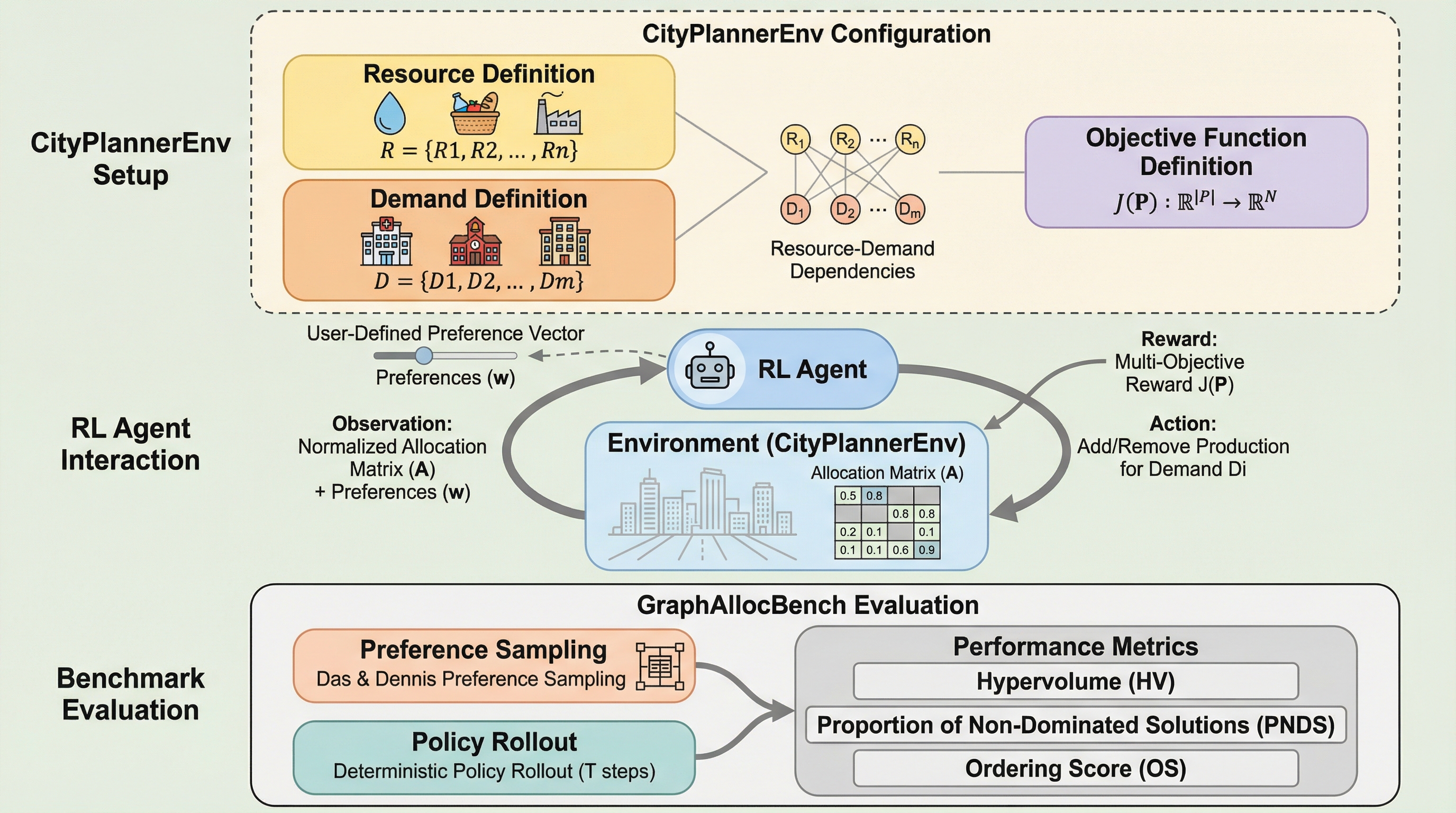
GraphAllocBench: 選好条件付き多目的強化学習のための柔軟なベンチマーク
多目的強化学習における選好条件付き方策学習(PCPL)は、ユーザーが指定した目的間の選好(重み)に基づいて、単一のモデルで多様なパレート最適解を近似することを目指す手法であり、実行時に任意のトレードオフへ柔軟に適応できる利点を持つ。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
