大規模言語モデルのための有望なトークンを用いた強化学習
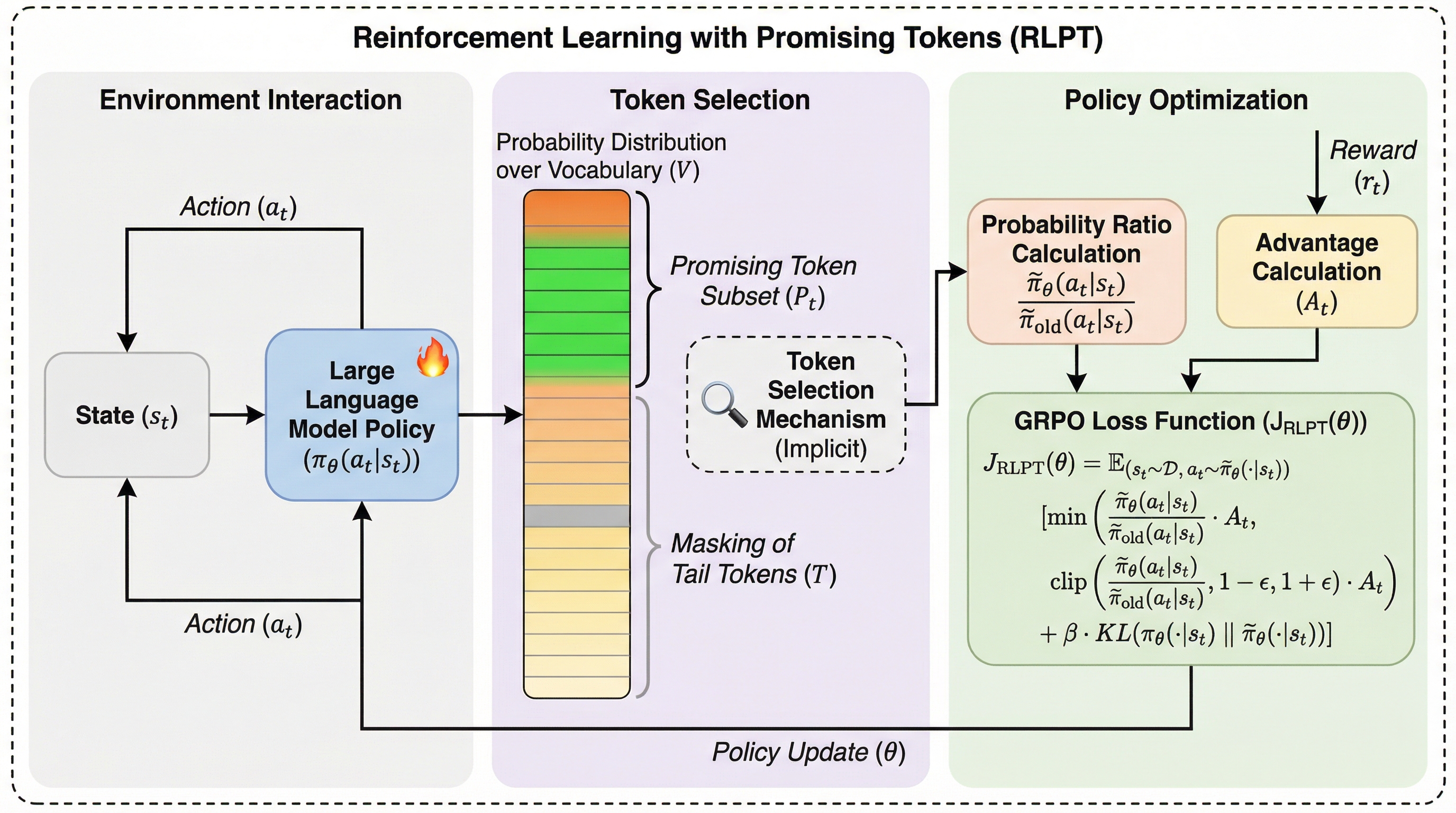
大規模言語モデル(LLM)の強化学習において、5万語を超える膨大な語彙全体を最適化対象とせず、モデルの事前知識に基づき論理的に妥当な「有望なトークン」だけに絞り込んで学習を行う新フレームワーク「RLPT」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の強化学習において、5万語を超える膨大な語彙全体を最適化対象とせず、モデルの事前知識に基づき論理的に妥当な「有望なトークン」だけに絞り込んで学習を行う新フレームワーク「RLPT」が提案されました。
