構造的には人間的、意味的にはバイアス的:埋め込みとGNNを用いたLLM生成リファレンスの検出
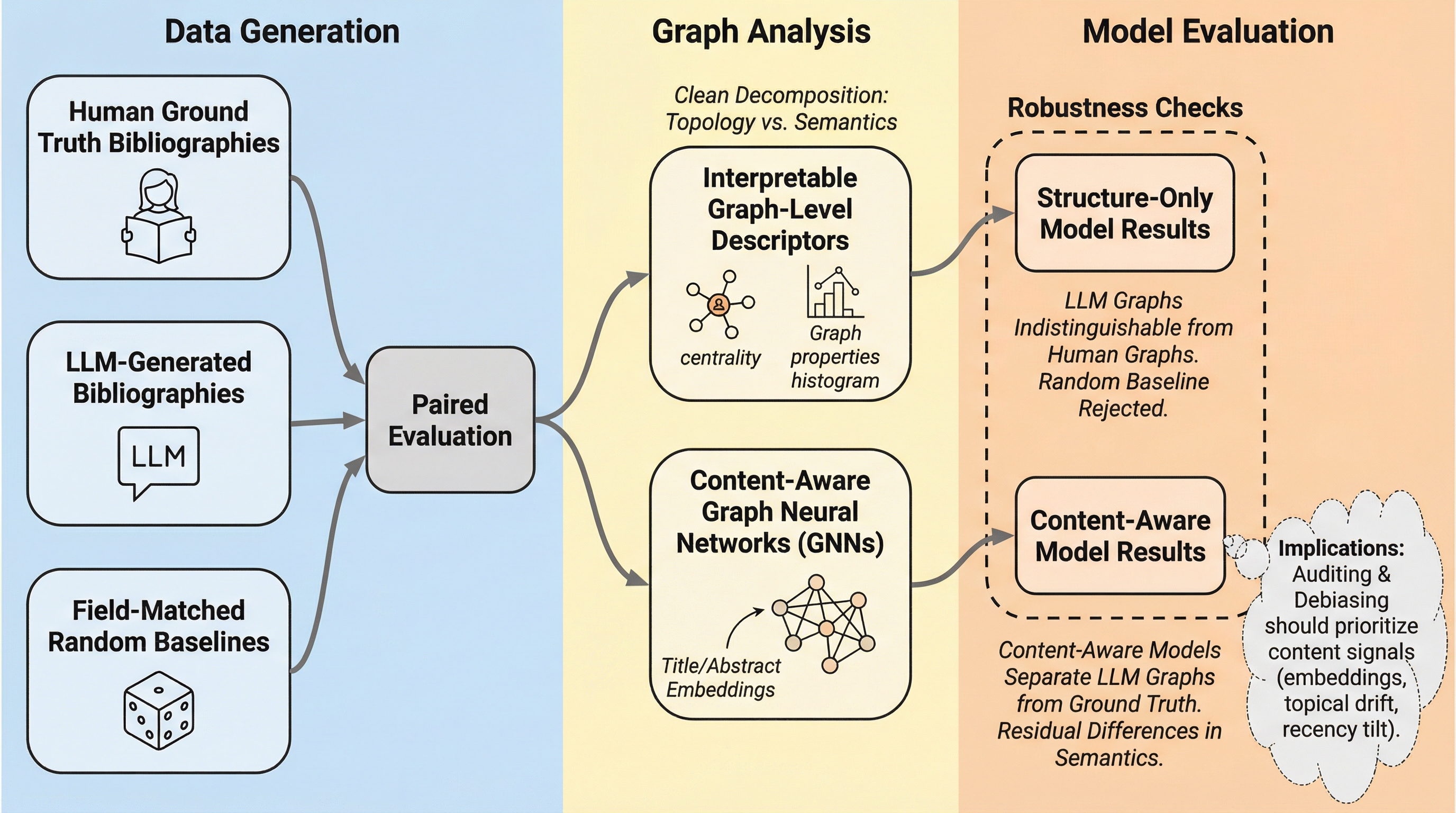
大規模言語モデル(LLM)が生成する参考文献リストは、引用ネットワークの構造的側面(中心性やクラスター係数など)において人間が作成したものと極めて高い類似性を持っており、従来のグラフ解析のみでは識別が困難であることが判明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)が生成する参考文献リストは、引用ネットワークの構造的側面(