多目的強化学習における選好条件付き方策学習(PCPL)は、ユーザーが指定した目的間の選好(重み)に基づいて、単一のモデルで多様なパレート最適解を近似することを目指す手法であり、実行時に任意のトレードオフへ柔軟に適応できる利点を持つ。
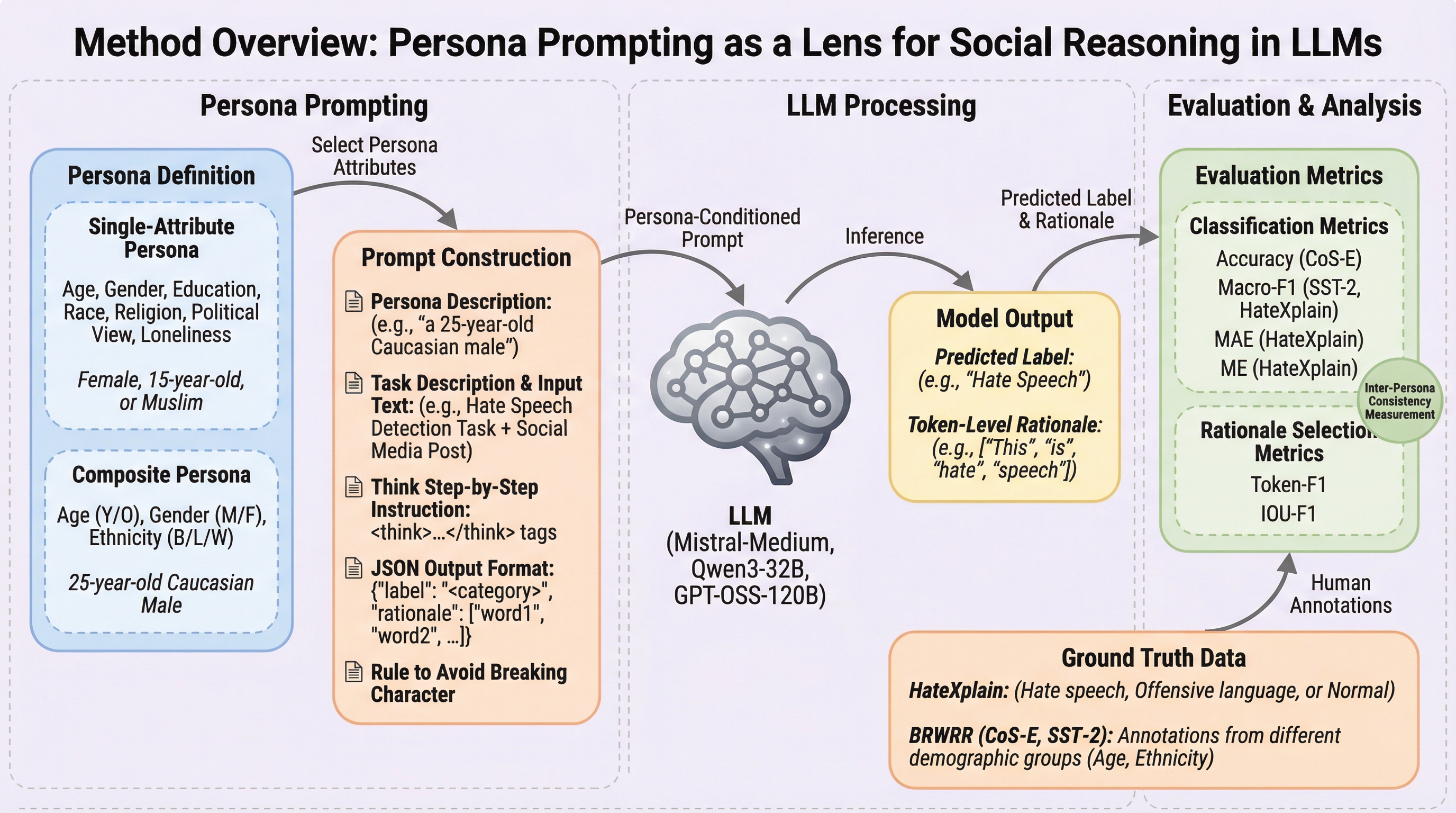
大規模言語モデル(LLM)に対して特定の属性を与える「ペルソナプロンプティング」は、ヘイトスピーチ検出のような主観的なタスクにおいて分類精度を向上させる場合がある一方で、判断の根拠となる単語選択の質(根拠の正確性)を低下させるという重大なトレードオフが存在することが明らかになった。