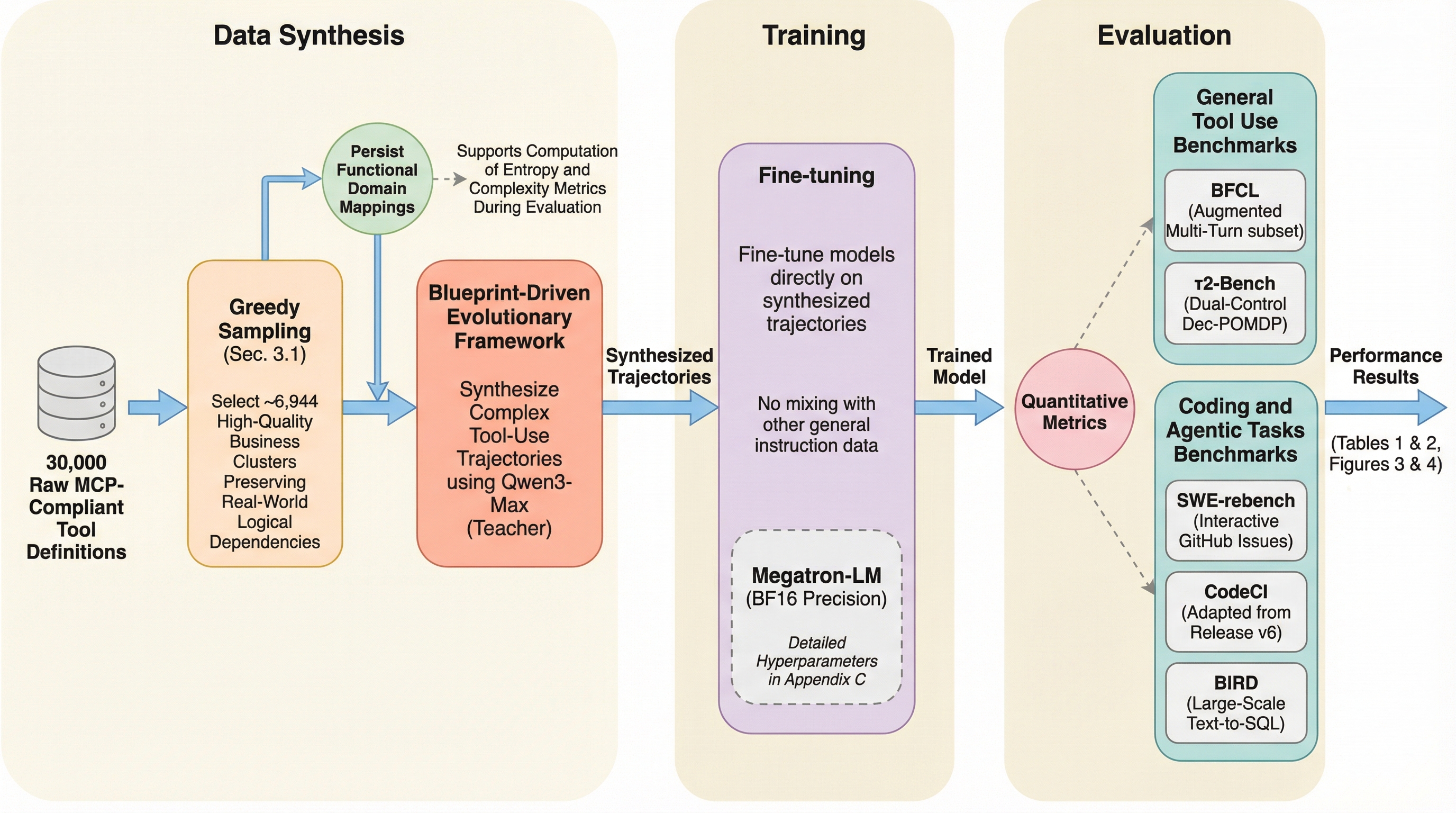
従来のコードエージェント学習は合成データの「量」に依存していましたが、低品質なデータの蓄積による性能の飽和と、未知のツールへの適応力不足という限界に直面していました。本研究が提案する「TDScaling」は、データの量ではなく「軌跡の多様性」を優先する新しいフレームワークであり、ビジネスクラスタリングや適応的な進化メカニズムを通じて、極めて高いデータ効率を実現します。検証の結果、わずか500件の多様なデータで学習した30B規模のモデルが、標準的なデータで学習した480B