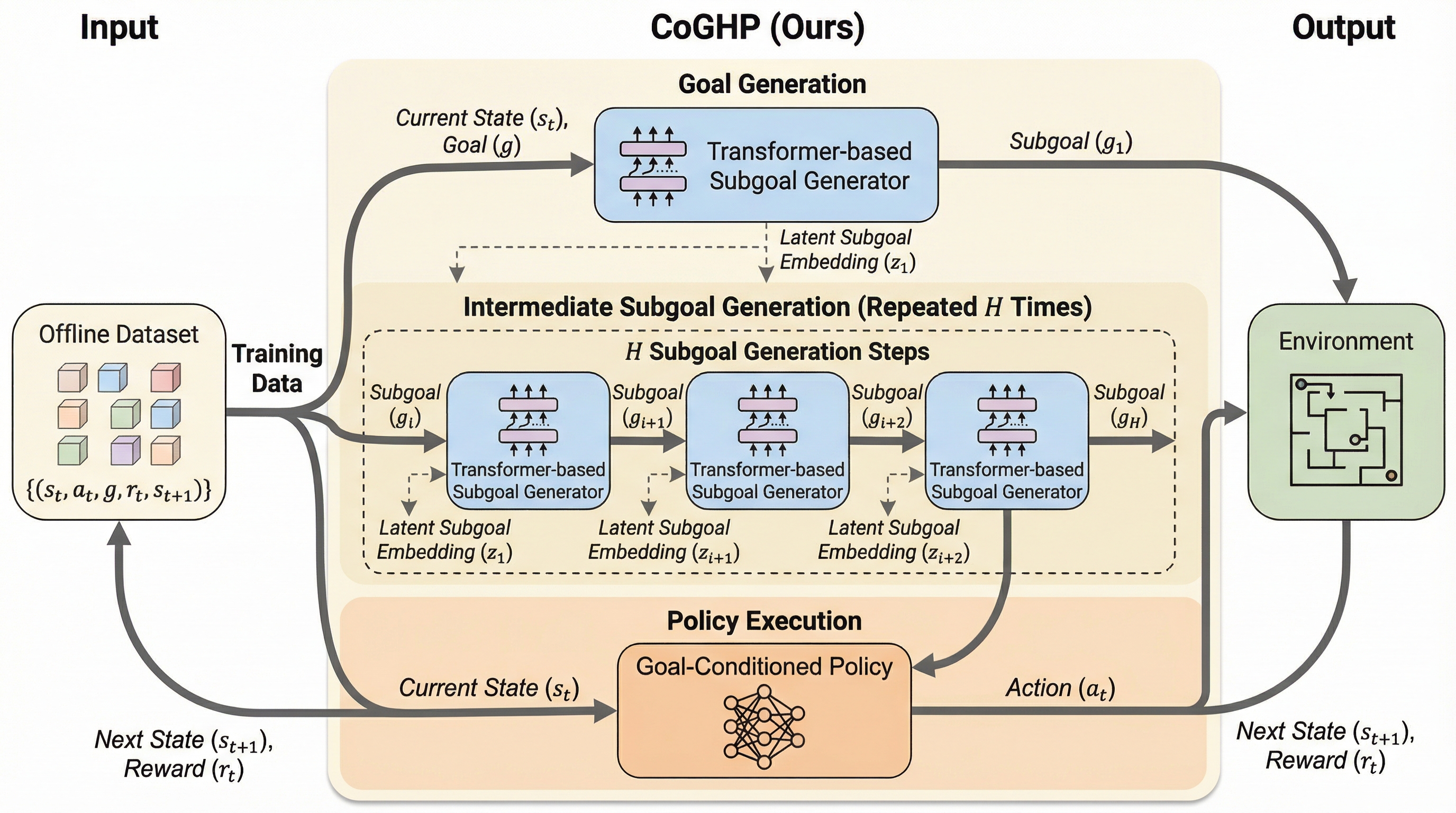
長期ホライゾンのオフライン・ゴール条件付き強化学習のためのゴールの連鎖階層的方策
従来のオフライン階層的強化学習は、高レベルと低レベルのネットワークが分離されているため、複雑なタスクで最終ゴールを見失いやすく、単一の中間ゴールしか生成できないという構造的な限界を抱えていました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