中心性やクラスター係数など)において人間が作成したものと極めて高い類似性を持っており、従来のグラフ解析のみでは識別が困難であることが判明しました。
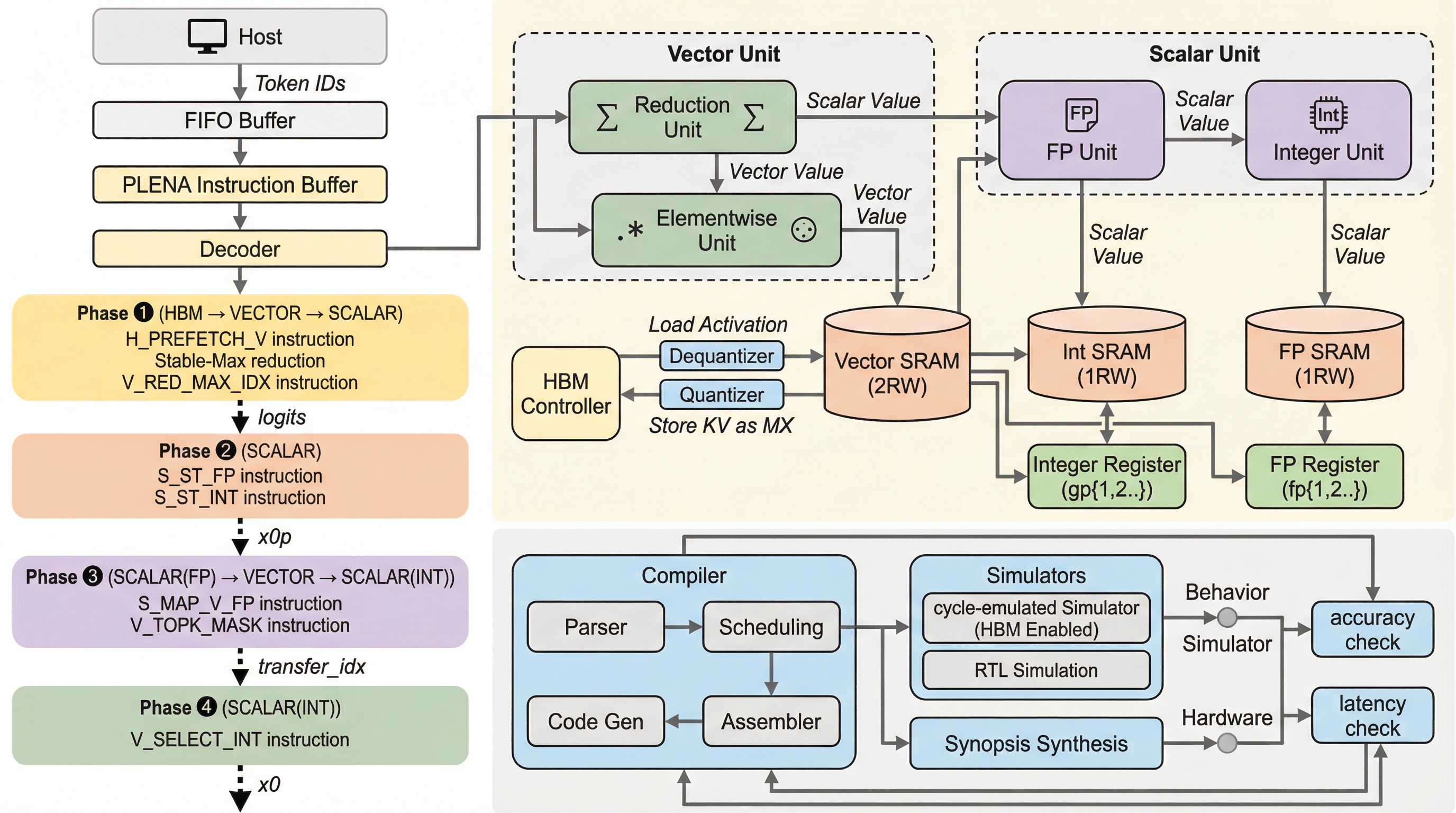
拡散型大規模言語モデル(dLLM)は並列的なトークン生成を可能にするが、語彙全体にわたるロジット処理やトークン選択を行うサンプリング工程が、推論全体の遅延の最大71%を占める深刻なボトルネックとなっている。
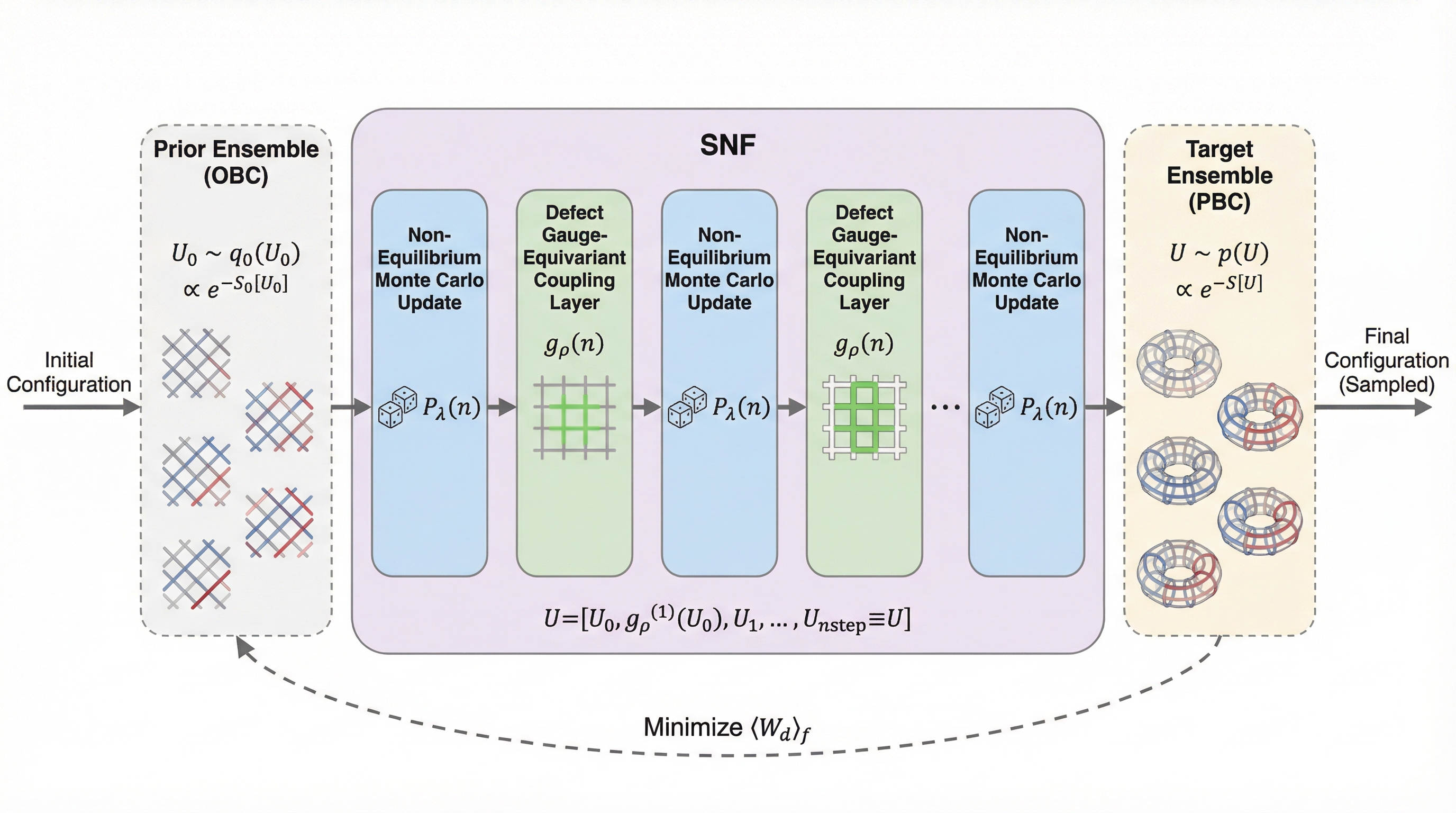