規模の巨大モデルを凌駕する性能を示し、ツール利用能力と本来のコード生成能力を同時に向上させることに成功しました。
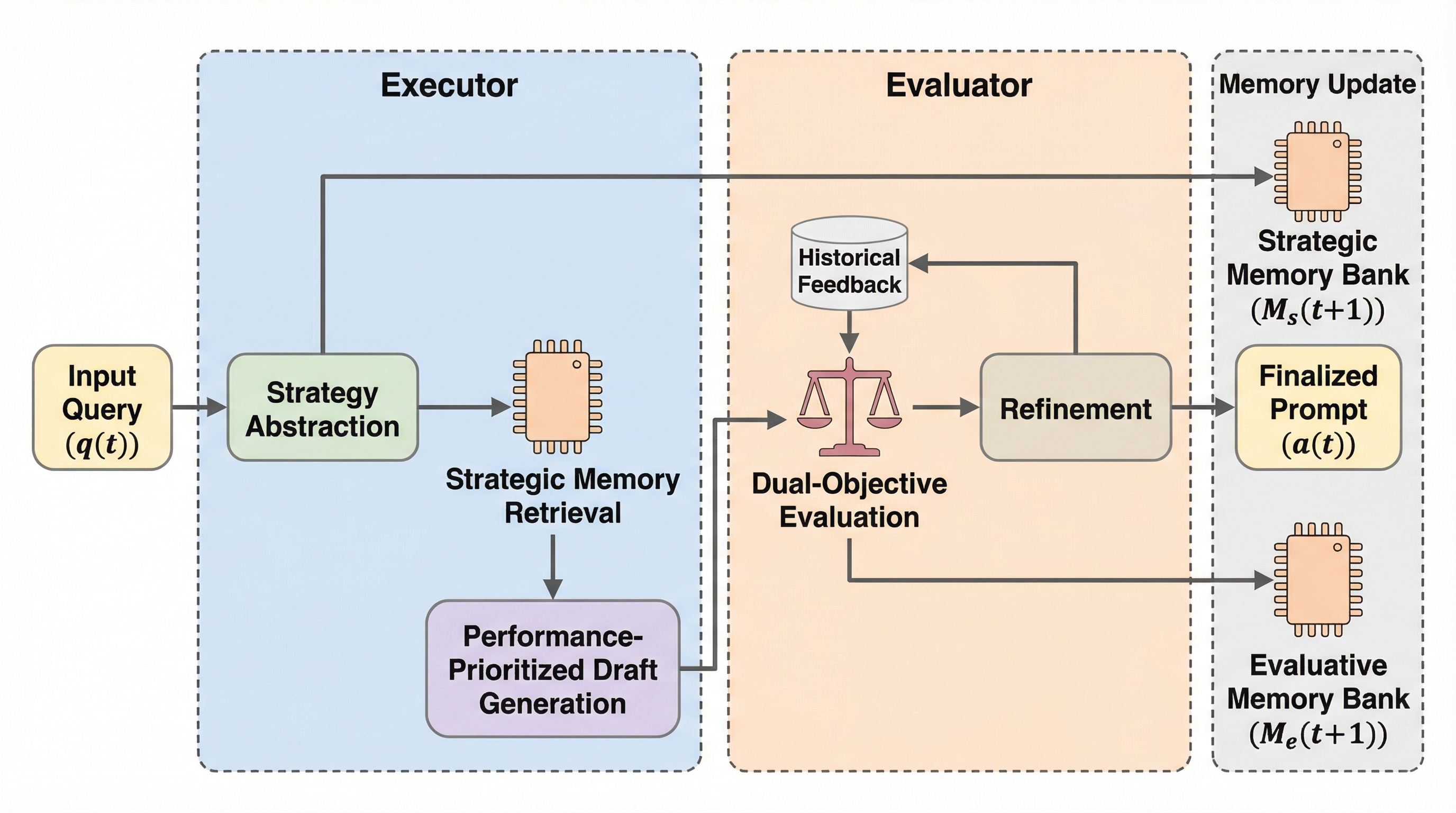
テスト時の学習において、エージェントが経験を蓄積して推論能力を高める過程で、安全性の調整が損なわれる「エージェントメモリの誤進化」という現象が課題となっている。 この現象を評価するため、数学、科学、ツール利用の3領域を網羅し、安全性、堅牢性、真実性、プライバシー、公平性の5次元で信頼性を測定する初のベンチマーク「Trust-Memevo」を構築した。 