のオフライン階層的強化学習は、高レベルと低レベルのネットワークが分離されているため、複雑なタスクで最終ゴールを見失いやすく、単一の中間ゴールしか生成できないという構造的な限界を抱えていました。
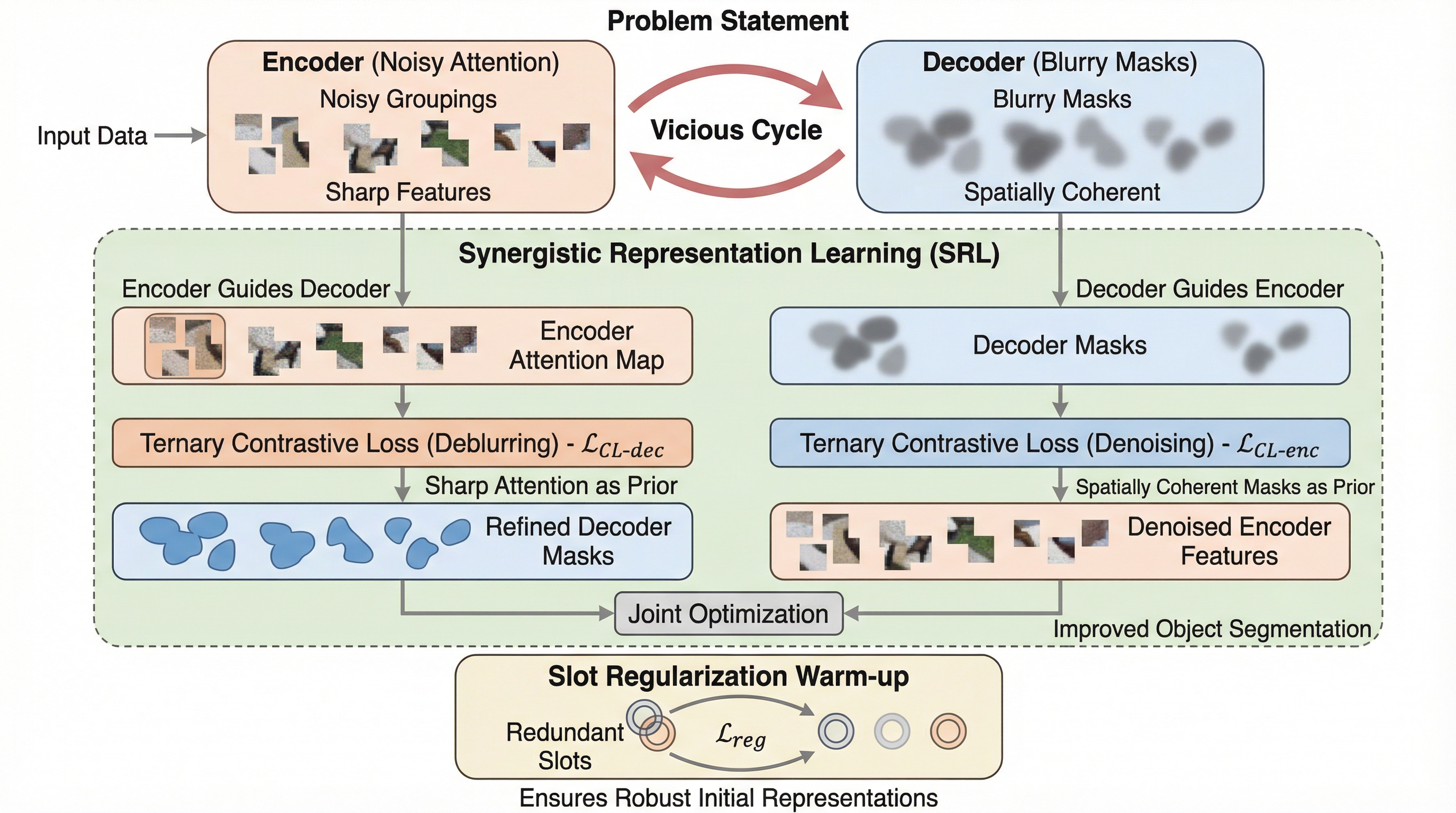
ビデオ物体中心学習において、エンコーダが生成する鋭いがノイズの多いアテンションマップと、デコーダが生成する空間的に一貫しているが境界がぼやけた再構成マップが、互いの学習を阻害し合う「悪循環」を特定しました。