4次元SU(3)ゲージ理論の格子シミュレーションにおいて、連続極限でトポロジカルなサンプリングが困難になる「トポロジカルな凍結」を解決するため、確率的正規化フロー(SNF)を用いた新しい手法が提案されました。
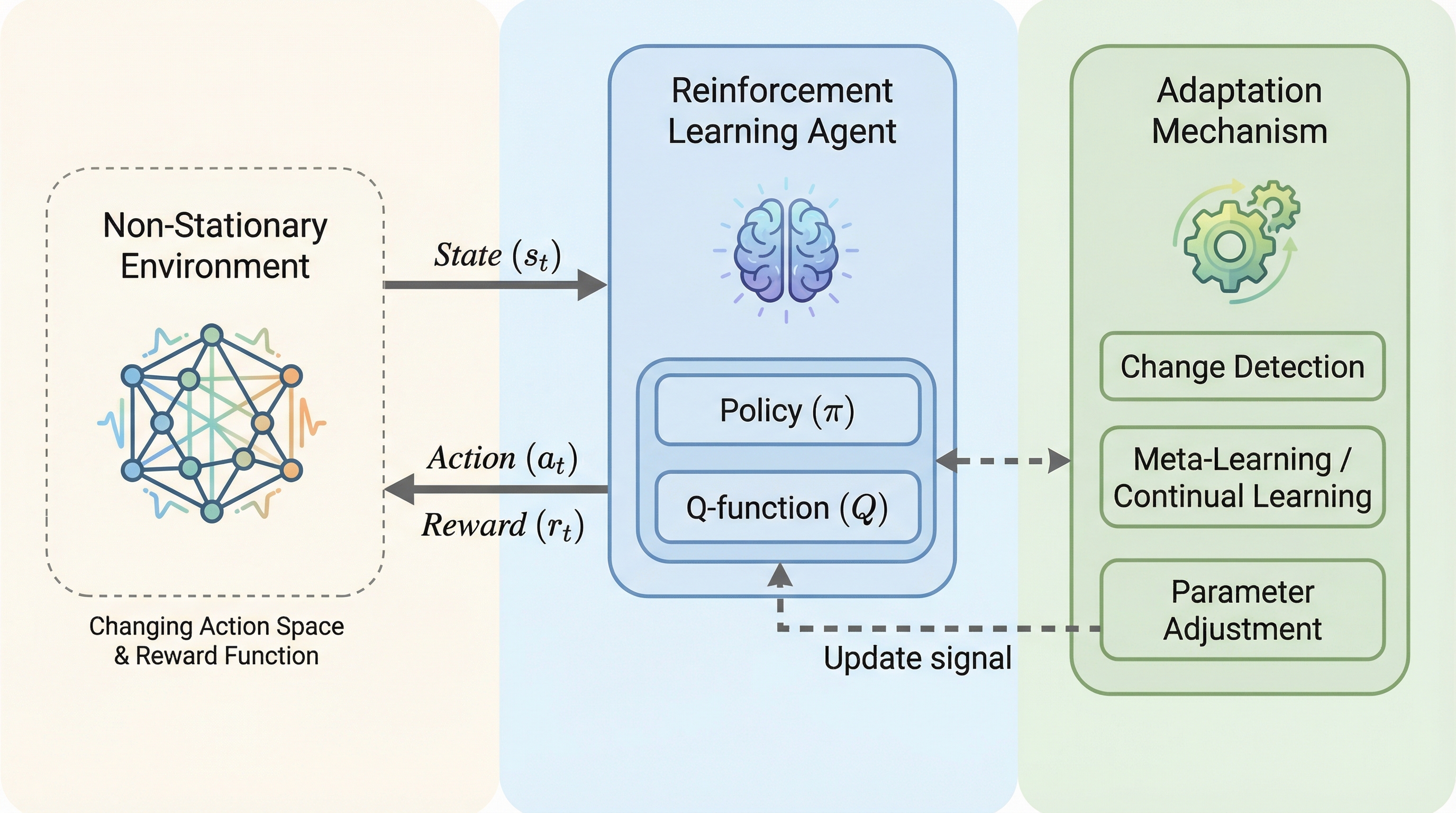
本研究は、報酬関数の変化や行動空間の拡大といった非定常な環境において、モデルを最初から再学習させることなくリアルタイムで適応可能な自己適応型強化学習フレームワーク「MORPHIN」を提案している。
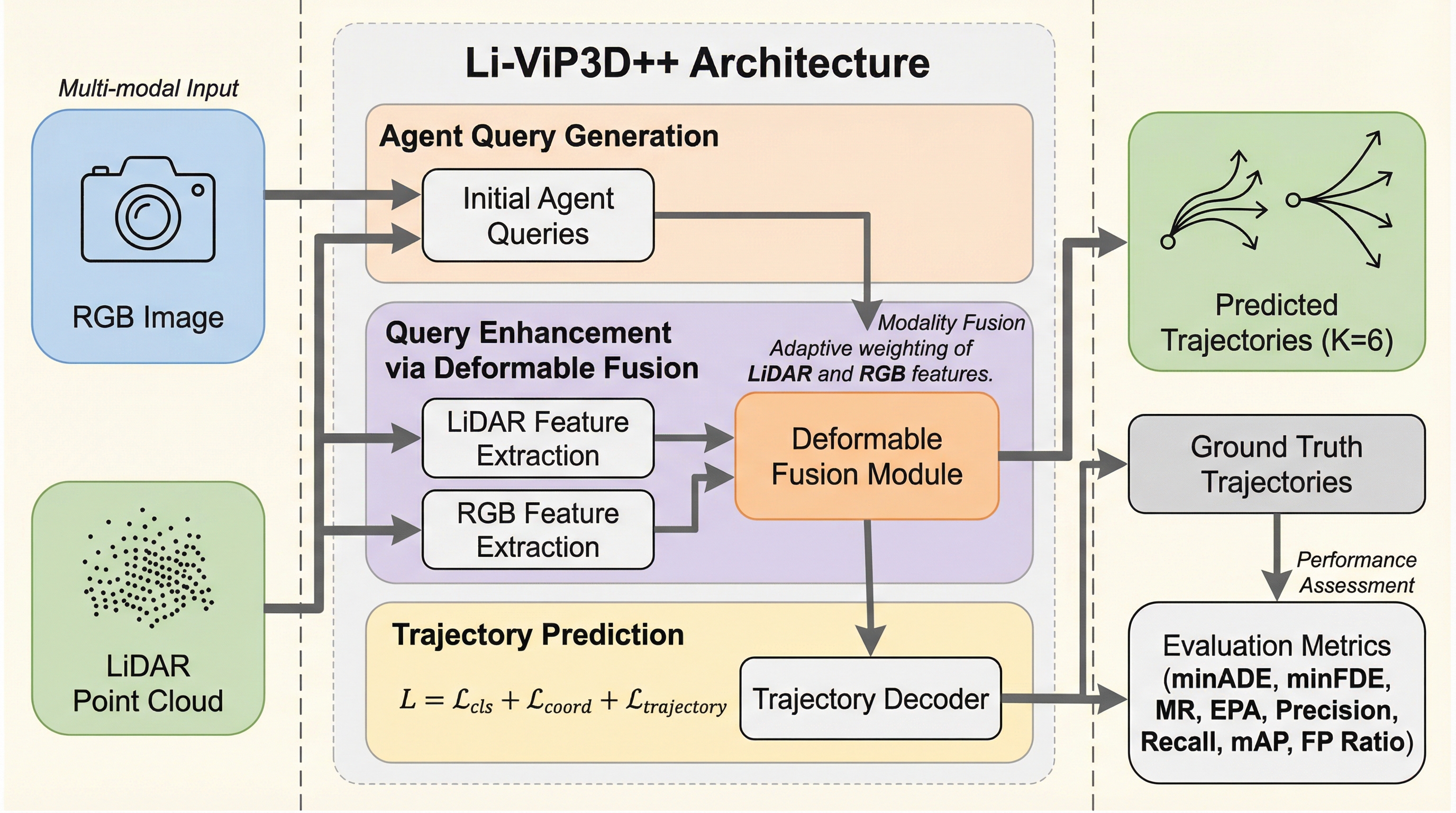
