長期ホライゾンのオフライン・ゴール条件付き強化学習のためのゴールの連鎖階層的方策
従来のオフライン階層的強化学習は、高レベルと低レベルのネットワークが分離されているため、複雑なタスクで最終ゴールを見失いやすく、単一の中間ゴールしか生成できないという構造的な限界を抱えていました。
TL;DR(結論)
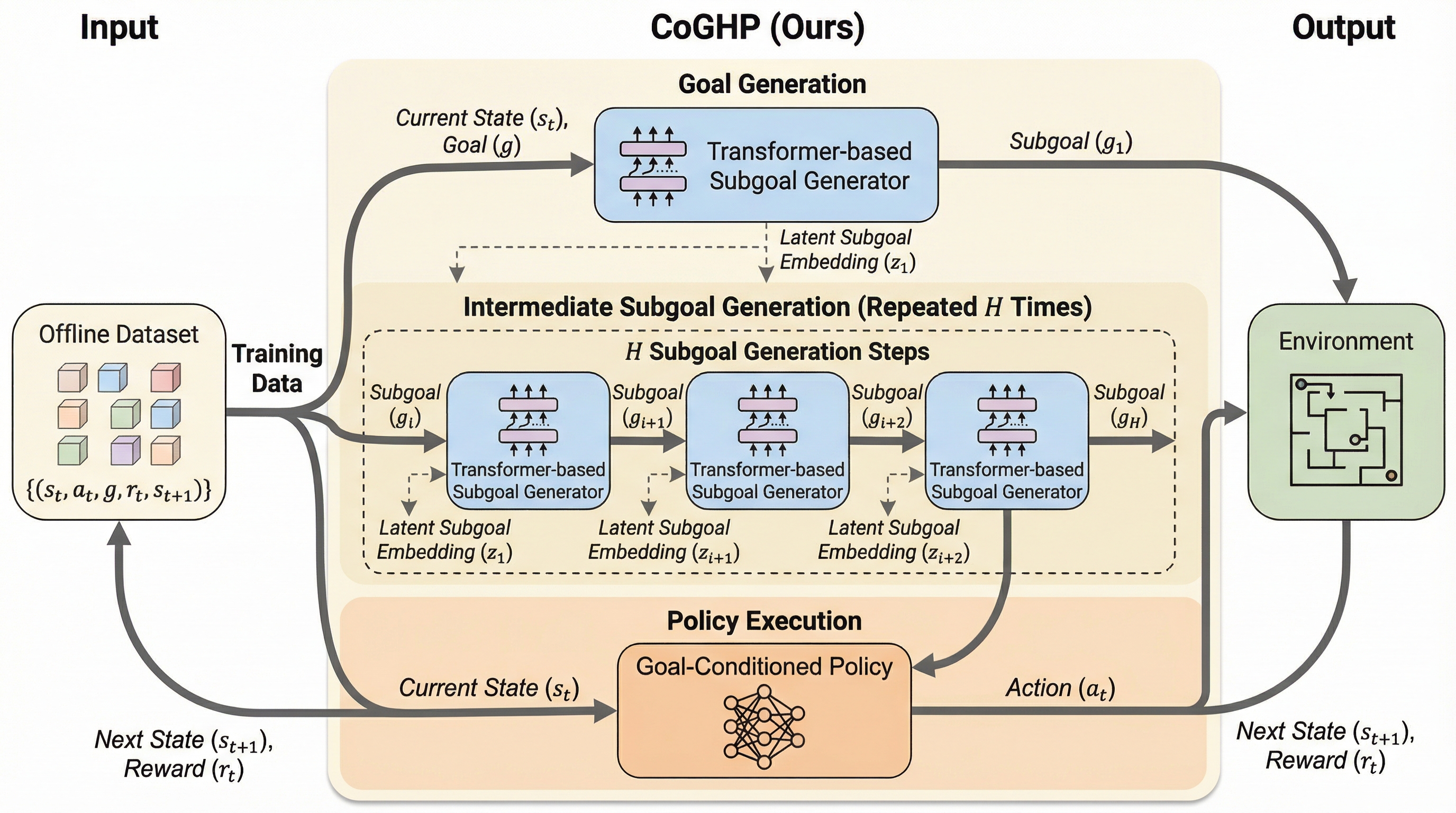
従来のオフライン階層的強化学習は、高レベルと低レベルのネットワークが分離されているため、複雑なタスクで最終ゴールを見失いやすく、単一の中間ゴールしか生成できないという構造的な限界を抱えていました。 本論文が提案するChain-of-Goals Hierarchical Policy(CoGHP)は、思考の連鎖(Chain-of-Thought)の概念を導入し、単一の統一されたアーキテクチャ内で複数の中間潜在ゴールとアクションを自己回帰的に生成する新しい枠組みを構築しました。 MLP-Mixerをバックボーンに採用することで、トークン間の効率的な通信とエンドツーエンドの学習を実現し、ナビゲーションやマニピュレーションの難易度が高い長期ホライゾンタスクにおいて、既存の強力な手法を上回る性能を実証しました。
なぜこの問題か
オフラインのゴール条件付き強化学習は、事前に収集された静的なデータセットのみを用いて、指定されたゴールに到達する方策を学習することを目指す分野です。この手法は、環境との直接的な相互作用がコスト面や安全面で困難な場合に非常に有用ですが、タスクのホライゾン(期間)が長くなるにつれて、いくつかの深刻な問題が発生します。まず、ホライゾンが拡大すると、割引率の影響やベルマン誤差の累積により、最適な行動値と最適ではない行動値の差が縮小し、方策の信頼性が著しく低下します。この問題に対処するため、タスクを「高レベルのサブゴール選択」と「低レベルの制御」に分解する階層的強化学習が研究されてきましたが、従来の階層的手法には根本的な構造的制約が存在していました。 第一の制約は、既存の多くの手法が、高レベル方策と低レベル方策を別々のネットワークとして構築している点です。この分離された構造では、通常、中間的なサブゴールを一つしか生成できず、複数の段階的な意思決定を調整する必要がある複雑なタスクには不十分です。第二に、高レベル方策が誤ったサブゴールを生成した場合、低レベル方策はその誤った目標に向かって盲目的に実行を続けてしまいます。…
核心:何を提案したのか
本論文では、思考の連鎖(Chain-of-Thought)の推論パラダイムをオフラインのゴール条件付き強化学習に適合させた、新しいフレームワークである「Chain-of-Goals Hierarchical Policy(CoGHP)」を提案しています。CoGHPの核心的なアイデアは、階層的な意思決定を、単一の統一されたモデル内での「潜在サブゴールのシーケンス」と「原始的なアクション」の自己回帰的な生成問題として再定式化することにあります。このアプローチにより、従来の階層的手法のように高レベルと低レベルのネットワークを分離する必要がなくなり、すべての意思決定プロセスが一つの流れの中で完結します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related