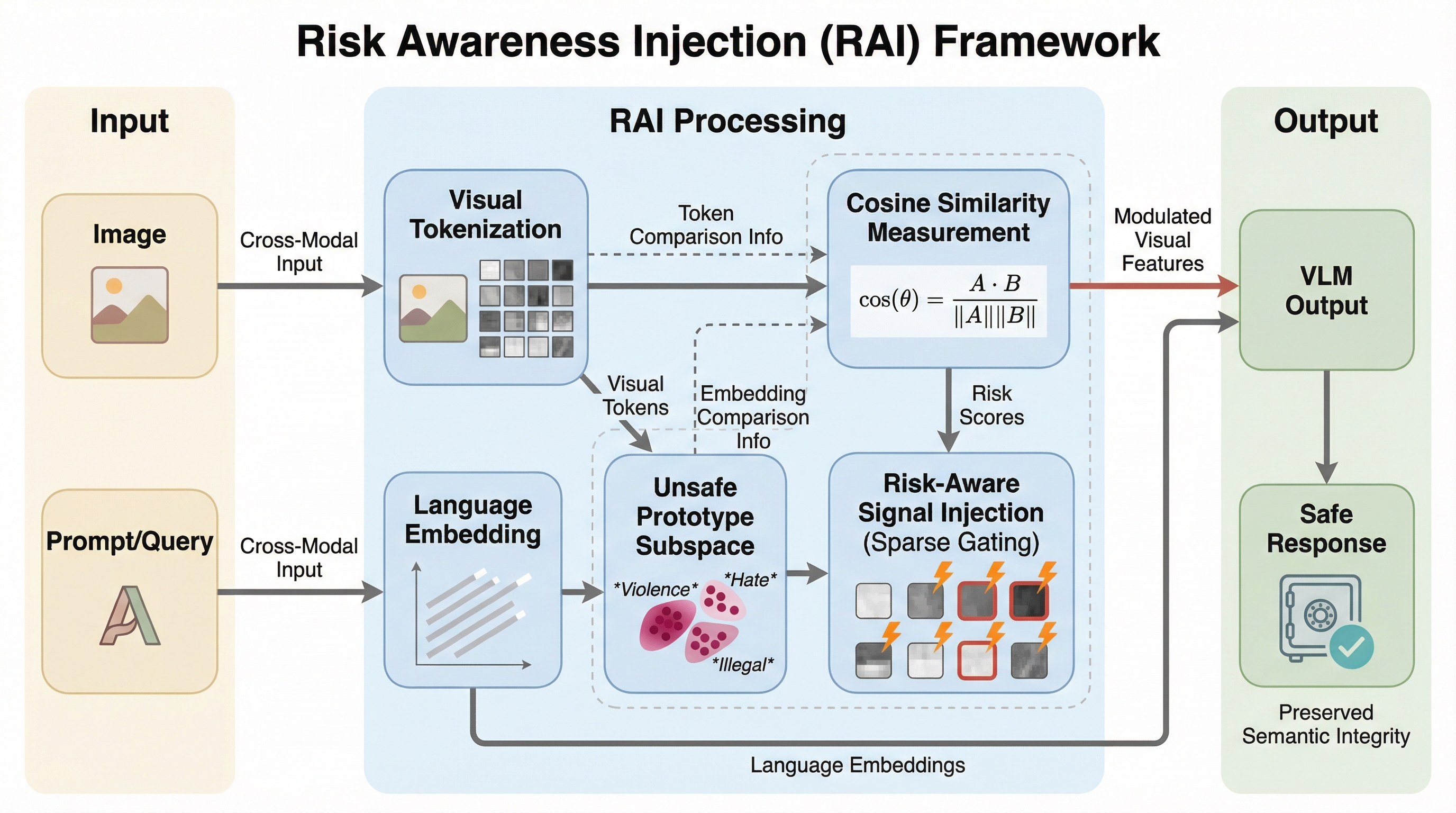
視覚言語モデル(VLM)は、視覚情報の統合によって本来の安全ガードレールが機能しなくなる「リスク信号の希釈」という課題を抱えており、画像や動画を悪用したマルチモーダルな脱獄攻撃に対して極めて脆弱です。
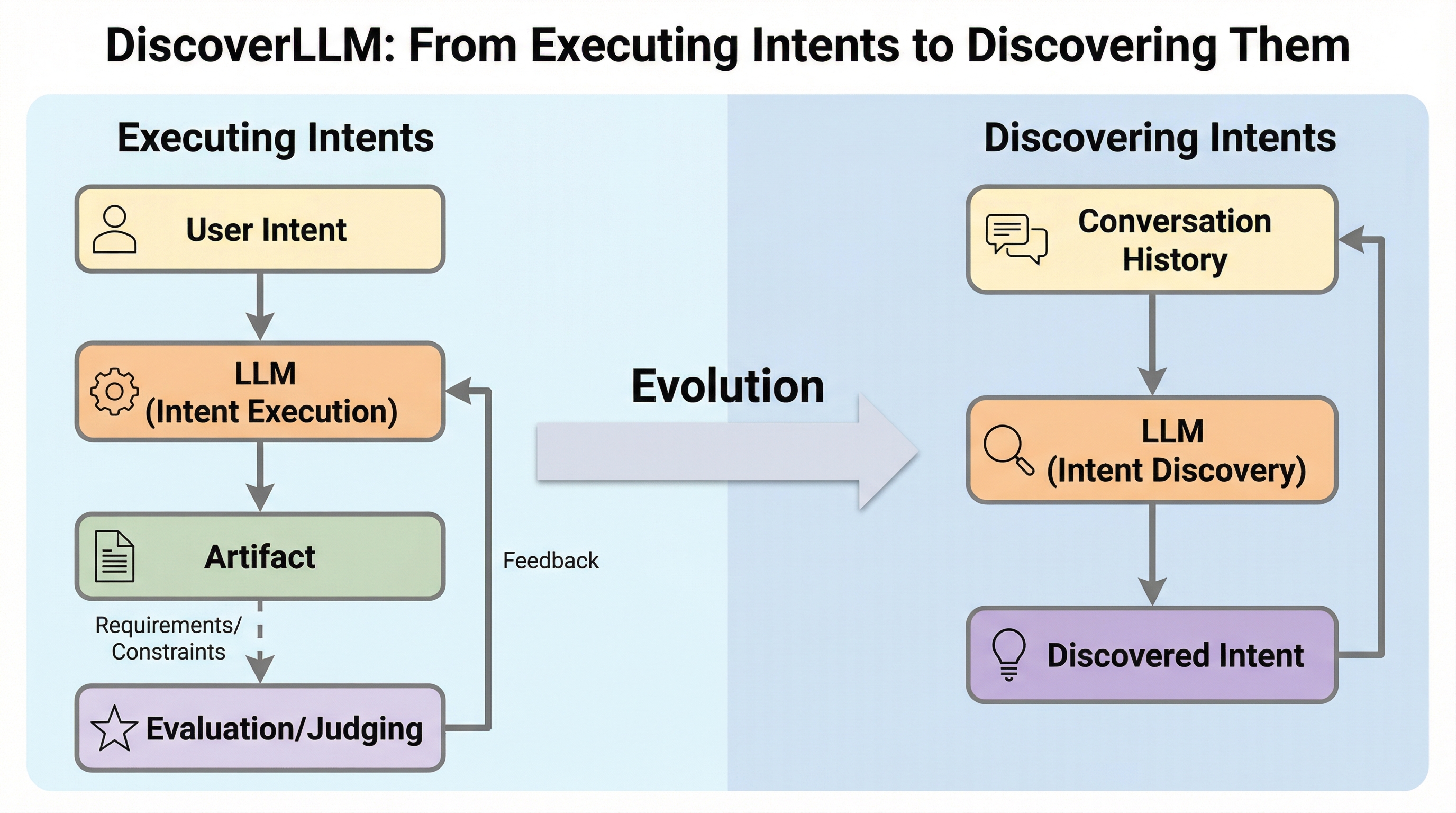
ユーザーが自身の望みを完全には言語化できていない「未形成の意図」を持つ状