Li-ViP3D++は、自動運転における物体認識と軌跡予測を統合するエンドツーエンドのフレームワークであり、カメラとLiDARの情報をクエリ空間で融合するQuery-Gated Deformable Fusion(QGDF)を導入しています。
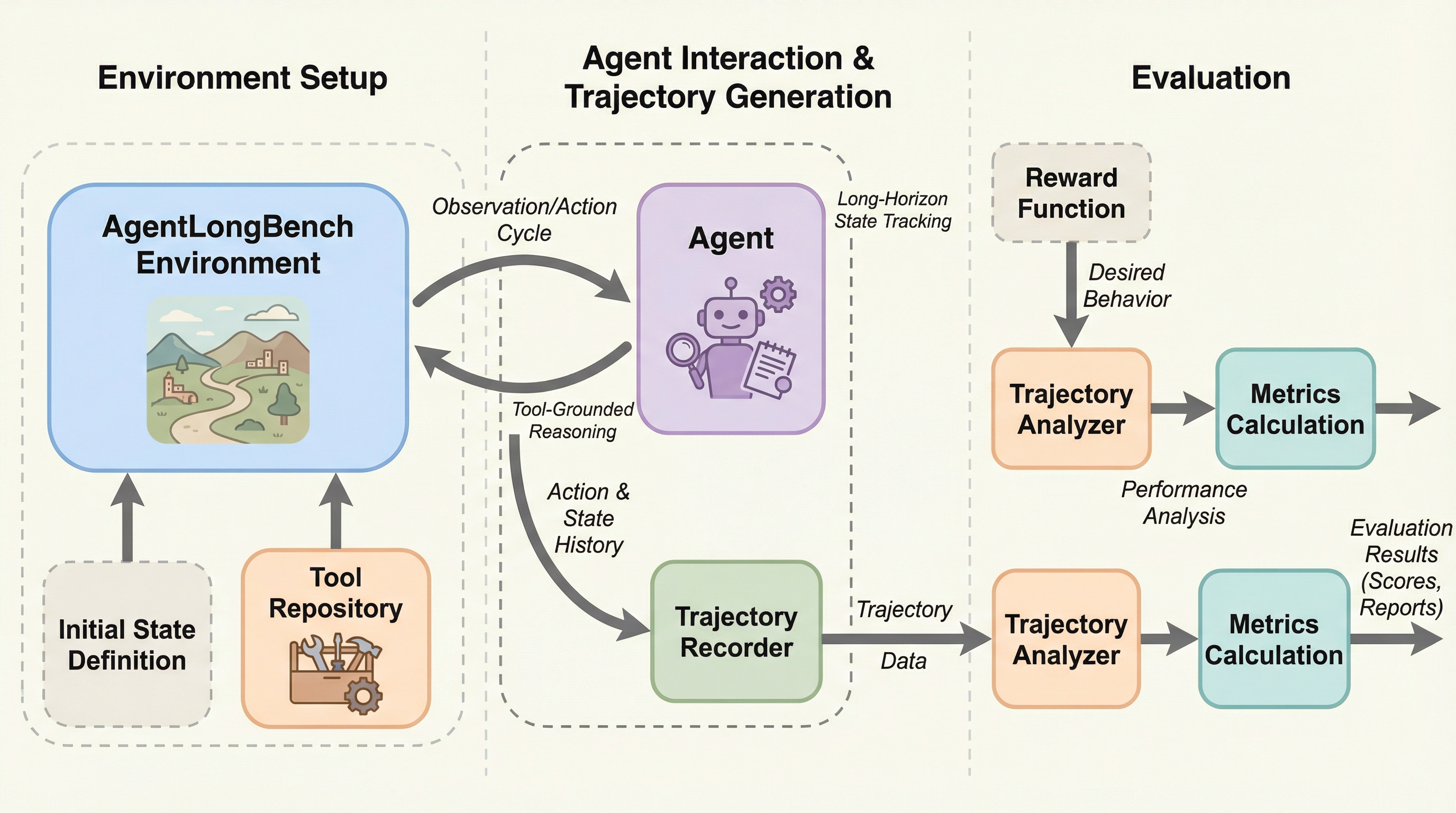
AgentLongBenchは、大規模言語モデルが自律的なエージェントとして機能するために必要な、動的で複雑な長文脈の管理能力を評価するための新しいベンチマークである。従来の静的な文書検索タスクとは異なり、水平思考パズルを用いた環境シミュレーションを通じて、エージェントと環境の相互作用や非線形な推論、反復的なフィードバックを伴うプロセスを再現している。最新のモデルやメモリシステムを最大400万トークンの文脈長で検証した結果、静的な検索には長けていても、ワークフローに不可欠な動的な情報の統合や高密度のツール応答の処理において、多くのモデルが深刻な課題を抱えていることが明らかになった。
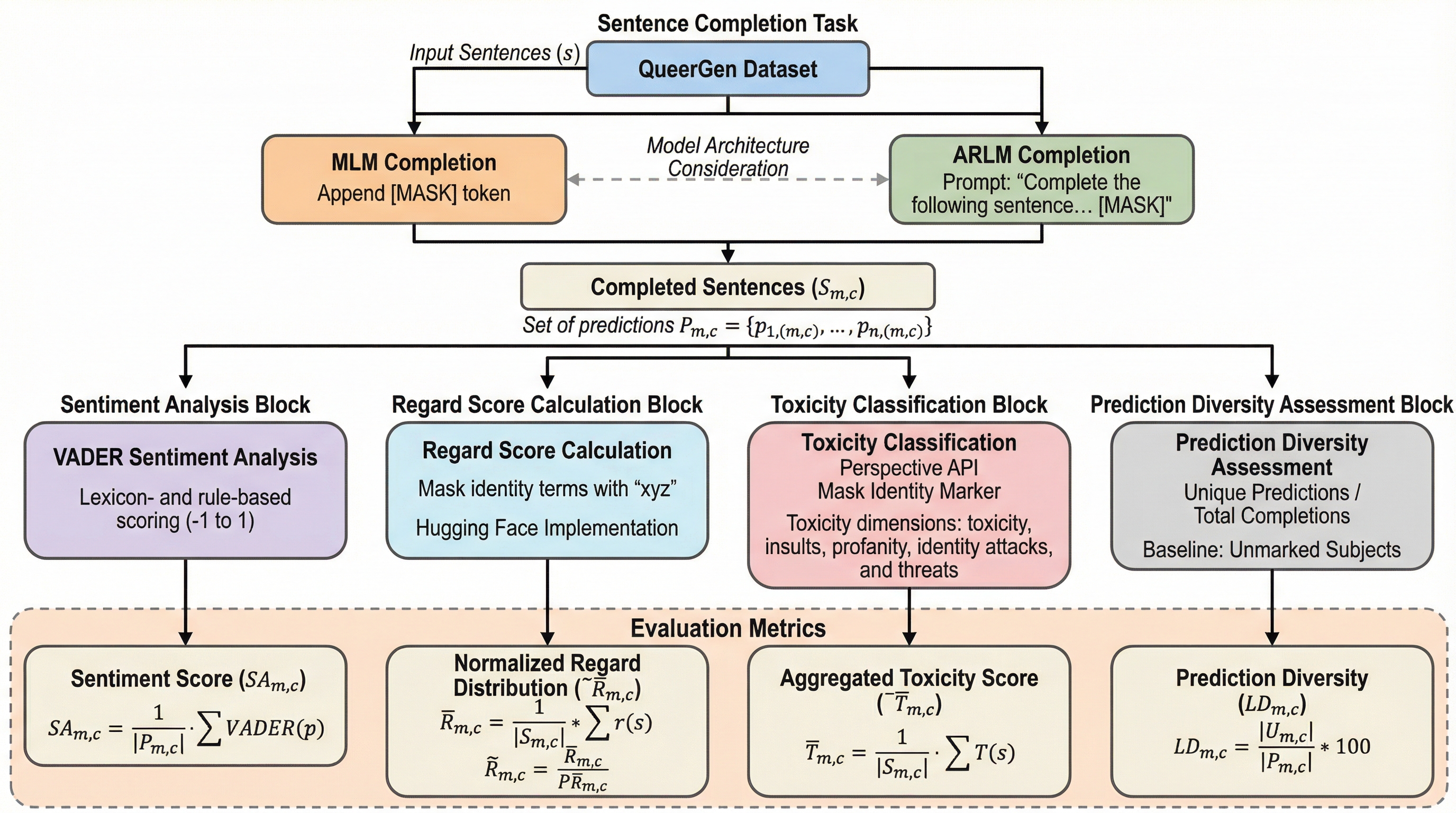
大規模言語モデル(LLM)が社会的な規範、特にヘテロシスノーマティビティ(異性愛規範およびシスジェンダー規範)をどのように再現し、それが生成テキストのバイアスとして現れるかを定量的に調査した研究である。
