GraphAllocBench: 選好条件付き多目的強化学習のための柔軟なベンチマーク
多目的強化学習における選好条件付き方策学習(PCPL)は、ユーザーが指定した目的間の選好(重み)に基づいて、単一のモデルで多様なパレート最適解を近似することを目指す手法であり、実行時に任意のトレードオフへ柔軟に適応できる利点を持つ。
TL;DR(結論)
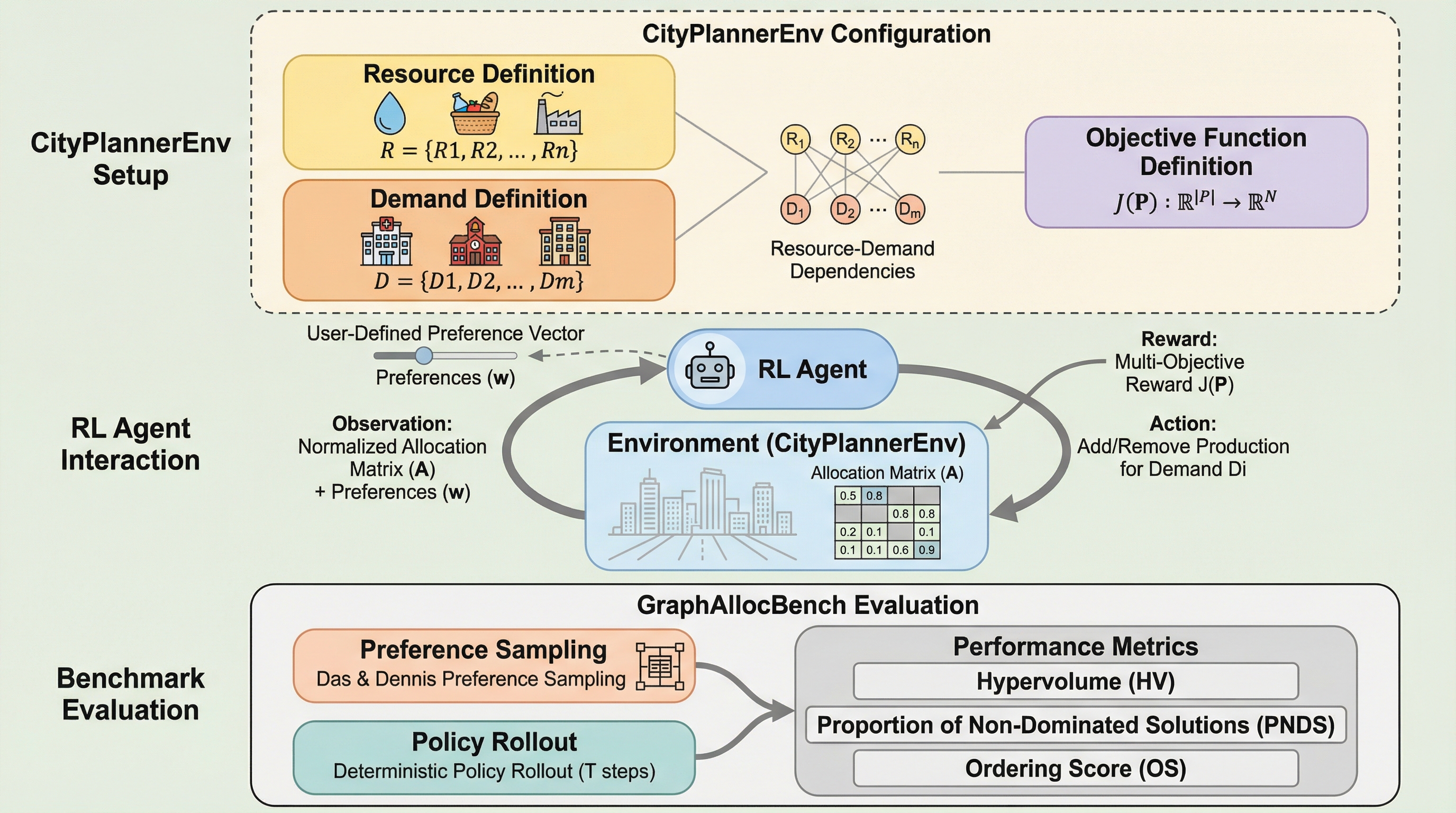
多目的強化学習における選好条件付き方策学習(PCPL)は、ユーザーが指定した目的間の選好(重み)に基づいて、単一のモデルで多様なパレート最適解を近似することを目指す手法であり、実行時に任意のトレードオフへ柔軟に適応できる利点を持つ。 既存のベンチマークが単純なグリッドタスクや固定された環境に限定されていた課題を解決するため、都市管理のリソース配分に着想を得たグラフベースの環境「CityPlannerEnv」と、それを用いた柔軟なベンチマーク「GraphAllocBench」が提案された。 本研究では、従来のハイパーボリューム指標を補完する新しい評価指標として、非支配解の割合(PNDS)と順序スコア(OS)を導入し、グラフニューラルネットワークを用いることで複雑な依存構造を持つ高次元タスクへの対応能力と選好への忠実さを実証した。
なぜこの問題か
強化学習はビデオゲーム、ロボティクス、大規模言語モデルの微調整などの分野で大きな進歩を遂げてきたが、その多くは単一の報酬関数を最適化するアルゴリズムに基づいている。しかし、現実世界の環境の多くは、互いに相反する複数の目的を含んでおり、単一の報酬値に集約することが困難な場合が多い。例えば、ゲーム内のキャラクターは、敵にダメージを与えること、自身のダメージを避けること、そして生存時間を最大化することのバランスを取る必要がある。このような場合、各目的には異なる重要度、すなわち「選好」が存在する。 従来の多目的強化学習(MORL)の一般的なアプローチは、スカラー化と呼ばれる手法であり、選好の重みを用いて複数の目的を一つの報酬に統合するものである。しかし、この手法では学習された方策が特定の固定された選好に縛られてしまい、新しい選好に対応するためには再学習が必要になるという欠点がある。また、進化計算アルゴリズム(NSGA-IIIなど)を用いて方策の集団を訓練したり、複数の単一目的モデルを訓練してパレートフロントを近似したりする手法も存在するが、これらは計算効率が悪く、新しい選好に対してゼロから再学習が必要になる。…
核心:何を提案したのか
本研究では、既存のベンチマークの限界を打破するために、都市規模のリソース配分に着想を得た新しいサンドボックス環境「CityPlannerEnv」と、それに基づいたベンチマークセット「GraphAllocBench」を提案した。CityPlannerEnvは、グラフベースの環境において、任意かつスケーラブルな複雑さを持つ多目的計画を可能にするGymnasiumベースの環境である。都市管理においては、渋滞の緩和、経済成長の促進、持続可能性の向上といった、しばしば対立する多様な需要に対して、限られたリソースを配分する必要がある。このプロセスを、二部グラフを用いた逐次的なリソース配分問題としてモデル化している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related