悪循環から好循環へ:教師なしビデオ物体中心学習のための相乗的表現学習
ビデオ物体中心学習において、エンコーダが生成する鋭いがノイズの多いアテンションマップと、デコーダが生成する空間的に一貫しているが境界がぼやけた再構成マップが、互いの学習を阻害し合う「悪循環」を特定しました。
TL;DR(結論)
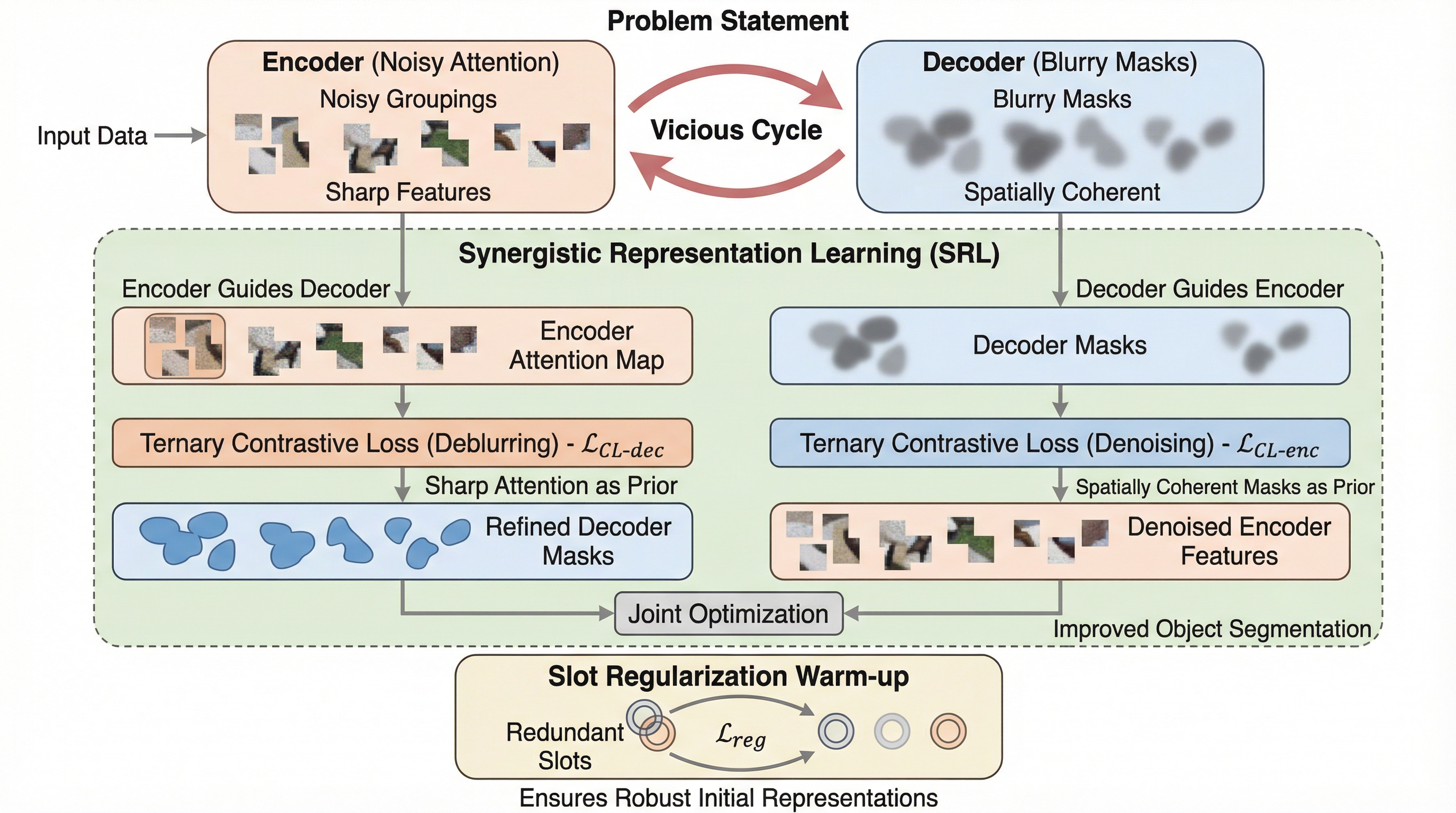
ビデオ物体中心学習において、エンコーダが生成する鋭いがノイズの多いアテンションマップと、デコーダが生成する空間的に一貫しているが境界がぼやけた再構成マップが、互いの学習を阻害し合う「悪循環」を特定しました。 この問題を解決するため、エンコーダの鋭さを利用してデコーダの境界を鮮明にし、同時にデコーダの一貫性を利用してエンコーダのノイズを除去する、相互洗練プロセスを備えた相乗的表現学習(SRL)という新しいフレームワークを提案しました。 スロット正則化によるウォームアップと、3段階の階層を持つコントラスティブ学習を導入することで、ビデオ物体中心学習のベンチマークにおいて従来手法を上回る最先端の性能を達成し、より鮮明で正確な物体セグメンテーションを実現することに成功しました。
なぜこの問題か
物体中心学習の目的は、明示的な教師ラベルを使用せずに、複雑なビデオシーンを個別の物体表現へと分解することにあります。特にスロットベースのモデルは、ビデオ内のピクセルを意味のある物体レベルのスロットにグループ化する手法として大きな期待を集めていますが、従来の再構成ベースの学習には根本的な矛盾が潜んでいます。学習プロセスでは、スロットアテンションによって生成されるアテンションマップと、再構成デコーダによって生成される出力マップという、特性の異なる2つの空間マップが使用されます。アテンションマップはピクセル間の特徴の類似性に基づいているため、本質的に鋭く粒度が高いという利点がありますが、一方で高周波ノイズの影響を受けやすく、空間的に離れたパッチを誤って同じ物体としてグループ化してしまうことがあります。 一方で、デコーダの出力マップは、平均二乗誤差(MSE)損失の平滑化特性やオートエンコーダの構造上の制約により、ぼやけて空間的に滑らかになる傾向があります。この特性の乖離は、学習を根本的に制約する「悪循環」を引き起こします。まず、エンコーダは強力な特徴量を利用しているものの、ノイズを含んだ出力を生成します。…
核心:何を提案したのか
本研究では、この悪循環を打破し、エンコーダとデコーダが互いに洗練し合う「好循環」を確立するためのフレームワークとして、相乗的表現学習(SRL)を提案しました。SRLの核心は、エンコーダとデコーダの表現上の乖離を、互いの弱点を補完するための武器として活用することにあります。具体的には、目的別に設計された2つのコントラスティブ学習目的を導入し、両者の空間マップを相乗的に洗練させます。第一に、デコーダのぼやけを解消するために、エンコーダが持つ鋭いアテンションマップをガイドとして利用します。第二に、エンコーダのノイズを除去するために、デコーダが持つ空間的に一貫したマスクをトレーニング信号として利用します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related