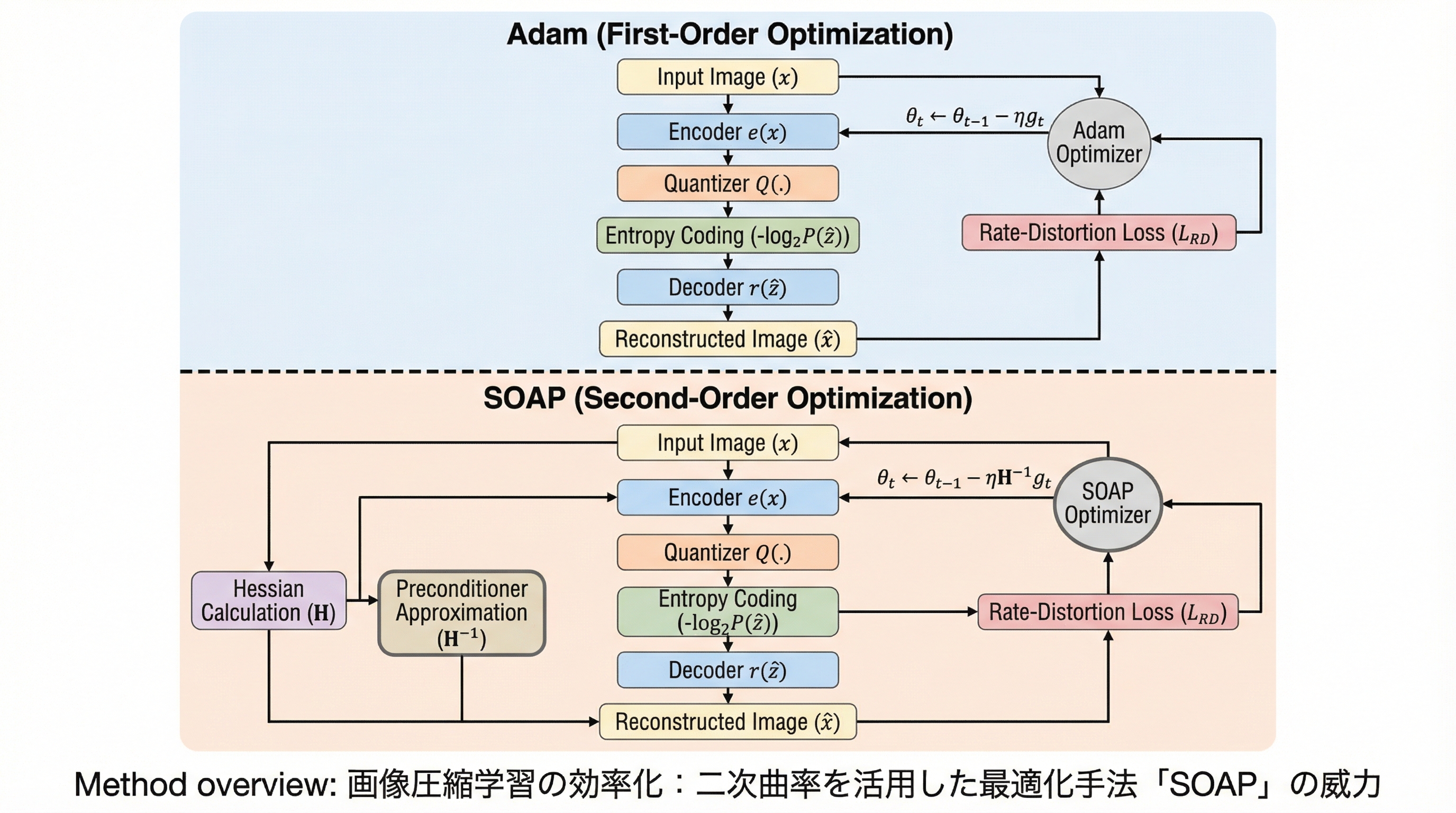
学習ベースの画像圧縮(LIC)モデルの訓練において、ビットレート削減と歪み最小化という相反する目的が引き起こす「勾配の衝突」を解決するため、二次曲率情報を活用する準ニュートン最適化手法「SOAP」を導入した。
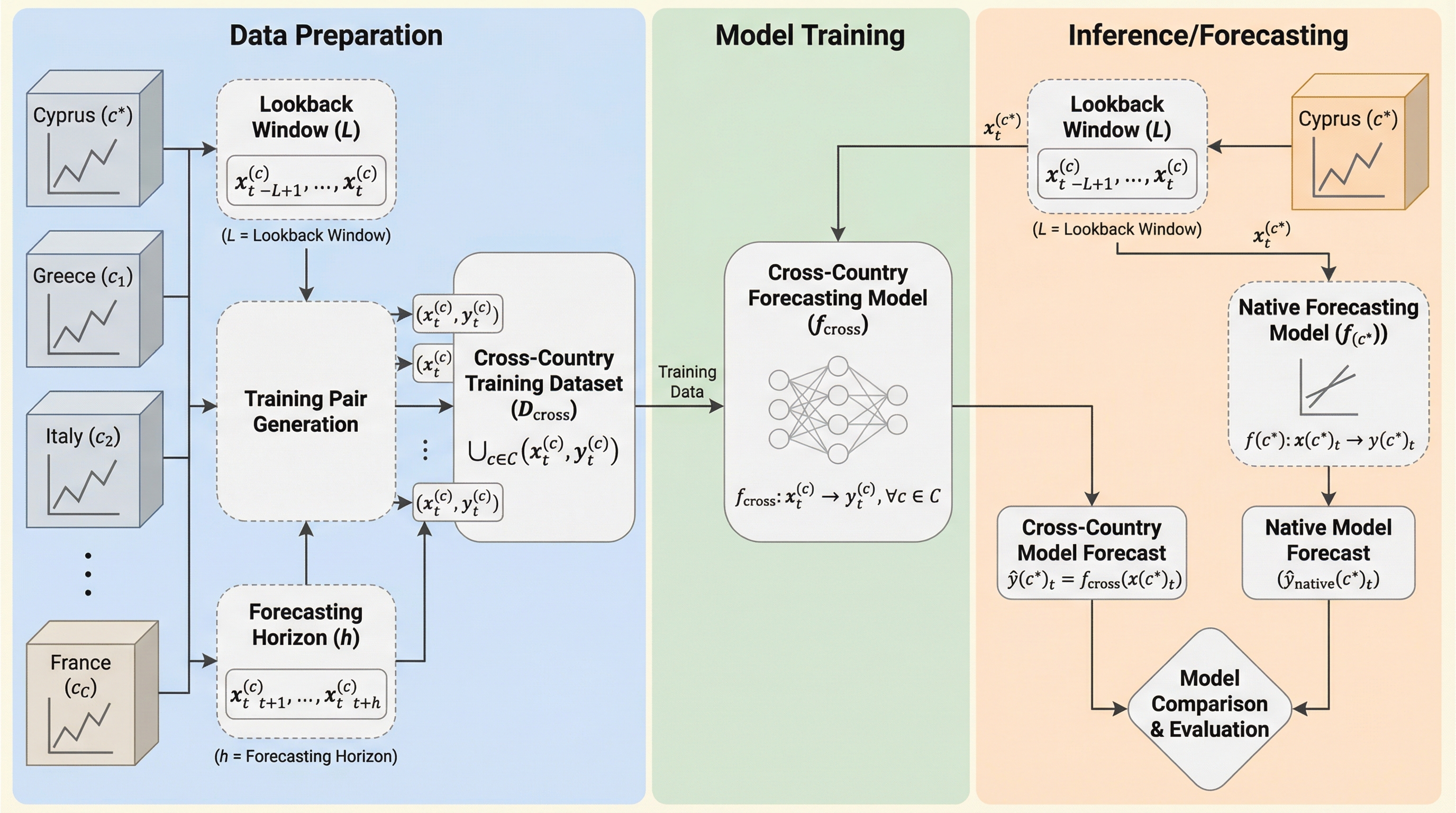
感染症予測において、単一国のデータのみでは学習サンプルが不足し精度が制限されるが、欧州