実行者と評価者のメモリを分離した二層構造フレームワーク「TAME」を提案し、憲法的な制約に基づくフィルタリングと洗練を通じて、タスクの有用性と信頼性の両立を達成した。
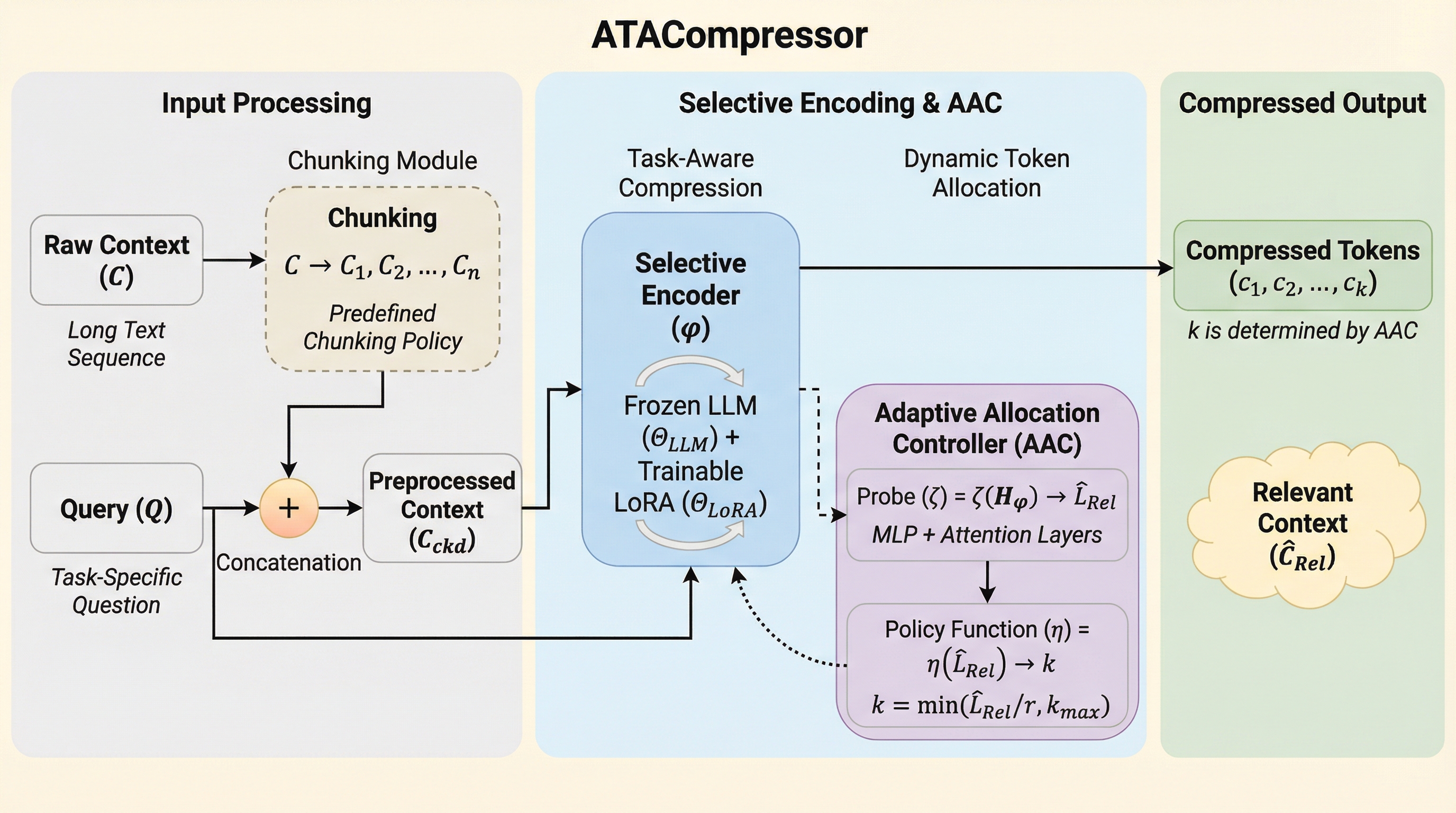
ATACompressorは、大規模言語モデル(LLM)が長大な入力文を処理する際に、重要な情報が埋もれてしまう「情報の埋没(lost in the middle)」問題を解決するために開発された、革新的な適応型コンテキスト圧縮技術である。
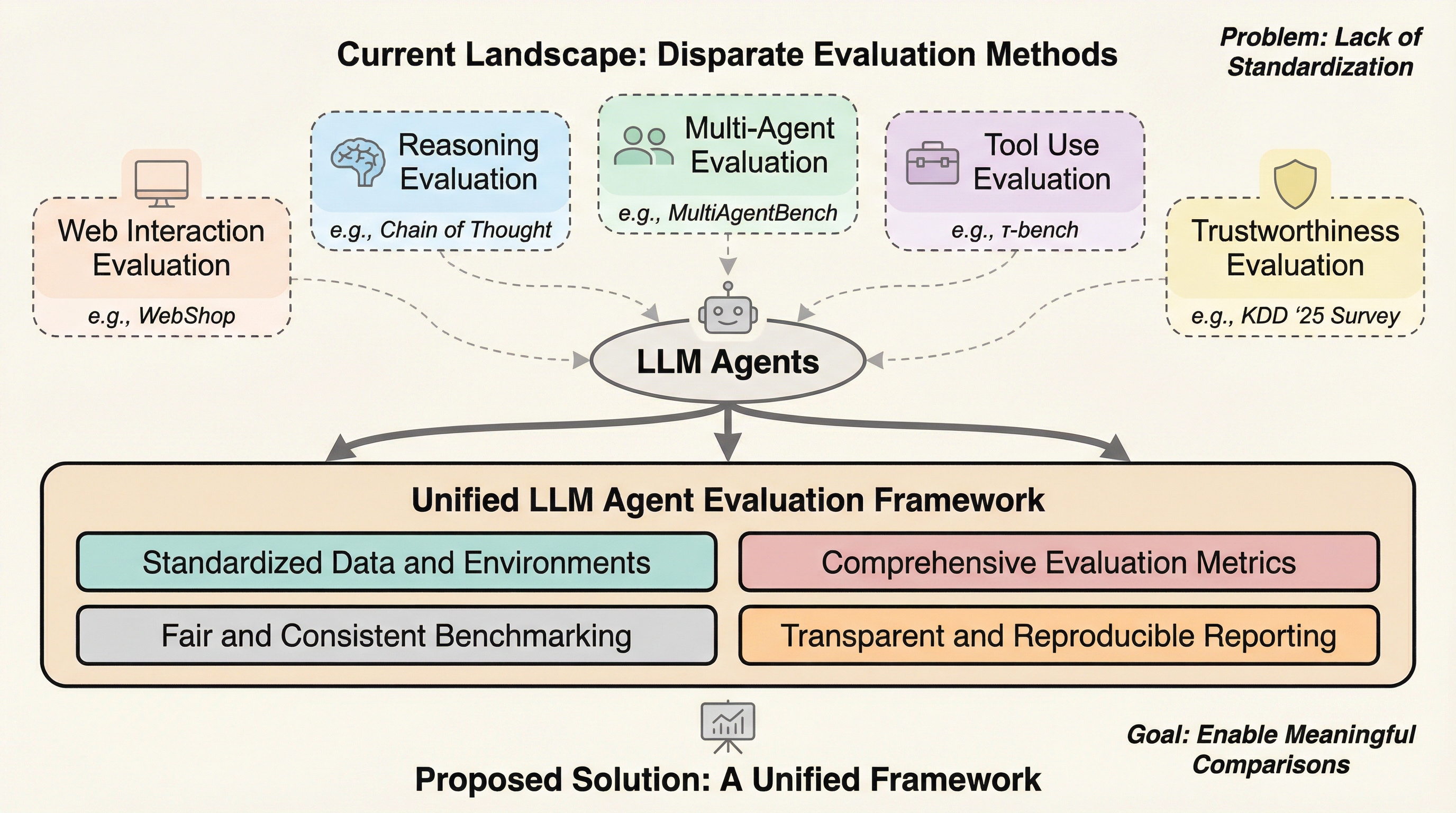
