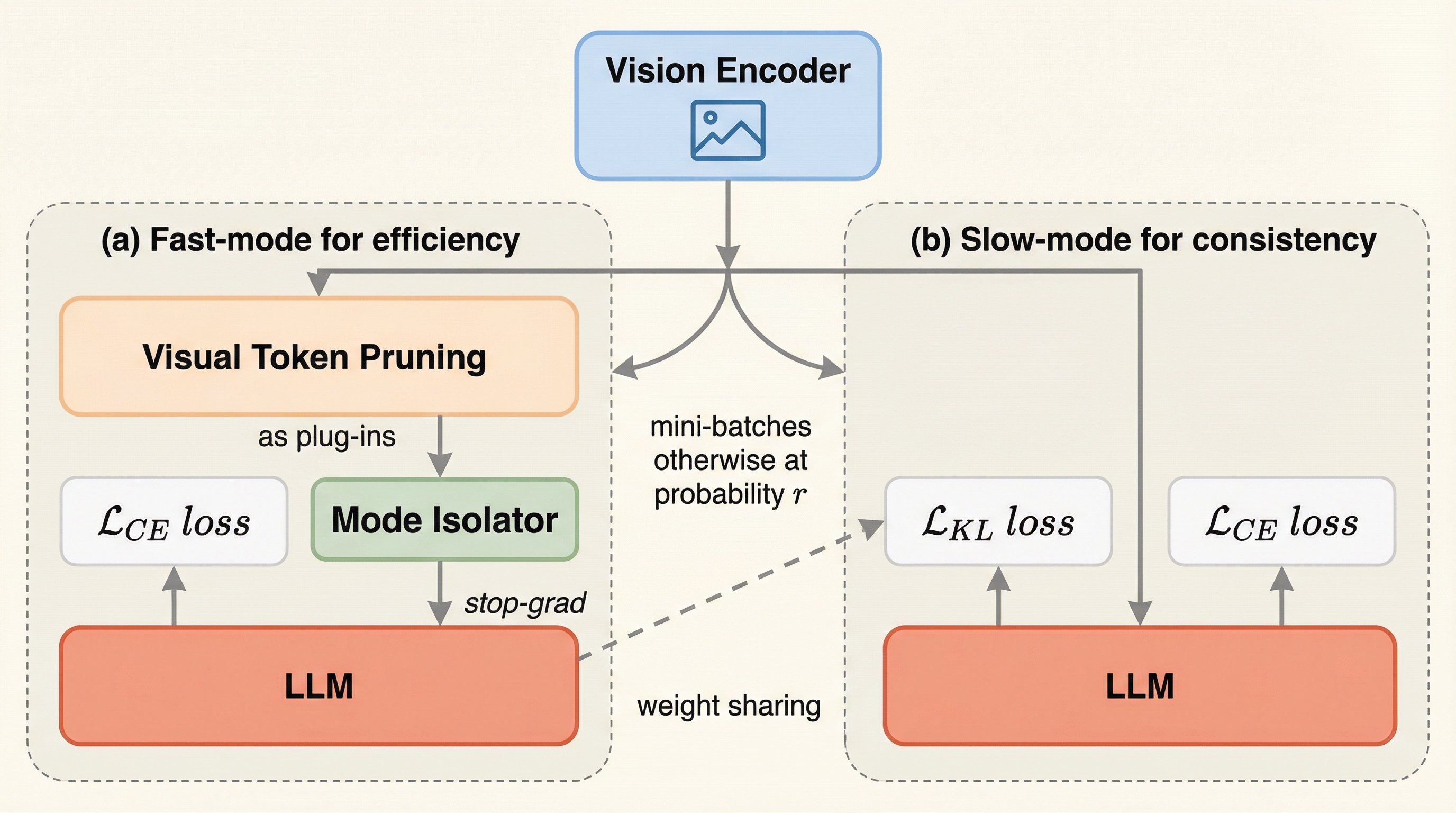
- 視覚トークンを削るVisual Token Pruning(VTP)を、推論だけでなく学習にも持ち込み、学習を速くすることが狙いです。
- DualSpeedの読みどころは、「二つのモードをただ並べる」だけで終わっていない点です。
なぜこの問題か
マルチモーダルLLM(MLLMs)の訓練が重い理由は、モデルサイズだけではありません。論文は、視覚側が生む「視覚トークン数」そのものが、学習効率を深刻に悪化させると指摘します。とりわけ、モデルのサイズや入力解像度が伸びるほど、この部分がボトルネックとして前面に出てくる、という問題意識です。
核心:何を提案したのか
論文が提案するのは、DualSpeedという「fast-slow」フレームワークです。視覚トークンを削るVisual Token Pruning(VTP)を、推論だけでなく学習にも持ち込み、学習を速くすることが狙いです。既存の効率化が「サイズ」や「学習パラメータ」に寄る中で、DualSpeedは「視覚トークン数を減らす」方向に舵を切っています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related