諸国のデータを統合して学習する「クロス・カントリー学習」により、共通の疫学的動態を活用して予測精度を大幅に向上させることが可能である。

大規模言語モデルが抱える事実誤認や推論能力の欠如を解決するため、ニューラルネットワークの知覚能力と記号的・確率的な論理推論を統合した「ニューロシンボリックAI」が注目されていますが、従来のGPUやCPUでは記号推論や確率推論の処理効率が極めて低いという課題がありました。
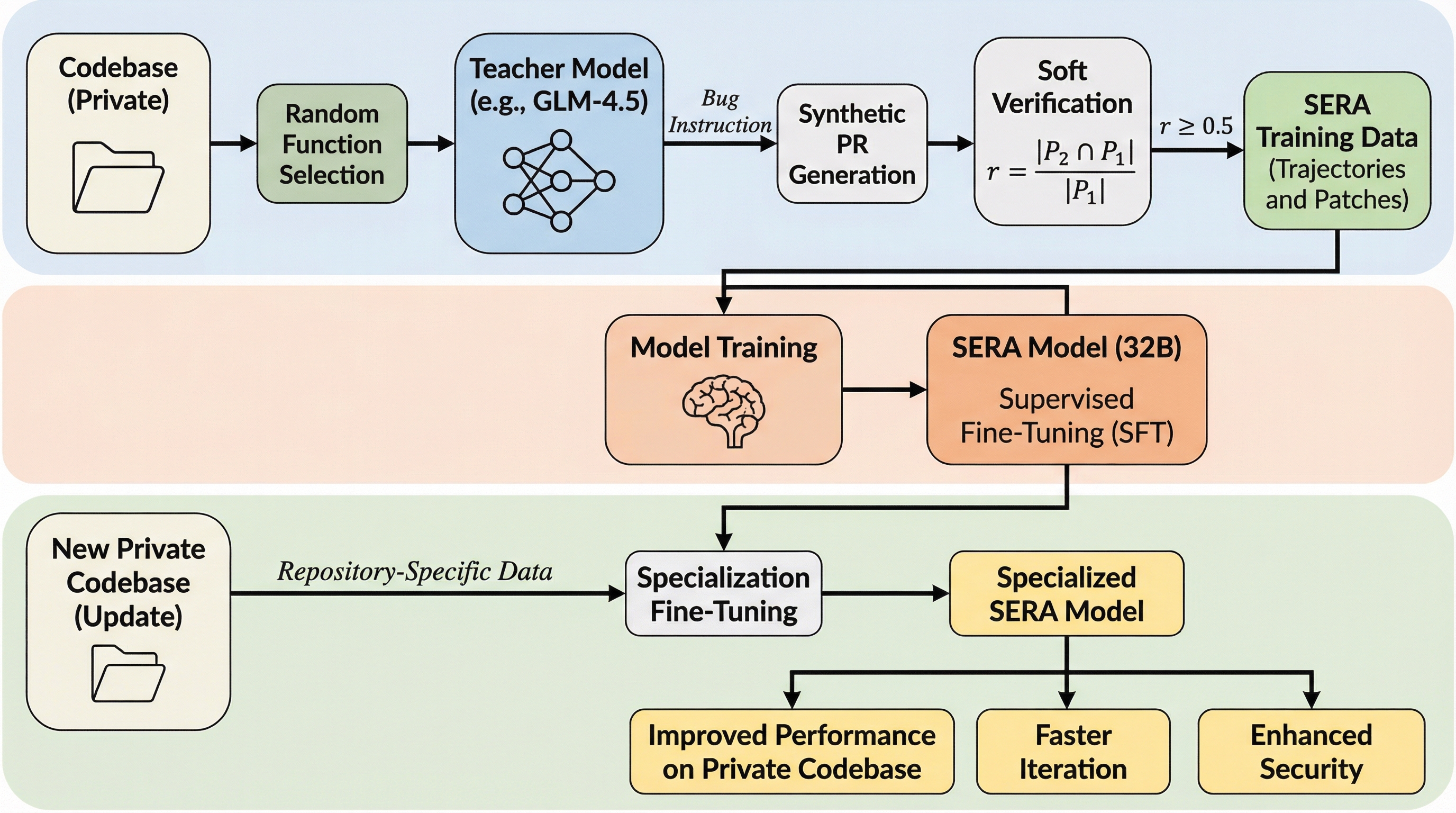