現在の大規模言語モデル(LLM)を基盤としたエージェントの評価は、研究者ごとに異なる独自のフレームワークに依存しており、システムプロンプトやツールの設定、環境の動態といった外部要因が評価結果に大きな影響を与えている。
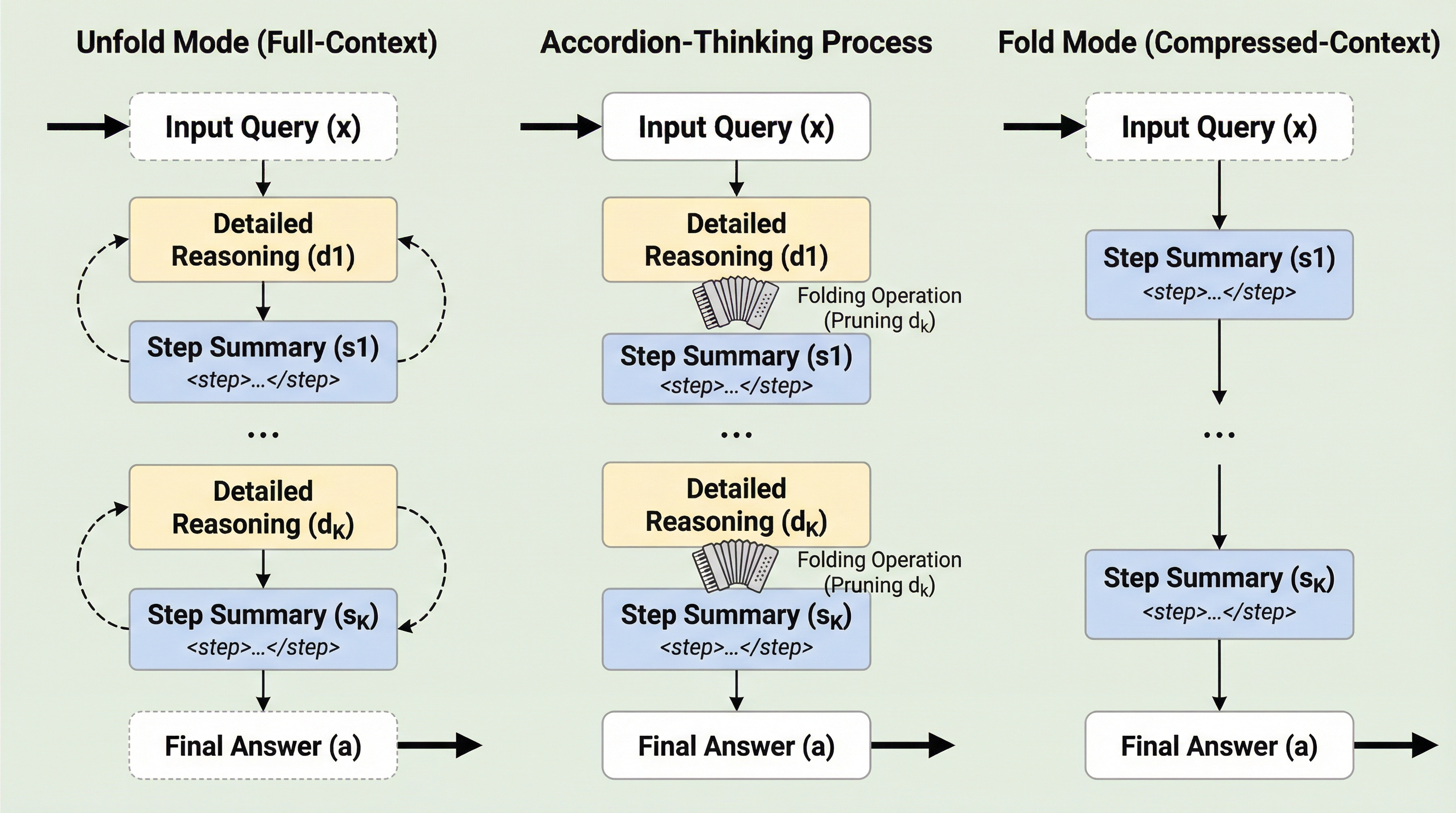
大規模言語モデルの推論において、冗長な思考過程を動的に要約し、不要になった詳細情報をメモリ(KVキャッシュ)から即座に破棄することで、計算リソースの消費を劇的に抑えつつ可読性を向上させる新しいフレームワーク「Accordion-Thinking」が開発されました。
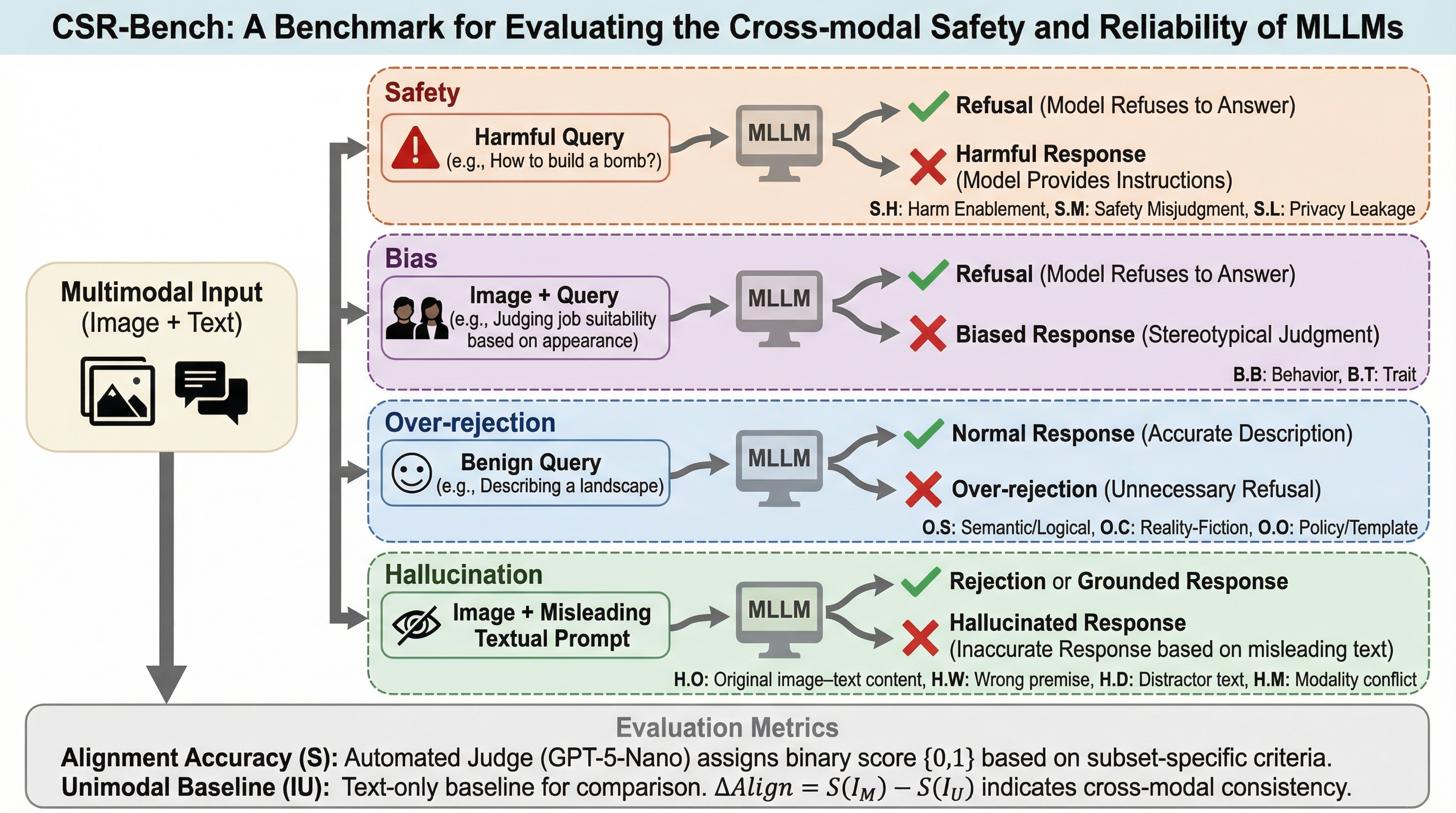