況において、従来の大規模言語モデルは具体的な質問を繰り返すだけであり、ユーザーが答えを持っていない場合には効果的に機能しないという課題がありました。
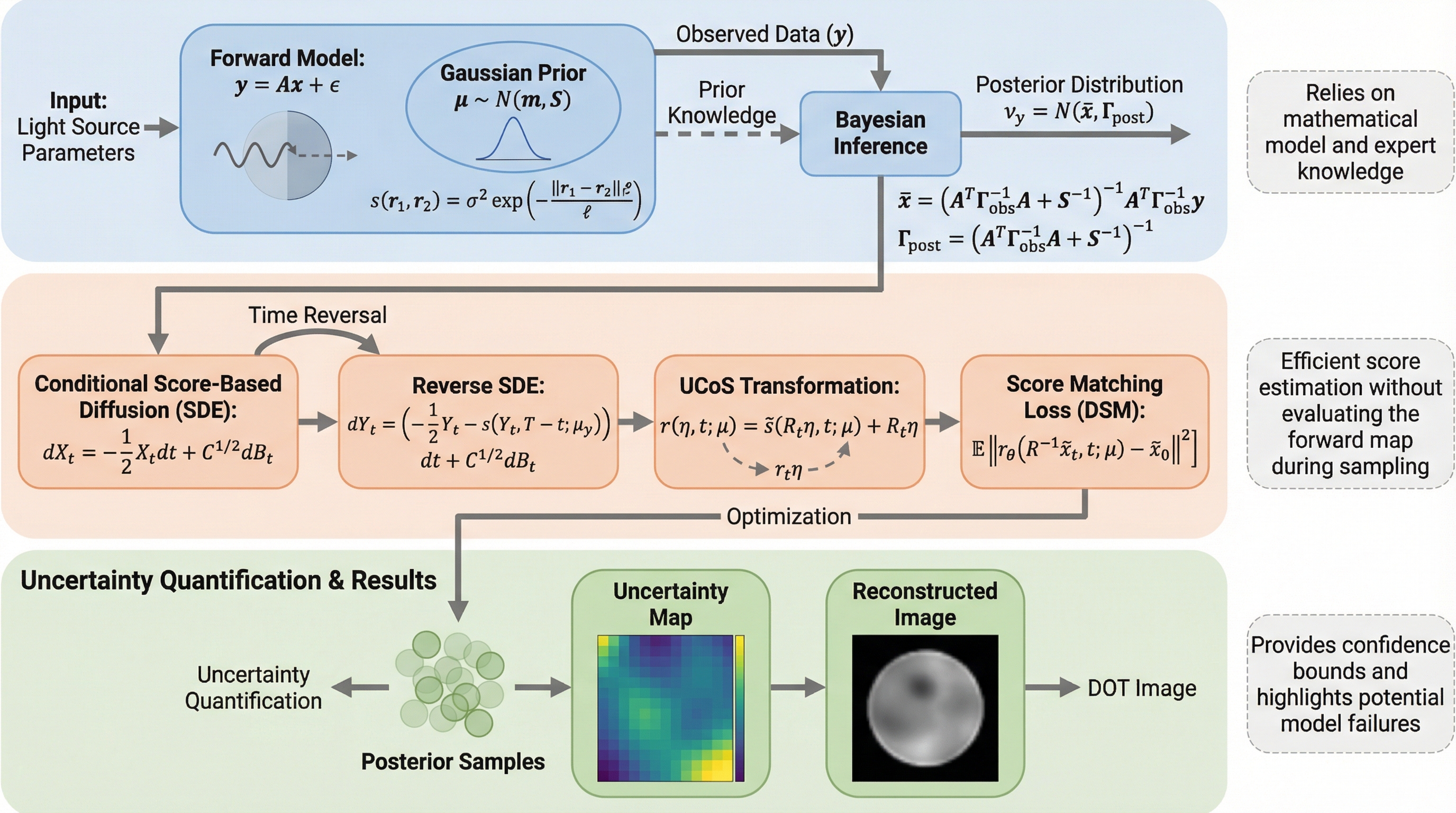
拡散光トモグラフィ(DOT)における高度な不良設定性とモデル誤差の課題に対し、スコアベース拡散モデルを用いた新しい事後サンプリング枠組みであるUCoSを適用した。 