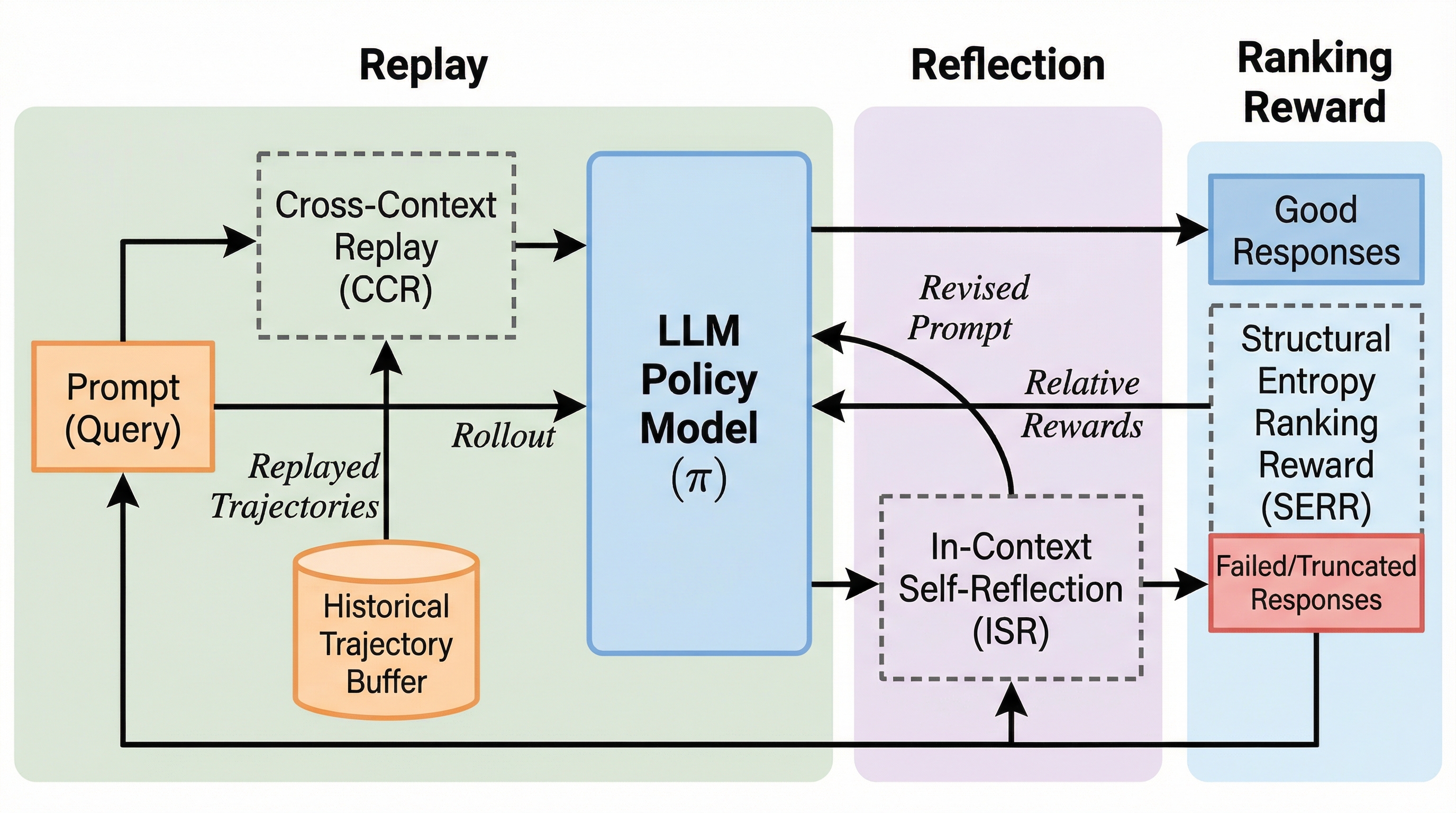