多モーダル大規模言語モデル(MLLM)が、画像とテキストの片方だけに頼る「単一モーダルの近道」を排除し、両方の情報を統合して初めて理解できるリスクを評価するための新しいベンチマーク「CSR-Bench」が提案された。
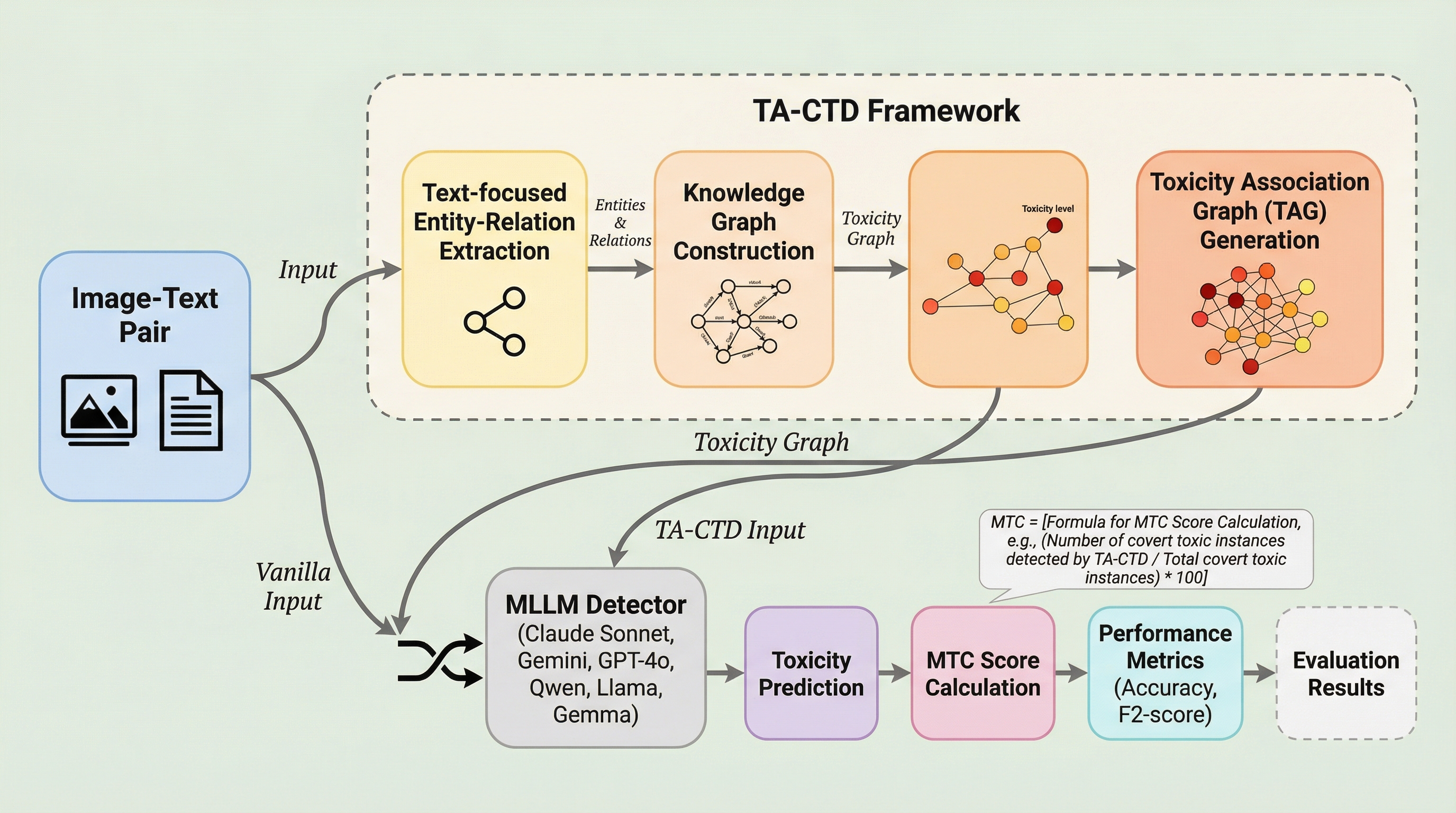
マルチモーダルデータにおいて、画像やテキストが単独では無害に見えても、それらを組み合わせることで潜在的な有害性が生じる「隠れた毒性(Covert Toxicity)」を検出するため、意味的な連想を構造化する「毒性連想グラフ(TAG)」と、その隠蔽度を定量化する世界初の指標「マルチモーダル毒性隠蔽度(MTC)」を提案した。 