学習済みのデータ駆動型スコアと物理モデルに基づくガウス型スコアを凸結合させる新しい正則化手法を提案し、限定的な観測条件や分布外データに対する推定のロバスト性を向上させた。 シミュレーションおよび実測データを用いた検証により、従来手法よりも事後分散を大幅に抑制し、ターゲット周辺に不確実性を局在化させた信頼性の高い画像再構成と不確実性定量化を実現した。
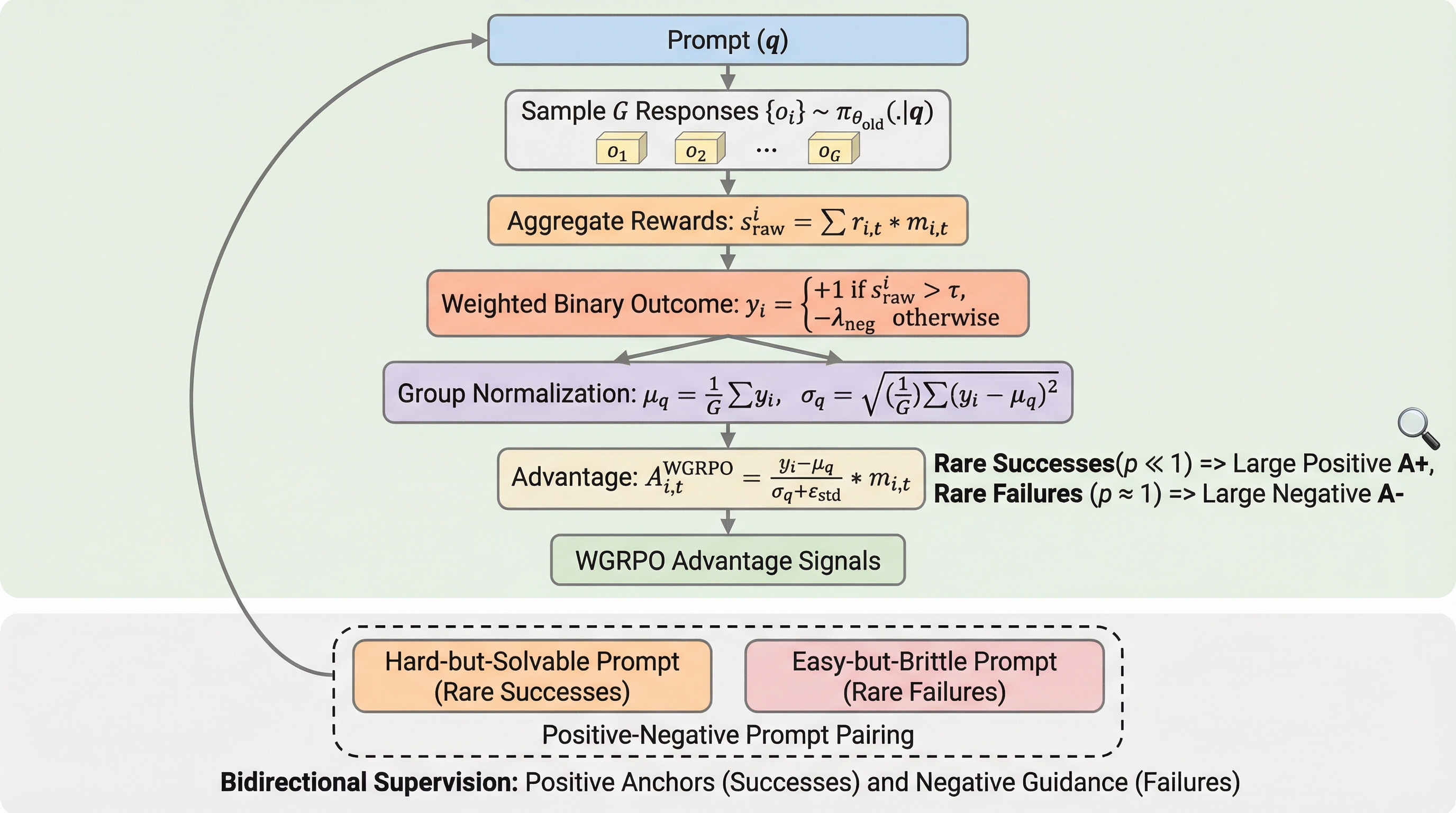
検証可能な報酬を用いた強化学習(RLVR)において、従来の分散に基づくプロンプト選択は最適化