SERAは、プライベートなコードベースに特化可能なオープンソースのコーディングエージェントであり、従来の強化学習より26倍、既存の合成データ手法より57倍も安価に訓練できる手法を提案しています。
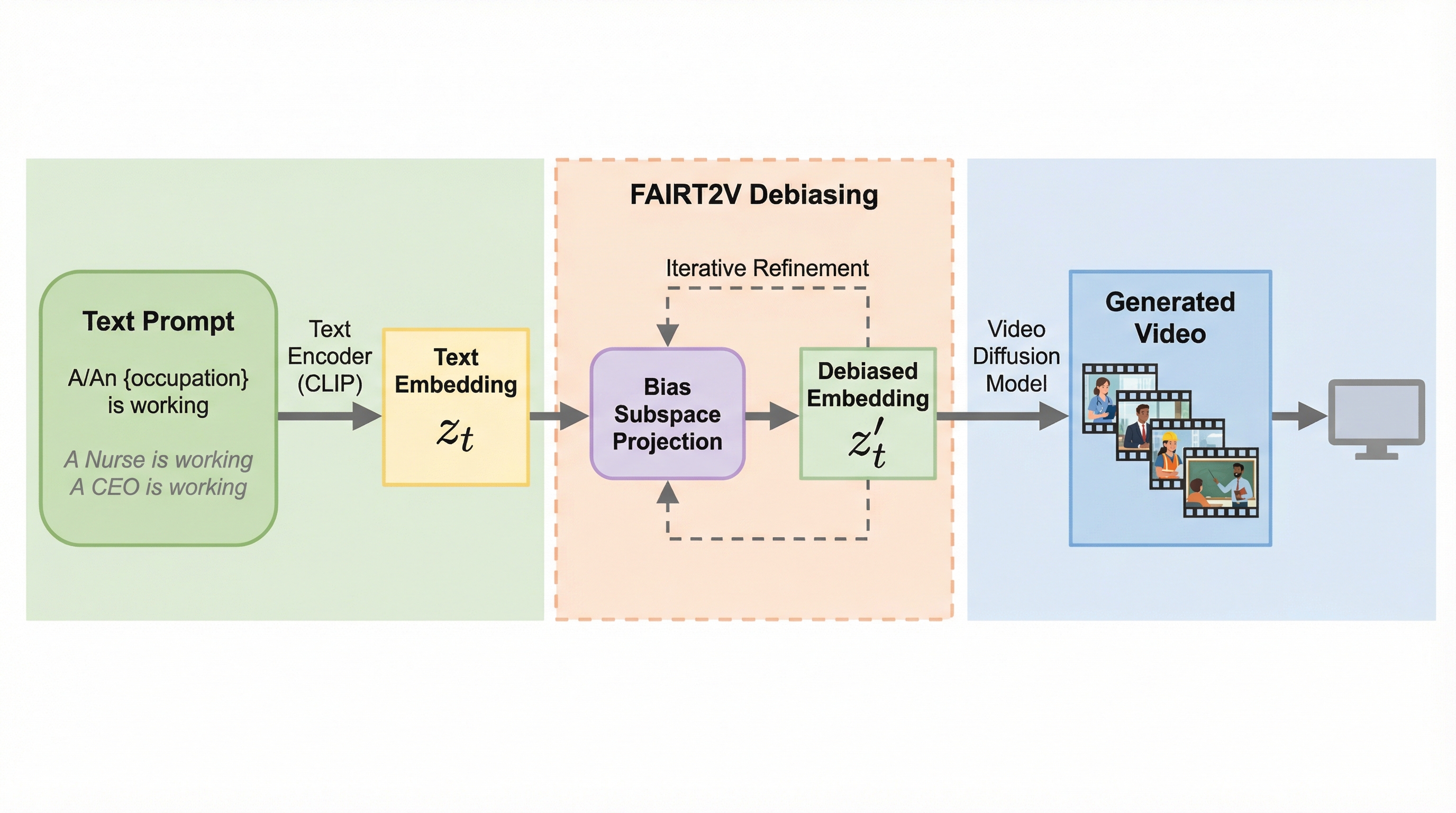
テキストから動画を生成する拡散モデル(T2V)において、特定の職業が特定の性別に偏って生成される深刻なジェンダーバイアスが存在することを特定し、その主な原因がCLIPなどの事前学習済みテキストエンコーダーにあることを詳細な分析によって明らかにしました。