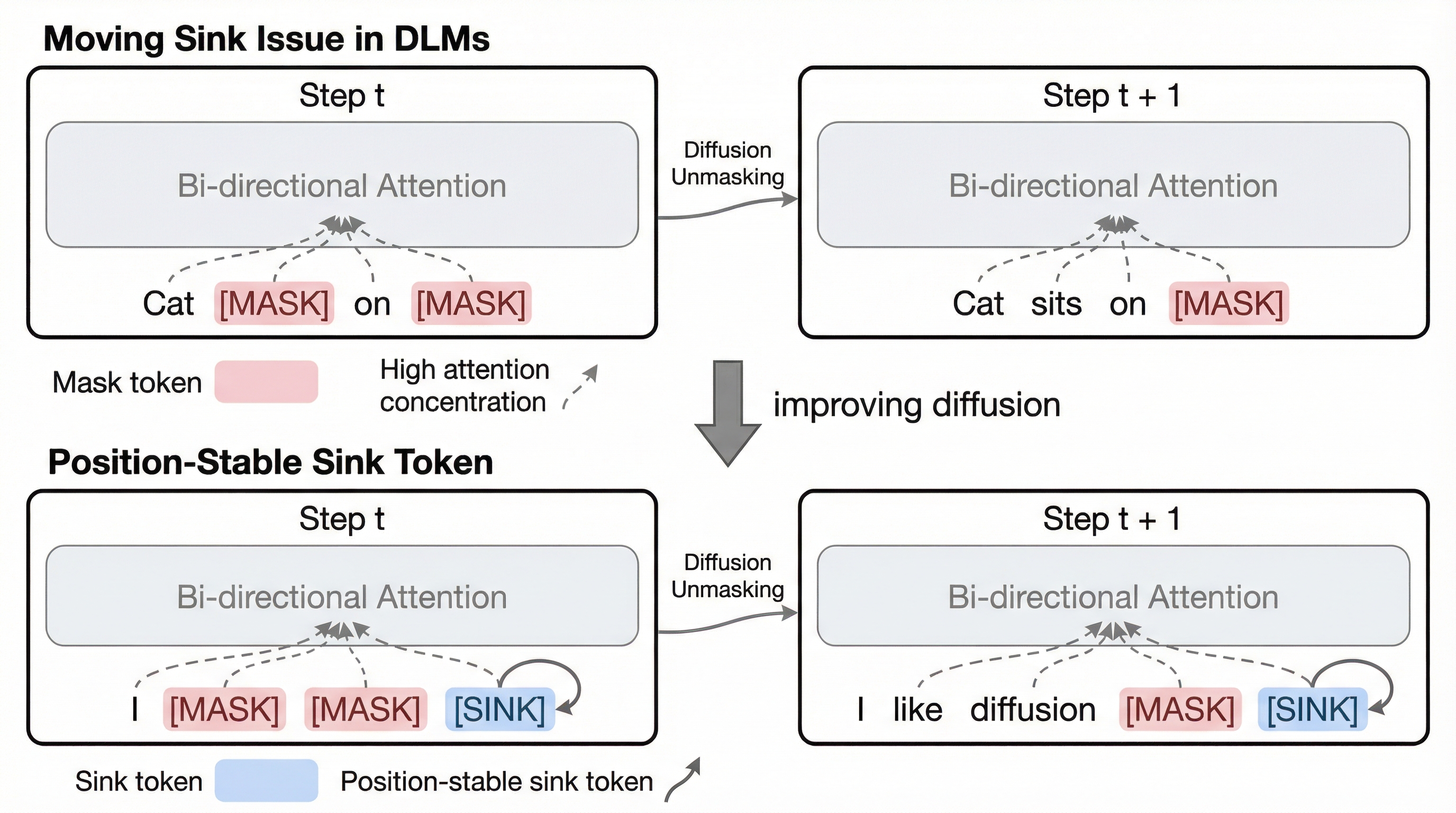