が不安定になる課題があったが、本研究は「ポジティブ・ネガティブ・ペアリング」という新しい選択原理を提案した。
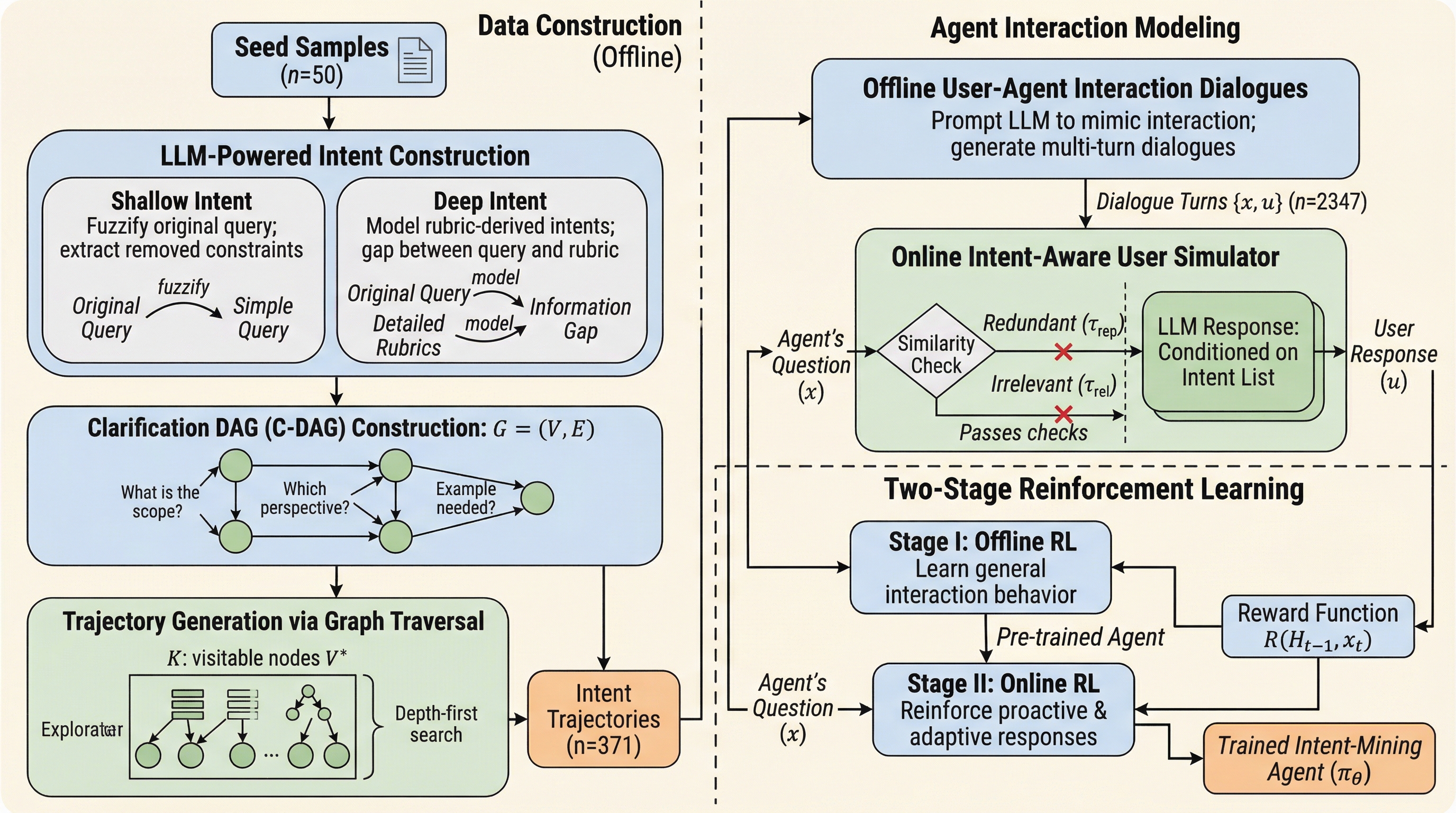
ディープリサーチ(DR)エージェントが曖昧な指示で長時間実行されることで生じる計算資源の浪費とユーザーの不満足という「自律性と対話のジレンマ」を解決するため、実行前に潜在的な意図を能動的に確認するフレームワーク「IntentRL」が提案されました。
