分散を超えて:希少事象の増幅と双方向ペアリングによるプロンプト効率的なRLVR
検証可能な報酬を用いた強化学習(RLVR)において、従来の分散に基づくプロンプト選択は最適化が不安定になる課題があったが、本研究は「ポジティブ・ネガティブ・ペアリング」という新しい選択原理を提案した。
TL;DR(結論)
検証可能な報酬を用いた強化学習(RLVR)において、従来の分散に基づくプロンプト選択は最適化が不安定になる課題があったが、本研究は「ポジティブ・ネガティブ・ペアリング」という新しい選択原理を提案した。これは、稀に成功する難しい問題と稀に失敗する易しい問題を組み合わせ、Weighted GRPO(WGRPO)によってそれら稀な事象から強力な学習信号を抽出する仕組みであり、わずか2つのプロンプトで大規模な学習に匹敵する性能を実現する。Qwen2.5-Math-7Bを用いた実験では、AIME 2025のPass@8が16.8から22.2へ、AMC23のPass@64が94.0から97.0へと向上し、1209個のプロンプトを用いた大規模なRLVRと同等以上の結果を達成した。
なぜこの問題か
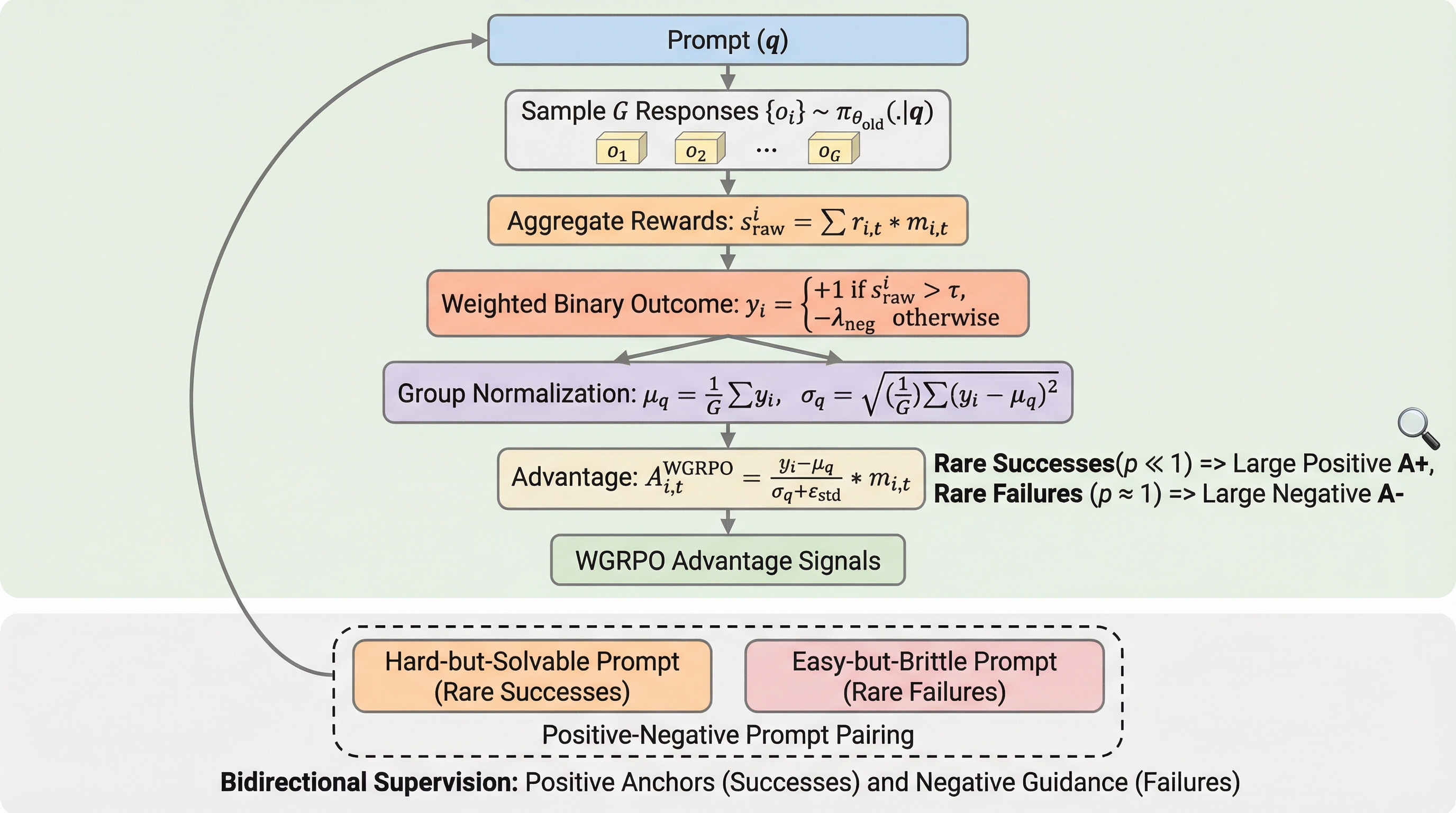
大規模言語モデル(LLM)の数学的推論能力を向上させる手法として、検証可能な報酬を用いた強化学習(RLVR)が注目を集めている。数学のような決定論的なタスクでは、人間の主観的な判断ではなく、自動検証器による客観的な正誤判定を報酬として利用できるため、報酬モデルのハッキングを防ぎつつ効率的な学習が可能になる。しかし、極端に少ないデータ環境において、どのようなプロンプトを学習に用いるべきかという選択基準については、これまで十分に解明されていなかった。先行研究では、学習精度の履歴における分散が高いプロンプトを選択するヒューリスティックが用いられてきたが、この手法はサンプリングのノイズに敏感であり、最適化の方向が不安定になるという欠点がある。 また、分散に基づく選択では、モデルが何をすべきかという肯定的な信号と、何をすべきではないかという否定的な信号をバランスよく提供できる保証がない。特にデータが少ない場合、更新の方向性が特定のサンプルに偏りやすく、他のタスクへの転移能力が弱まる傾向がある。…
核心:何を提案したのか
本研究の核心は、メカニズムレベルの視点からプロンプト選択を再定義し、わずか2つのプロンプトで効果的な学習を実現する「ポジティブ・ネガティブ・ペアリング」を提案した点にある。この手法は、学習のミニバッチが「信頼できる肯定的なアンカー」と「稀な失敗から得られる明示的な否定信号」の両方を提供すべきであるという原則に基づいている。具体的には、成功率が低いが解決可能な難しいプロンプト($q^+$)と、成功率は高いが完璧ではない易しいプロンプト($q^-$)をペアにして使用する。これにより、モデルに対して「何をすべきか」と「何をすべきではないか」という双方向の指導信号を同時に与えることが可能になる。 この双方向の信号を効果的に学習に反映させるため、新しい最適化手法である「Weighted GRPO(WGRPO)」が導入された。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related