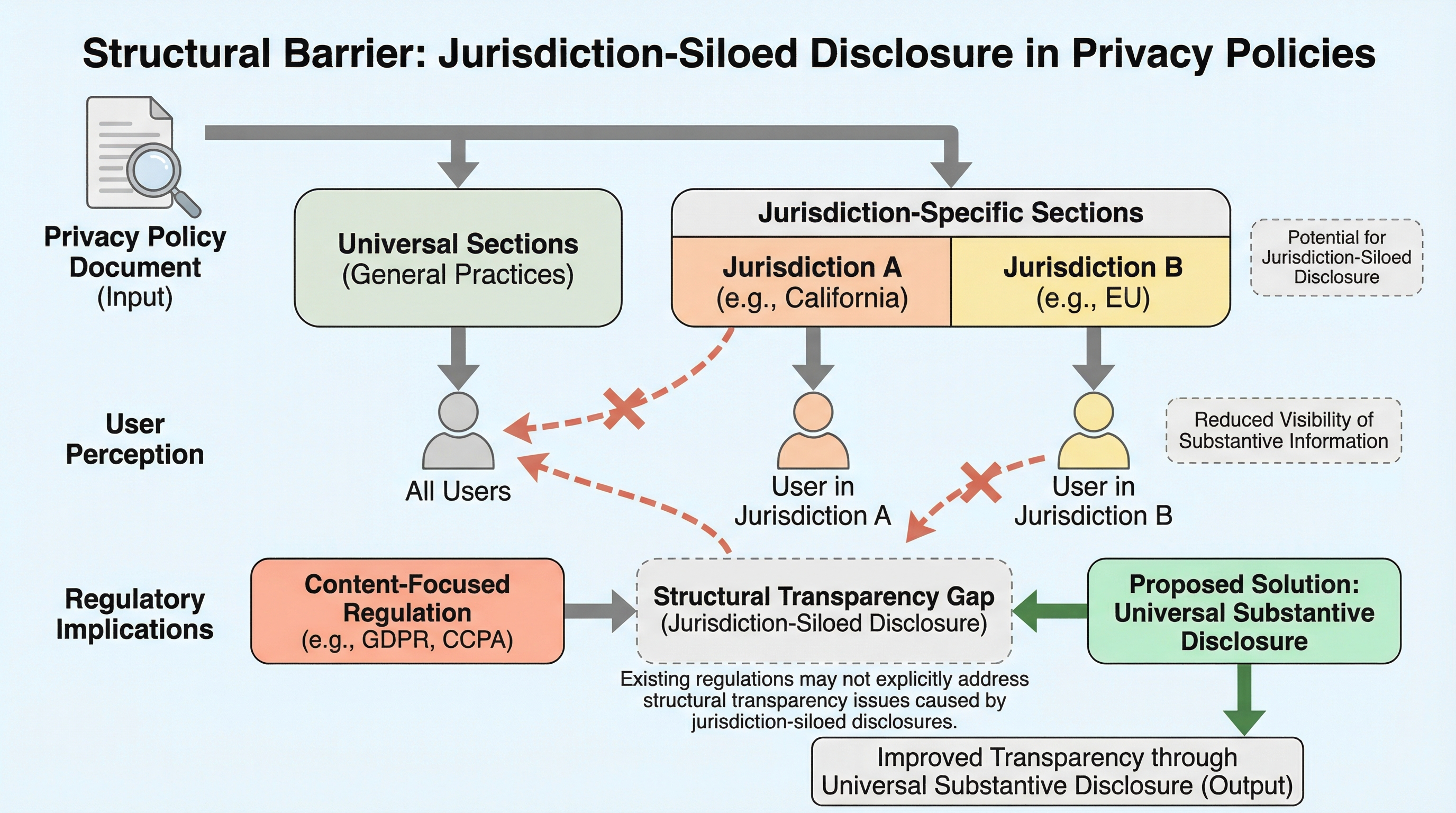
プライバシーポリシーにおいて、データの販売や生体情報の収集といった重要な実質的情報の開示が、特定の地域(カリフォルニア州や欧州など)の居住者向けセクションのみに限定され、一般セクションでは曖昧な表現に留まる「管轄権による情報のサイロ化」という構造的パターンを特定しました。
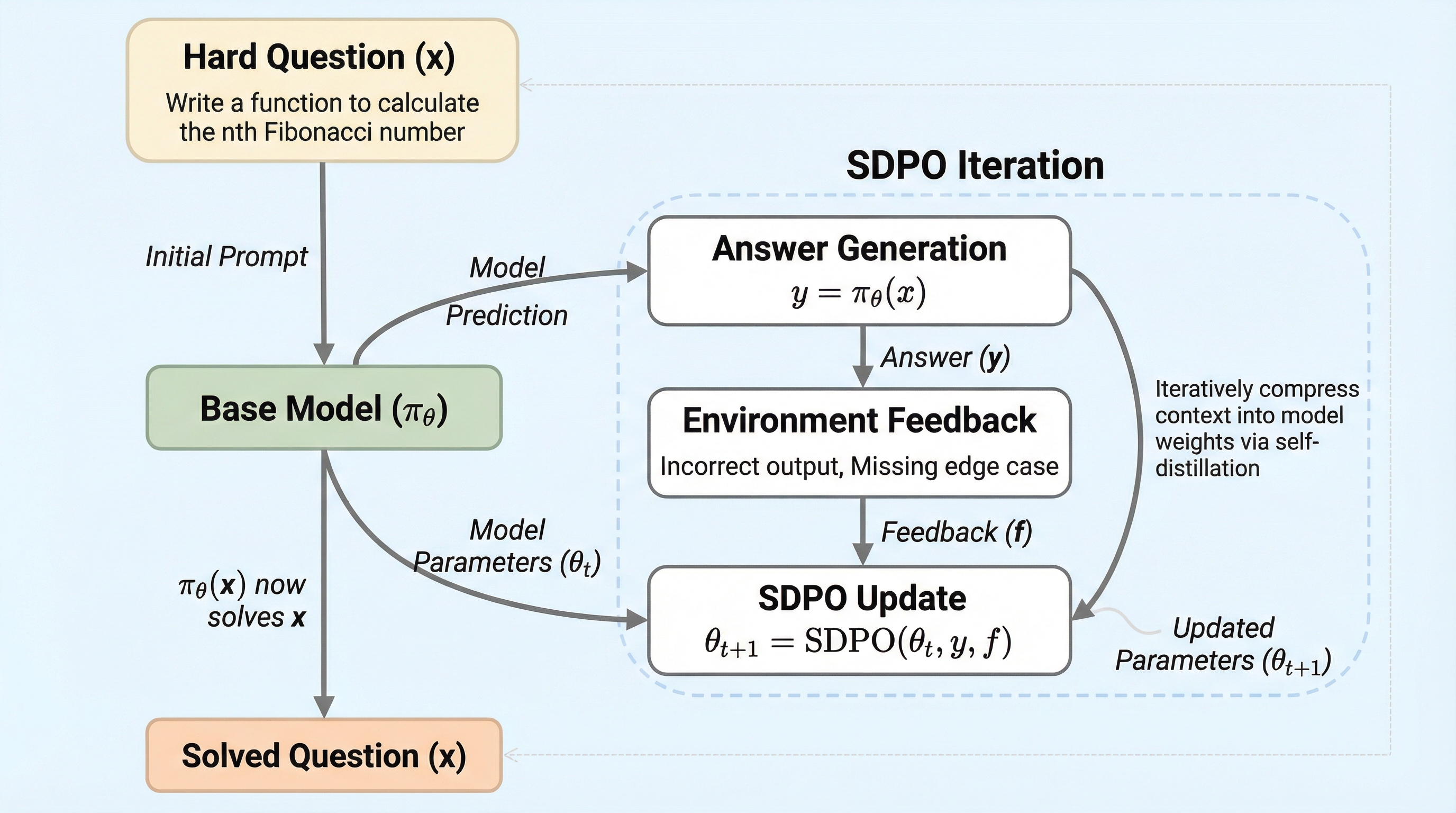
現在の強化学習(RLVR)は、成功か失敗かというスカラー値の報酬のみに依存しており、なぜ失敗したかという詳細な情報を学習に活かせないボトルネックがある。