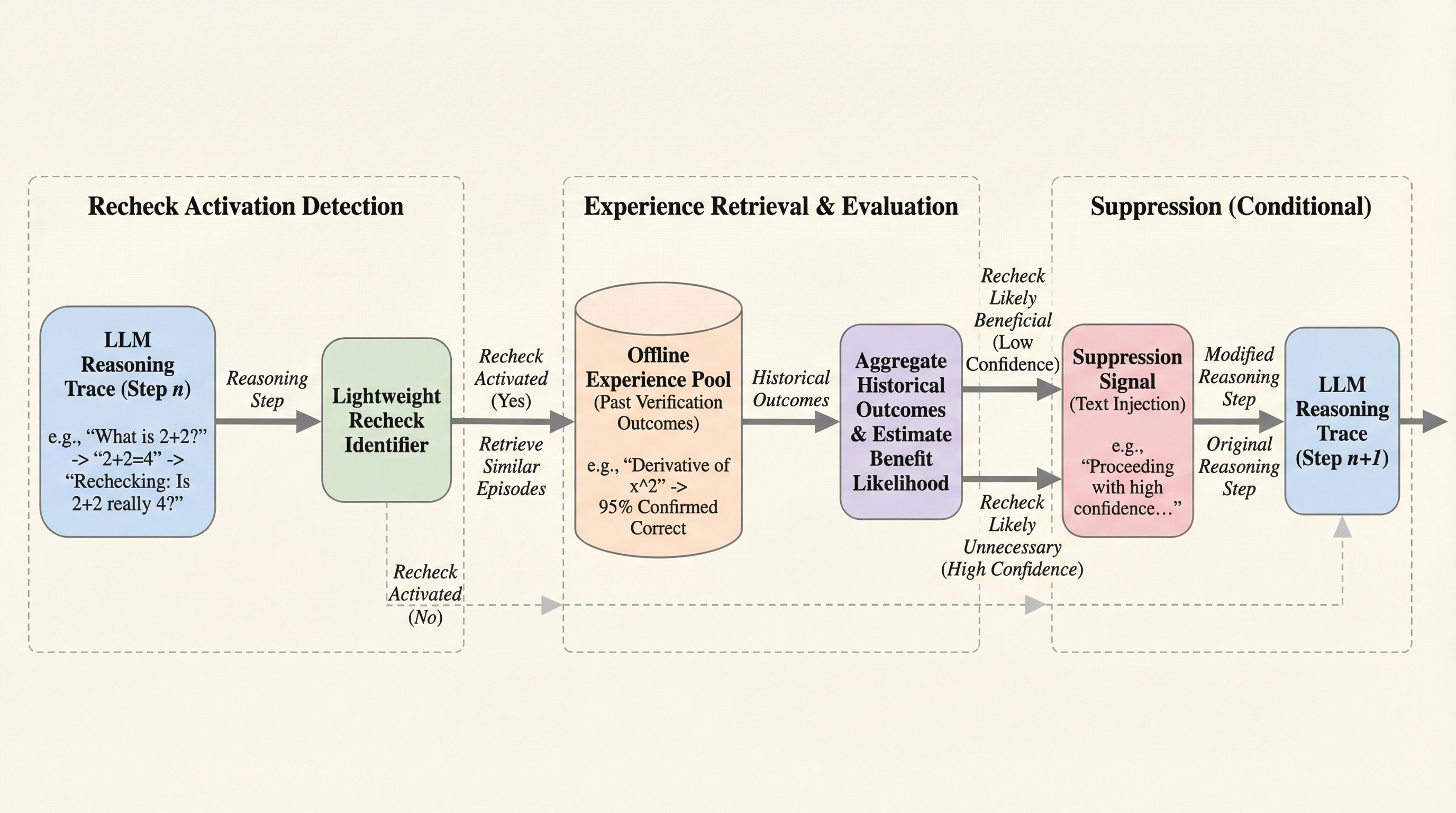
大規模推論モデル(LRM)の思考過程において、反省ステップの約4割から6割が中間結果の再確認(再チェック)であり、そのうち85%から95%という圧倒的多数が誤りを修正しない冗長なものであることが判明しました。
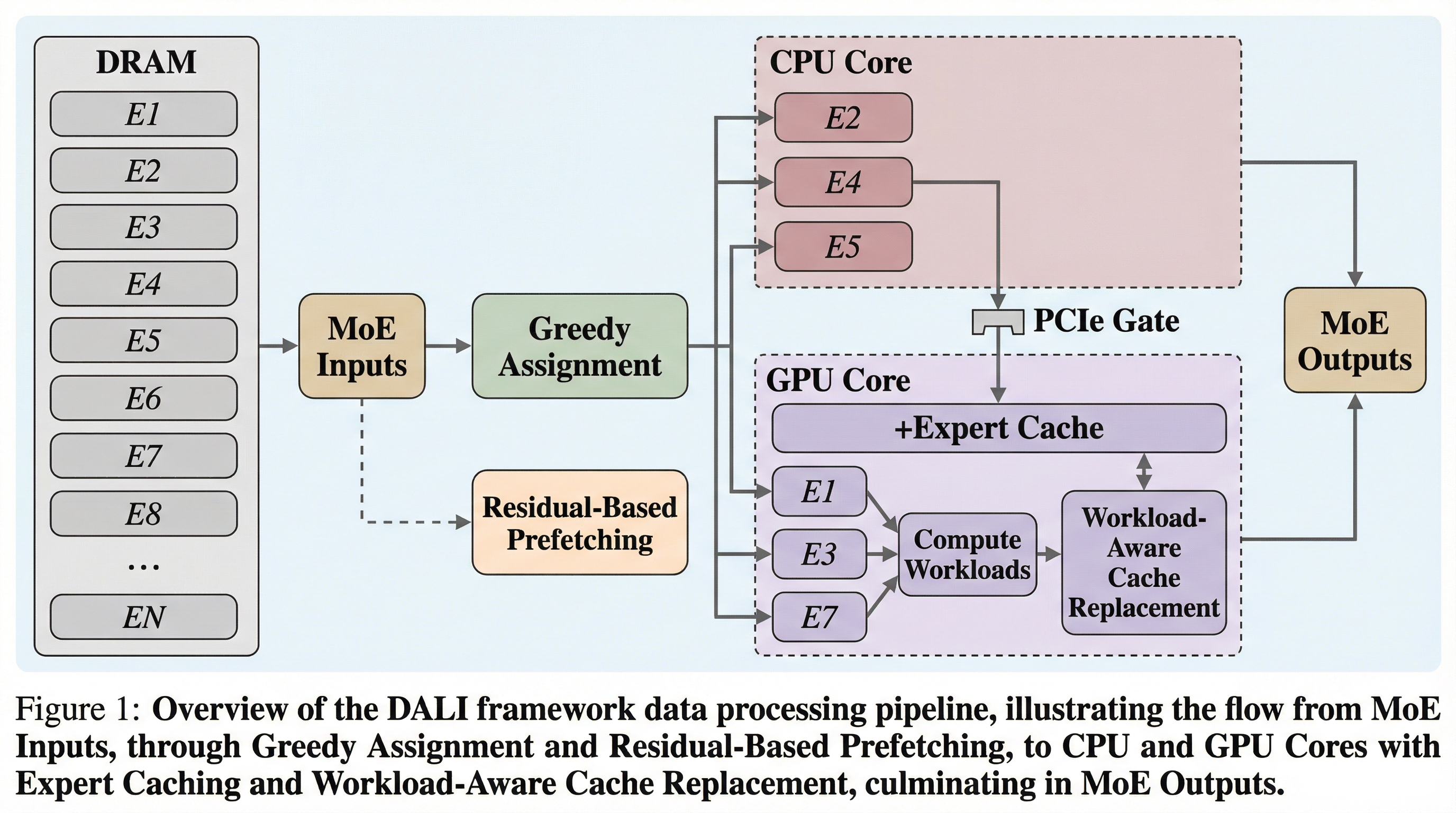
混合専門家(MoE)モデルの巨大なパラメータをローカルPCの限られたリソースで扱うため、CPUとGPUの計算