リスク意識の注入:有用性を損なうことなく安全性のために視覚言語モデルを較正する
視覚言語モデル(VLM)は、視覚情報の統合によって本来の安全ガードレールが機能しなくなる「リスク信号の希釈」という課題を抱えており、画像や動画を悪用したマルチモーダルな脱獄攻撃に対して極めて脆弱です。
TL;DR(結論)
視覚言語モデル(VLM)は、視覚情報の統合によって本来の安全ガードレールが機能しなくなる「リスク信号の希釈」という課題を抱えており、画像や動画を悪用したマルチモーダルな脱獄攻撃に対して極めて脆弱です。 本論文が提案する「Risk Awareness Injection(RAI)」は、追加学習を一切必要としない軽量なフレームワークであり、高リスクな視覚トークンを特定して安全信号を注入することで、モデルのリスク認識能力を効果的に回復させます。 実験の結果、RAIは画像および動画の両ドメインにおいて、モデル本来の推論性能や視覚理解能力を維持したまま、攻撃成功率を劇的に低下させることに成功し、安全性と実用性の高度な両立を証明しました。
なぜこの問題か
GPT-4VやLLaVA、Flamingoといった視覚言語モデル(VLM)の急速な発展は、視覚的な知覚と言語的な推論を統合することで、これまでにない高度なクロスモーダルな学習を可能にしました。しかし、これらのモデルは複雑な視覚シーンを理解する強力な能力を持つ一方で、悪意のあるユーザーが視覚入力を通じてテキストベースの安全対策を回避する「マルチモーダル脱獄攻撃」に対して、非常に脆弱であることが明らかになっています。既存の防御策の多くは、安全性のための微調整(セーフティ・ファインチューニング)に依存していますが、これには膨大な計算コストがかかるだけでなく、モデルが本来持っていた汎用的な能力を失う「破滅的忘却」のリスクが常に伴います。また、プロンプトベースの防御やデコーディング時の制約といった手法も提案されていますが、これらは単純な攻撃には有効なものの、画像内に巧妙に隠された悪意のある意図などの複雑な攻撃に対しては不十分な場合が多いのが現状です。…
核心:何を提案したのか
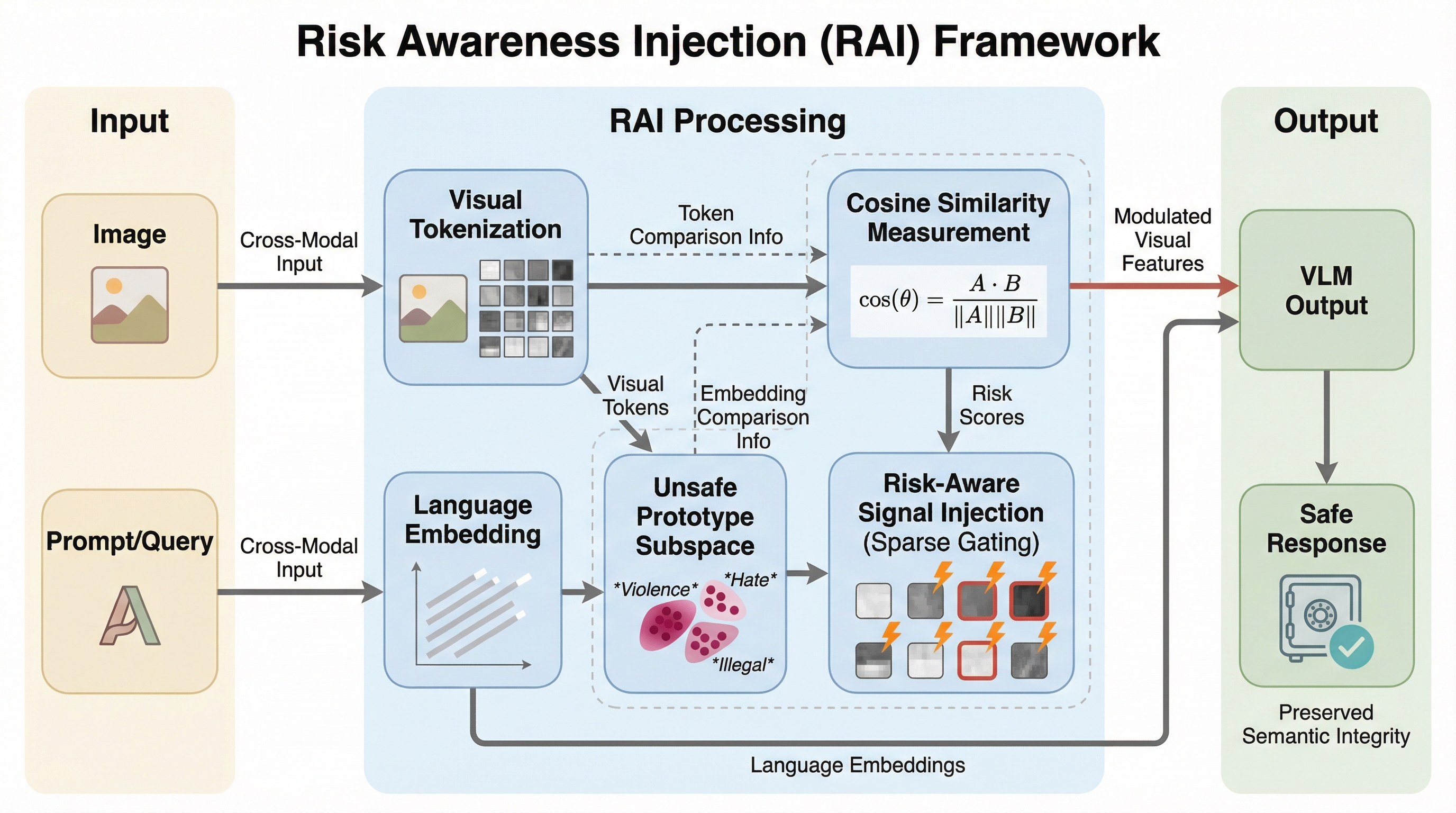
本論文では、モデルの重みを更新する学習を一切必要とせず、推論時にのみ動作する軽量な安全校正フレームワーク「Risk Awareness Injection(RAI)」を提案しています。この手法の核心は、視覚入力に含まれる安全上の重要情報が画像全体に均一に分布しているのではなく、特定の少数のトークンに局在しているという鋭い観察に基づいています。RAIは、これらの高リスクな視覚トークンを選択的に特定し、そこに安全意識を補強する信号を注入することで、モデルが本来持っているLLM譲りのリスク認識能力を効果的に回復させます。RAIの最大の特徴は、トレーニングが不要である点と、トークンレベルでのきめ細かな調整を行う点にあります。 具体的には、モデル自身が持つ言語埋め込み空間から「不安全プロトタイプ部分空間(Unsafe Prototype Subspace)」を構築し、これを利用して各視覚トークンのリスク度を測定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related