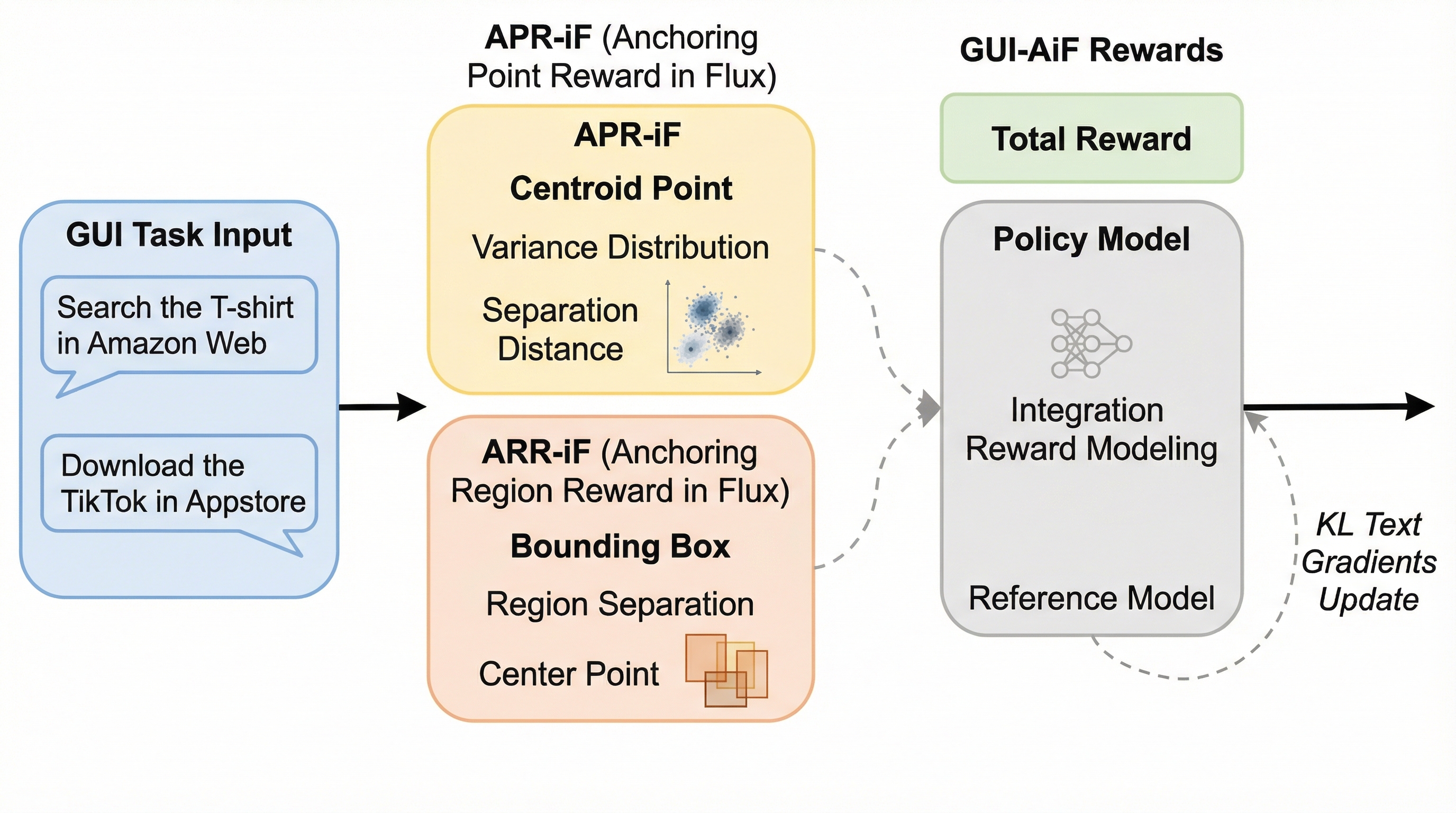
デジタル環境は新しいドメインや解像度の導入により常に変化しており、固定されたデータセットで学習した従来のGUIエージェントは性能が低下するという課題があります。 本研究では、変化する環境下で継続学習を行う「Continual GUI Agents」という新しいタスクと、多様な相互作用点と領域のアンカリングを強化する報酬枠組み「GUI-AiF」を提案しました。 