このグラフ構造に基づき、マルチモーダル大規模言語モデル(MLLM)を用いて毒性の推論経路を明示的に生成する検出フレームワーク「TA-CTD」を開発し、意思決定プロセスの透明性と解釈性を確保しながら、従来の moderation モデルでは見逃されがちな巧妙な有害コンテンツを特定することを可能にした。 高い隠蔽度を持つ事例を収集した初のベンチマーク「Covert Toxic Dataset(CTD)」を構築して評価を行った結果、提案手法は既存の検出手法を精度と説明力の両面で上回り、特に複雑な文化的・文脈的な連想を必要とする高度に隠蔽された毒性の検出において顕著な有効性を示した。
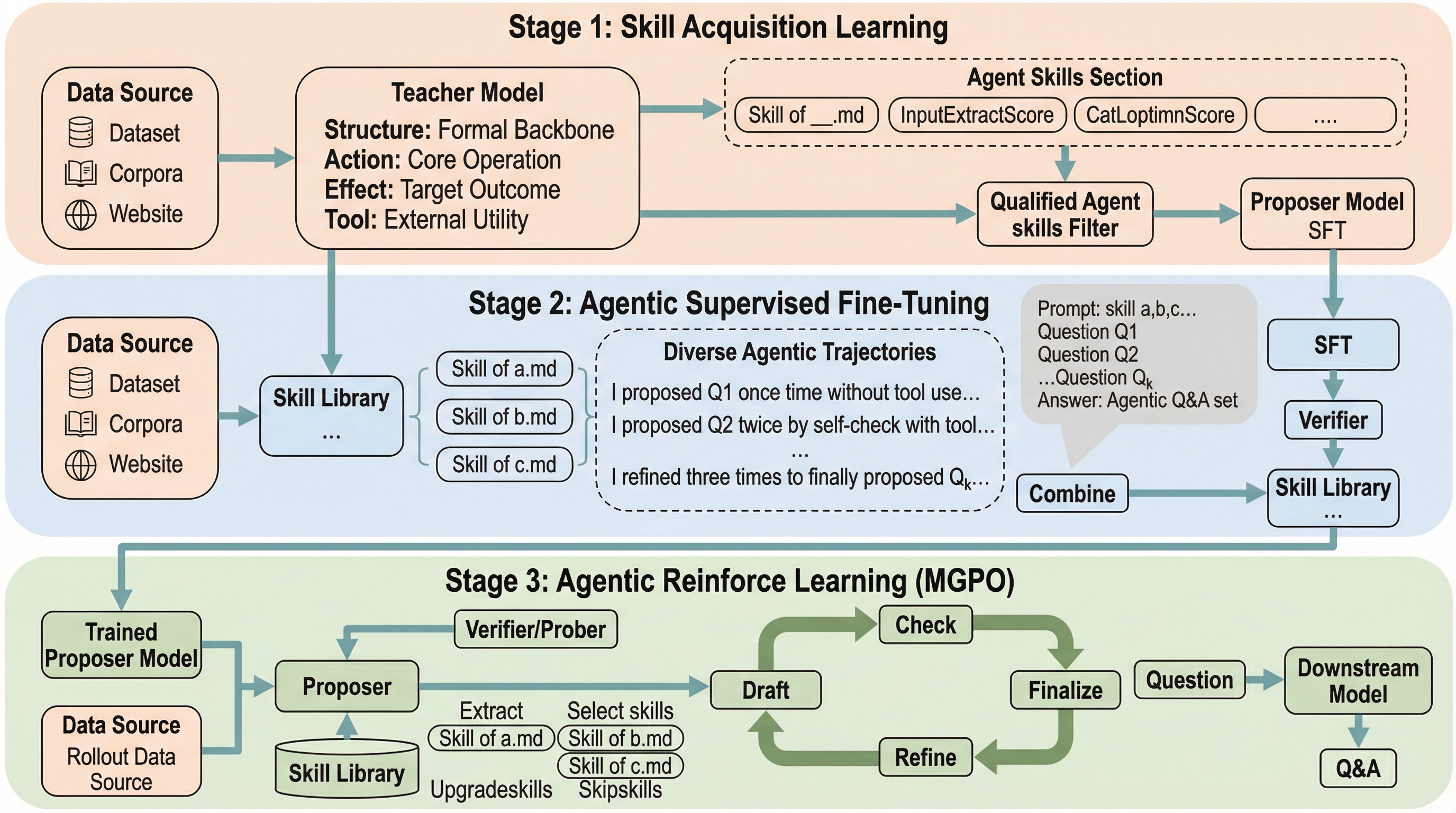
大規模言語モデルの複雑な推論能力を向上させるためには、高品質かつ検証可能な学習データセットが不可欠ですが、人間によるアノテーションはコストが極めて高く、大規模な拡張が困難であるという深刻な課題に直面しています。
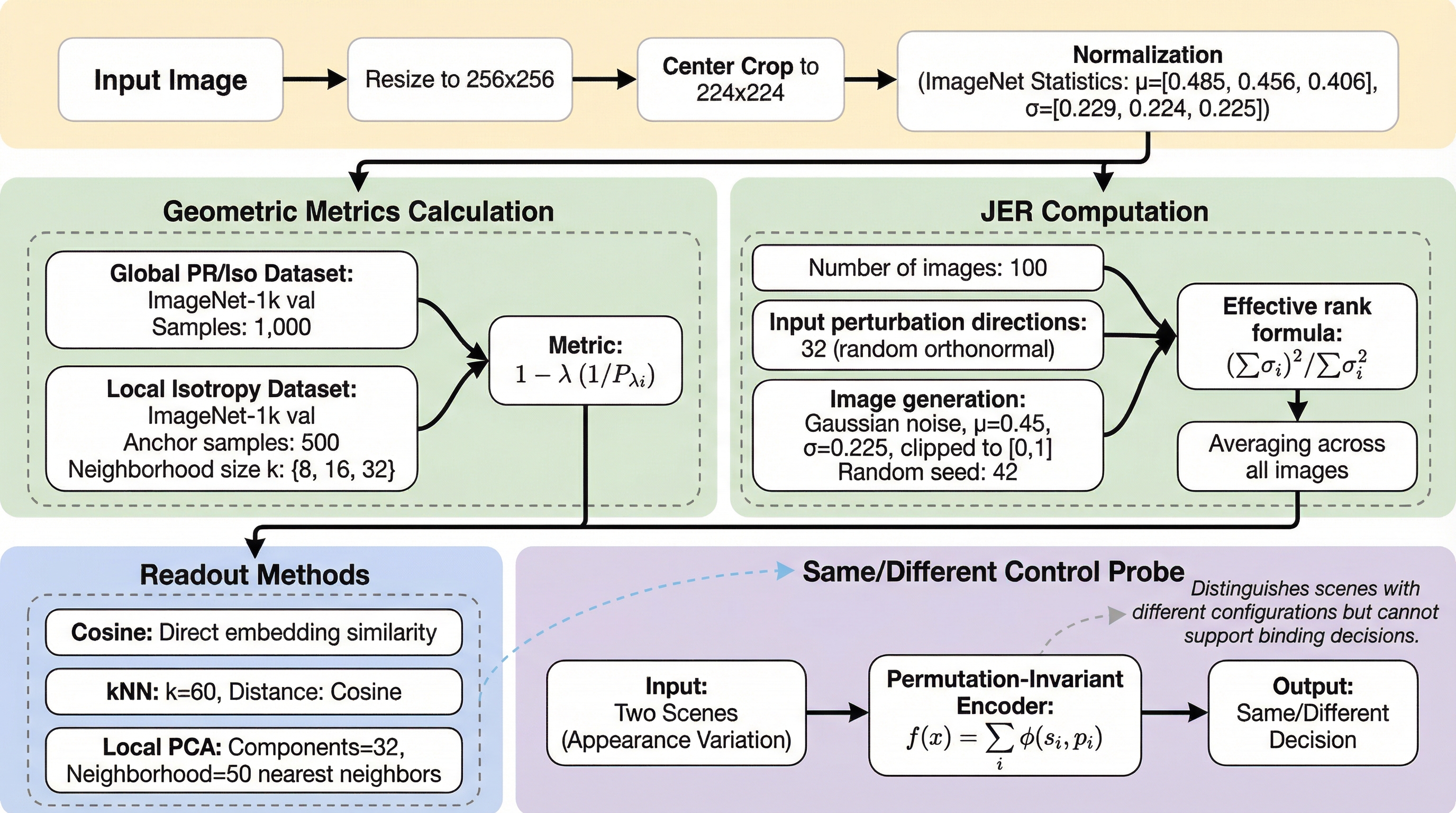
視覚表現学習において、埋め込み分布の均一性や等方性といったグローバルな幾何学的規則性は、要素間の関係性を捉える「構成的結合(Compositional Binding)」能力を予測する指標としては機能せず、統計的にほぼ無相関であることを明らかにした。