資源を動的に最適化して併用する新しいオフローディングフレームワーク「DALI」が提案されました。
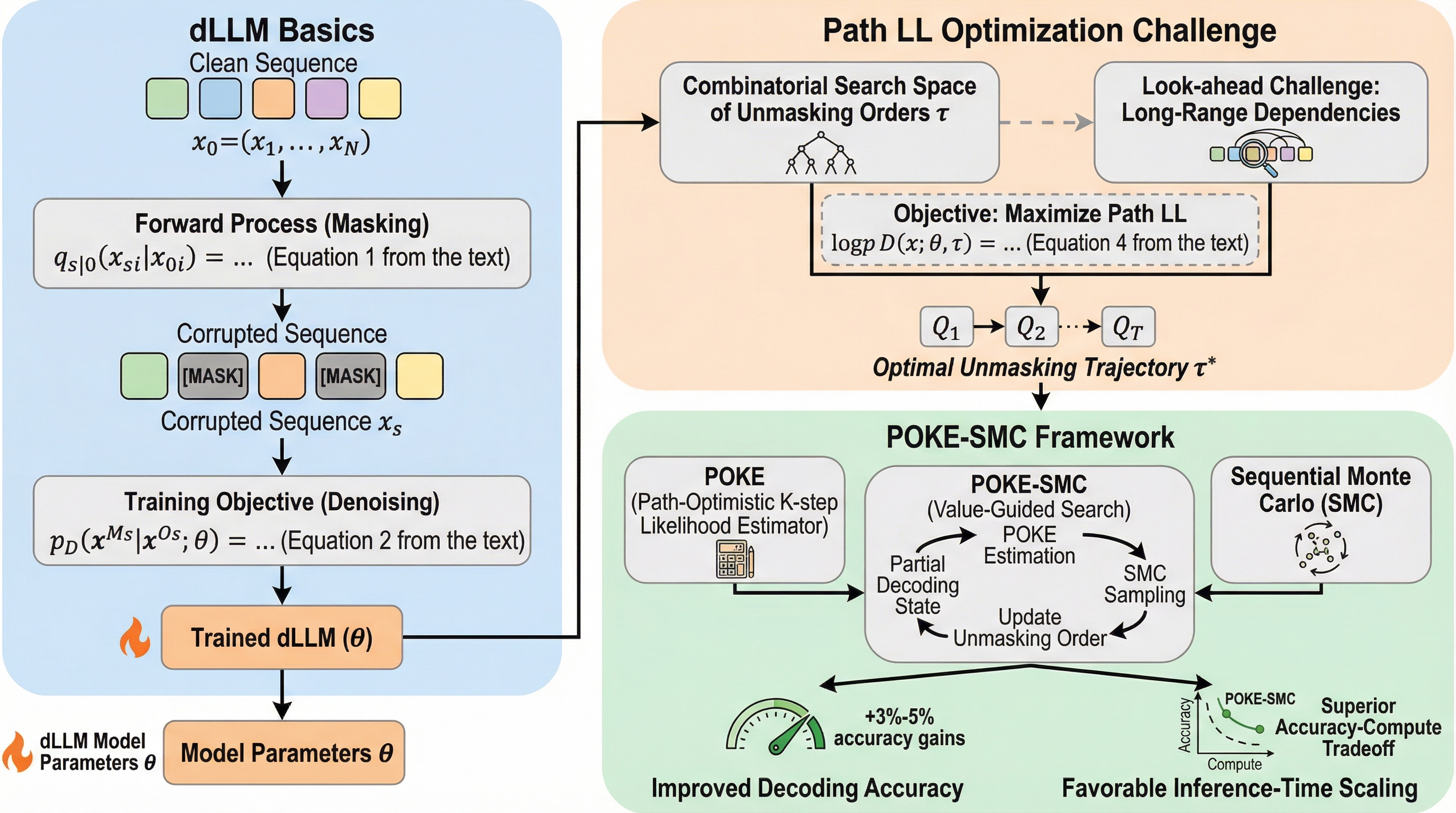
拡散大規模言語モデル(dLLM)において、生成の品質と極めて強く相関する評価指標として、アンマスク(マスク解除)の順序に依存した結合対数尤度「Path Log-Likelihood(Path LL)」を定義し、これが従来の指標よりもタスクの正解率を正確に反映することを明らかにした。