本研究が提案するSDPOは、実行エラーや判定結果などの「リッチなフィードバック」をモデル自身に読み込ませ、自己教師として過去の回答を再評価させることで、密度の高い学習信号を生成する手法である。検証の結果、科学的推論やプログラミングにおいて、既存手法のGRPOを大幅に上回る学習効率と精度を達成し、特に難易度の高い課題では3倍少ない試行回数で正解に到達することが確認された。
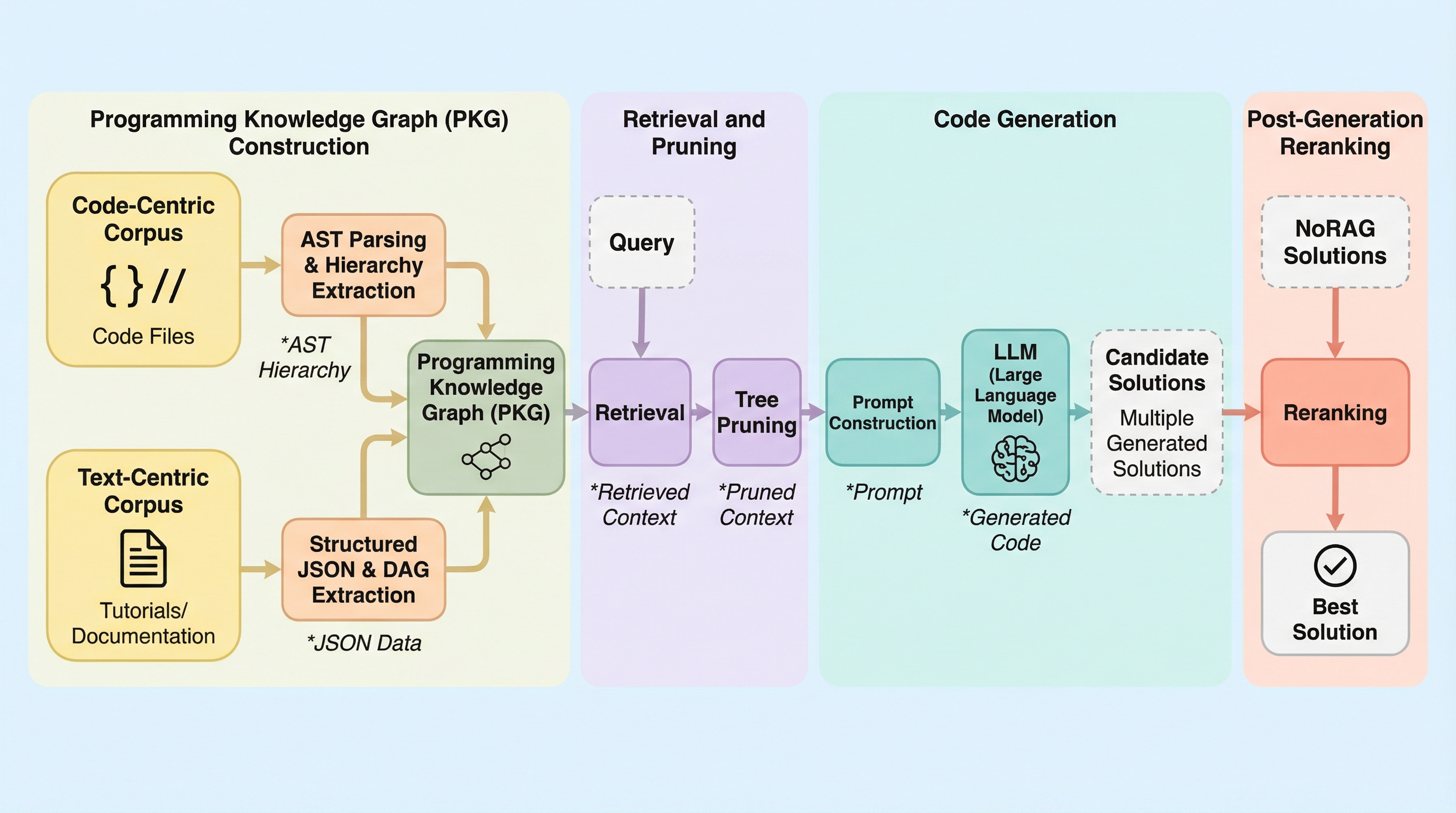
大規模言語モデルによるコード生成の精度を向上させるため、ソースコードの抽象構文木(AST)とドキュメントの構造をグラフ化した「プログラミング知識グラフ(PKG)」を提案している。 この手法は、情報の粒度を関数単位やブロック単位で制御し、不要な枝を切り落とすツリープルーニングや、生成後の再ランキングを組み合わせることで、検索精度の向上とハルシネーションの抑制を両立させている。 評価実験では、HumanEvalやMBPPといったベンチマークにおいて、既存の検索手法を最大34%上回る改善を確認し、複雑なプログラミング課題における有効性が示された。