拡散LLMのための先読みパス尤度最適化
拡散大規模言語モデル(dLLM)において、生成の品質と極めて強く相関する評価指標として、アンマスク(マスク解除)の順序に依存した結合対数尤度「Path Log-Likelihood(Path LL)」を定義し、これが従来の指標よりもタスクの正解率を正確に反映することを明らかにした。
TL;DR(結論)
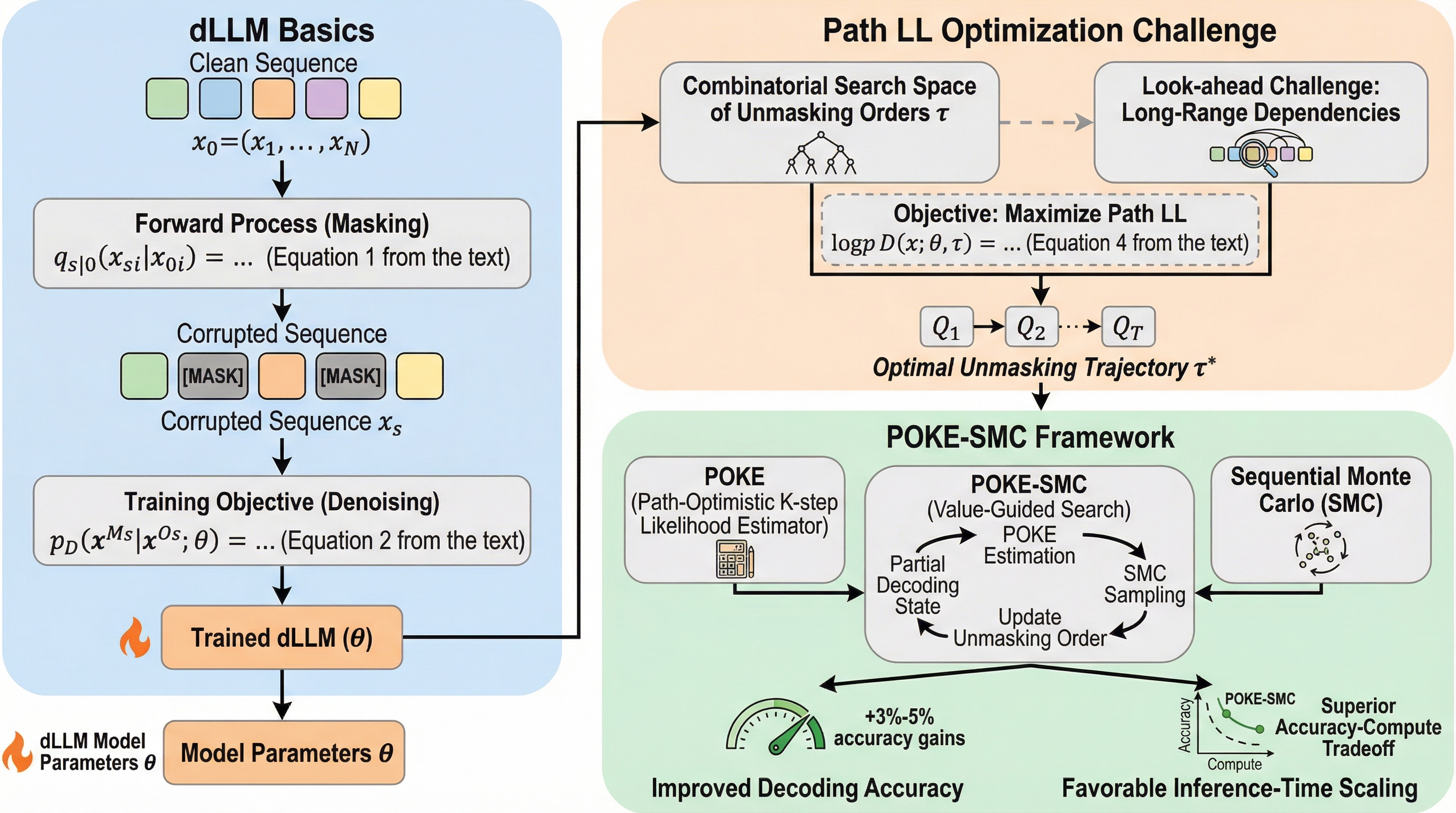
拡散大規模言語モデル(dLLM)において、生成の品質と極めて強く相関する評価指標として、アンマスク(マスク解除)の順序に依存した結合対数尤度「Path Log-Likelihood(Path LL)」を定義し、これが従来の指標よりもタスクの正解率を正確に反映することを明らかにした。 部分的なデコード状態から将来のPath LLの期待値を予測する効率的な価値推定器「POKE」を開発し、並列デコード時に発生する独立性バイアス(トークン間の依存関係の無視)を、周辺エントロピーを用いた理論的境界によって「楽観的」に補正することで、高精度な先読み評価を実現した。 この推定器をSequential Monte Carlo(SMC)探索フレームワークに統合した「POKE-SMC」を提案し、LLaDAモデルを用いた数学・コード生成・計画などの6つの推論タスクにおいて、従来の推論時スケーリング手法を上回る平均2%〜3%の精度向上を達成し、計算効率と精度のトレードオフを大幅に改善した。
なぜこの問題か
拡散大規模言語モデル(dLLM)は、テキスト生成を離散的なデノイジング(ノイズ除去)プロセスとして捉えることで、従来の自己回帰型(AR)モデルが抱えていた「左から右へ」という厳格な生成順序の制約を打破した。これにより、任意の順序での生成や、複数のトークンを同時に確定させる並列デコードが可能になり、生成の柔軟性とスループットが飛躍的に向上した。しかし、dLLMの推論性能は「どのトークンをどのタイミングでアンマスクするか」というデコード順序に極めて敏感であり、この順序の選択が最終的な生成物の品質や論理的な一貫性を大きく左右することが明らかになっている。 既存のアンマスク戦略の多くは、モデルが予測する確信度(Confidence)やエントロピー(Entropy)、あるいは上位候補間の差(Margin)といった局所的な指標に基づく静的なヒューリスティックルールに依存している。しかし、これらのルールは特定のタスクでは有効であっても、汎用性に欠けるという深刻な課題がある。例えば、確信度に基づく選択は数学やコード生成では良好な結果を示すが、数独(Sudoku)のような複雑な構造的推論を必要とするタスクでは性能が著しく低下する。…
核心:何を提案したのか
本研究の核心は、dLLMの生成品質を評価するための新たな客観的指標として「Path Log-Likelihood(Path LL)」を導入し、それを推論時に動的に最適化する新しいフレームワークを提案した点にある。Path LLは、特定のアンマスク順序(軌跡)に従って生成されたシーケンスの結合対数尤度として定義される。実験を通じて、このPath LLがELBOやパス・エントロピーといった既存の指標よりも、下流タスクの正解率と極めて強い相関を持つことが証明された。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related