検証の結果、提案手法はScreenSpot-V1、V2、Proの各ベンチマークにおいて、既存の教師あり微調整や強化学習ベースの手法を上回る世界最高水準の性能を達成しました。
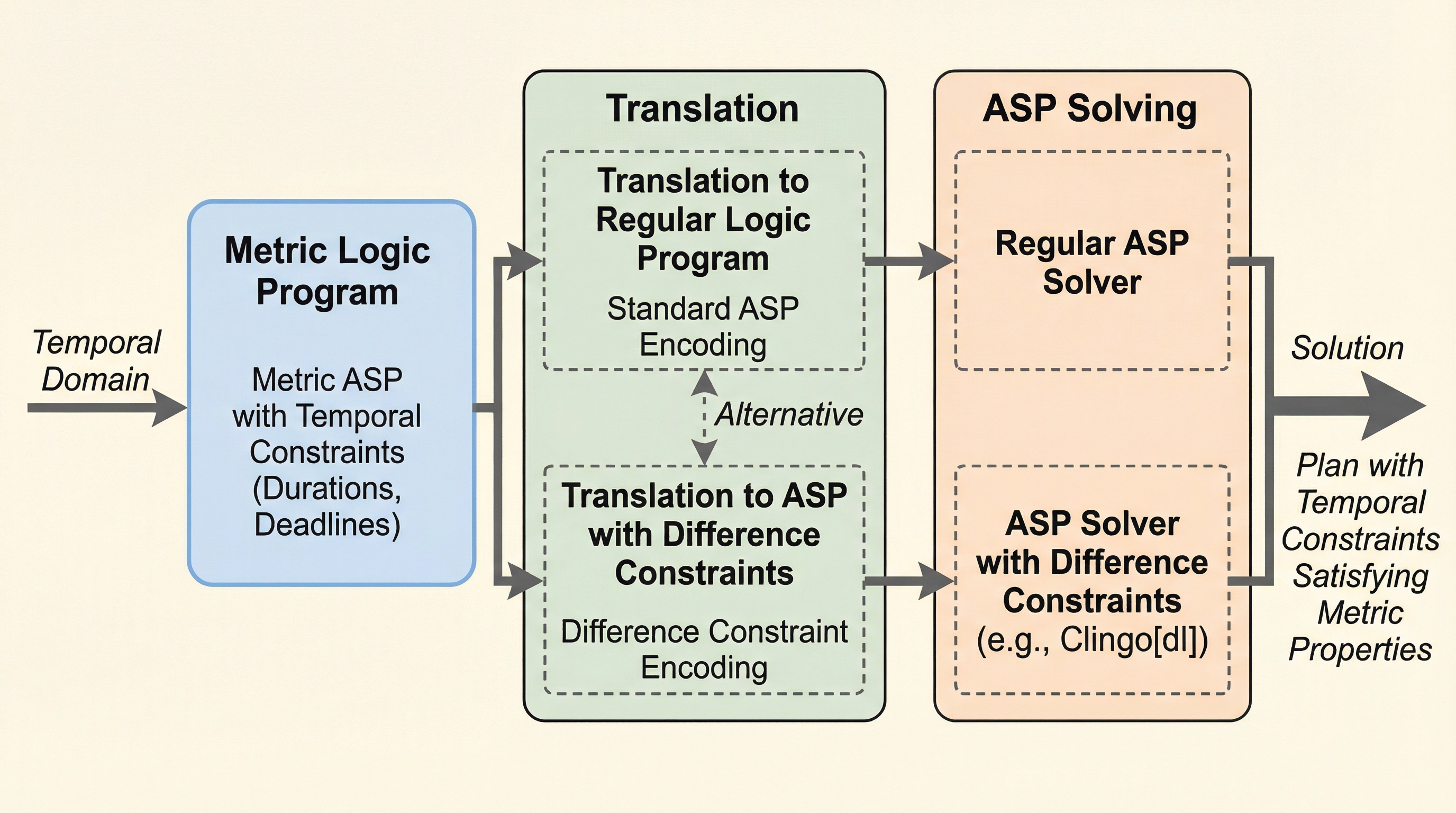
回答セットプログラミング(ASP)において、期間や締め切りといった定量的な時間制約を扱う際、時間の精度を上げると接地(グラウンディング)の負荷が爆発的に増大する問題がありました。 / 本研究では、差分制約という簡略化された線形制約を導入して時間処理を外部化することで、時間の粒度に依存しないスケーラブルな計算手法を提案し、その論理的な正当性を証明しました。 / 具体的には、メトリック論理プログラムを通常の論理プログラムや差分制約付きプログラムへ変換する二つの翻訳手法を開発し、時間の最大値や精度に関わらず、プログラムの規模をトレースの長さに比例する範囲に抑えることを可能にしました。
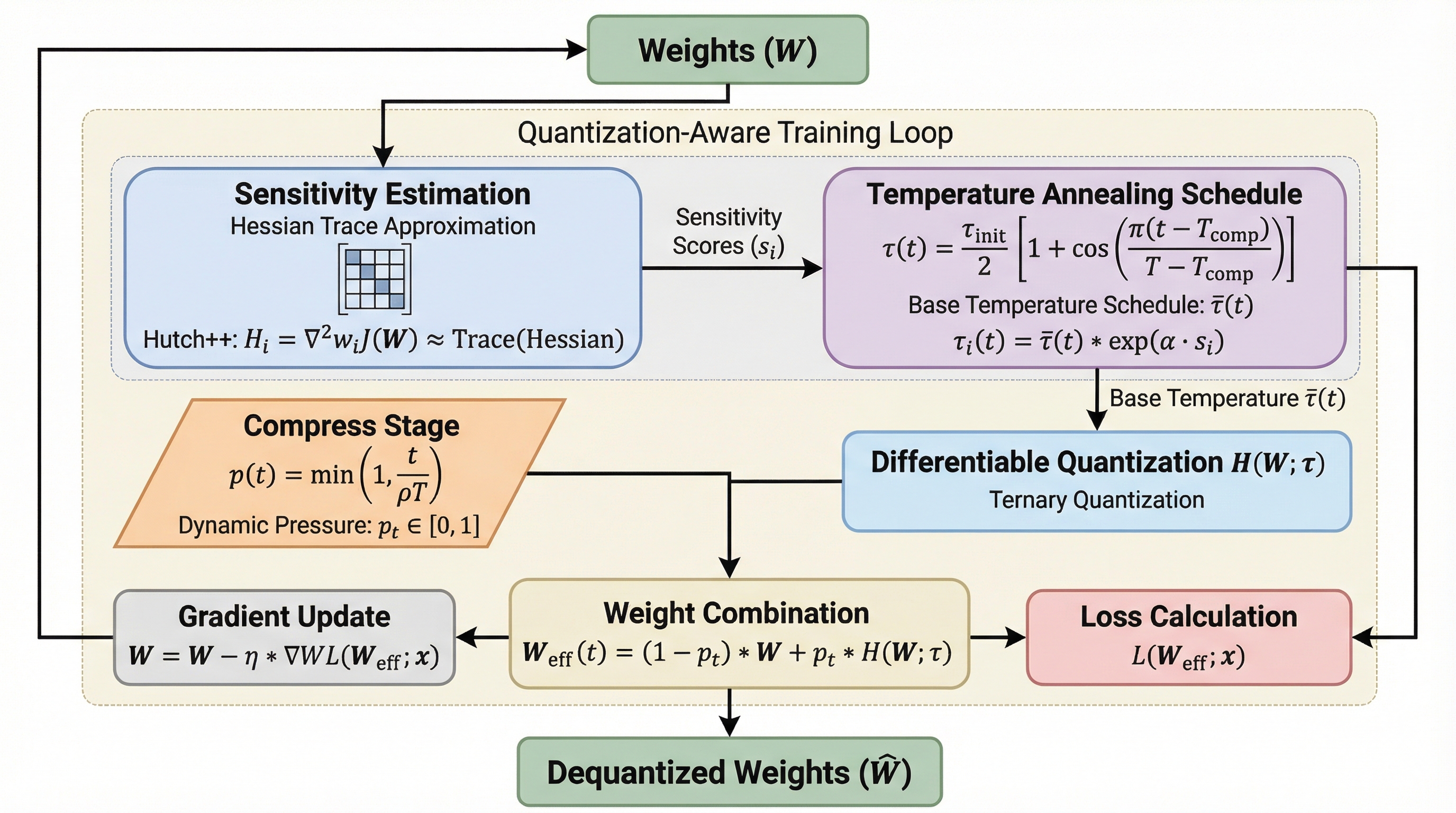
大規模言語モデル(LLM)のメモリ消費を抑えるため、重みを{-1, 0, 1}の3値に圧縮する1.58ビット量子化が注目されていますが、従来の量子化手法では硬い丸め処理による勾配の不一致や、重みの更新が停滞する「デッドゾーン問題」が性能向上の大きな障壁となっていました。