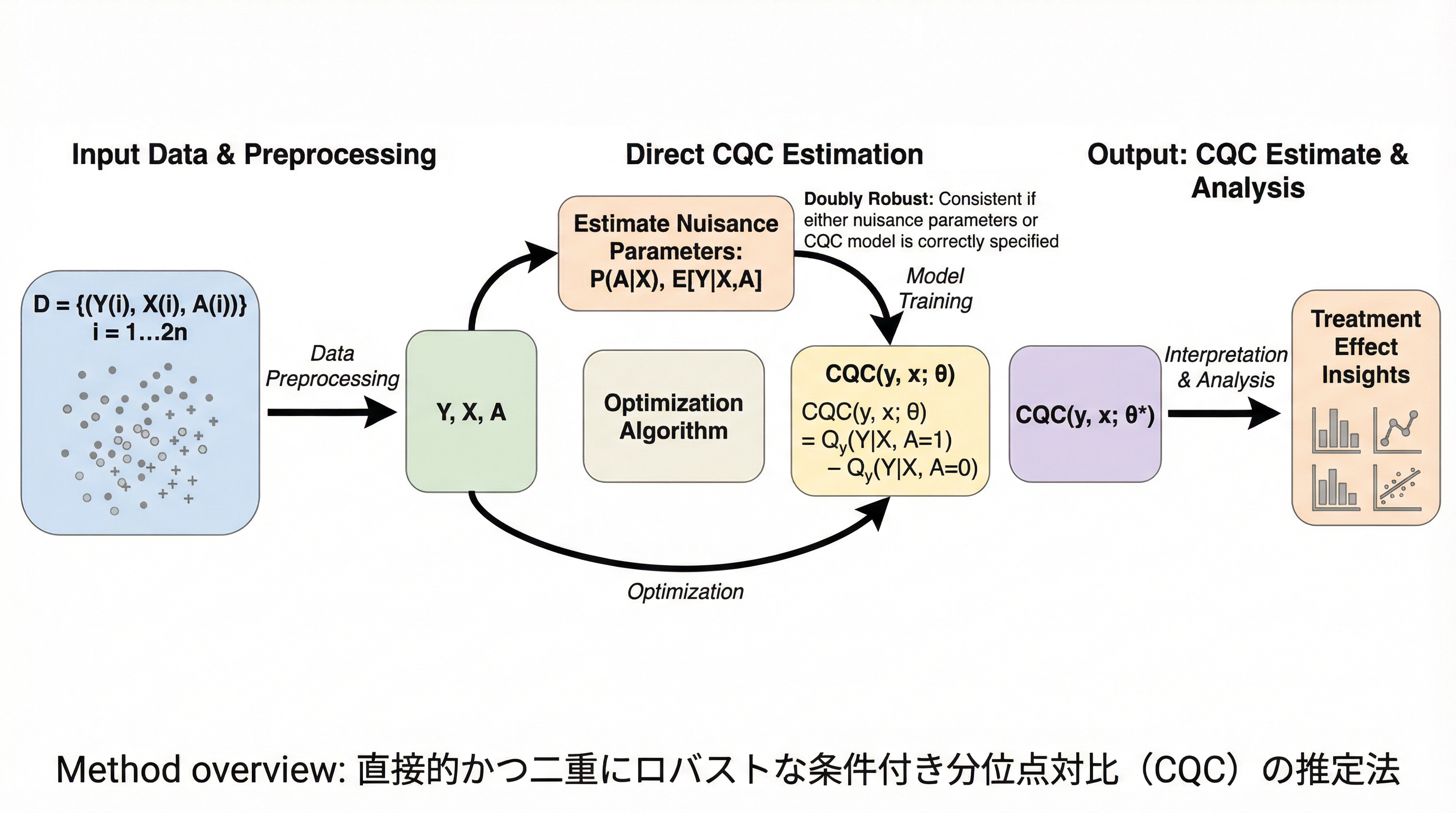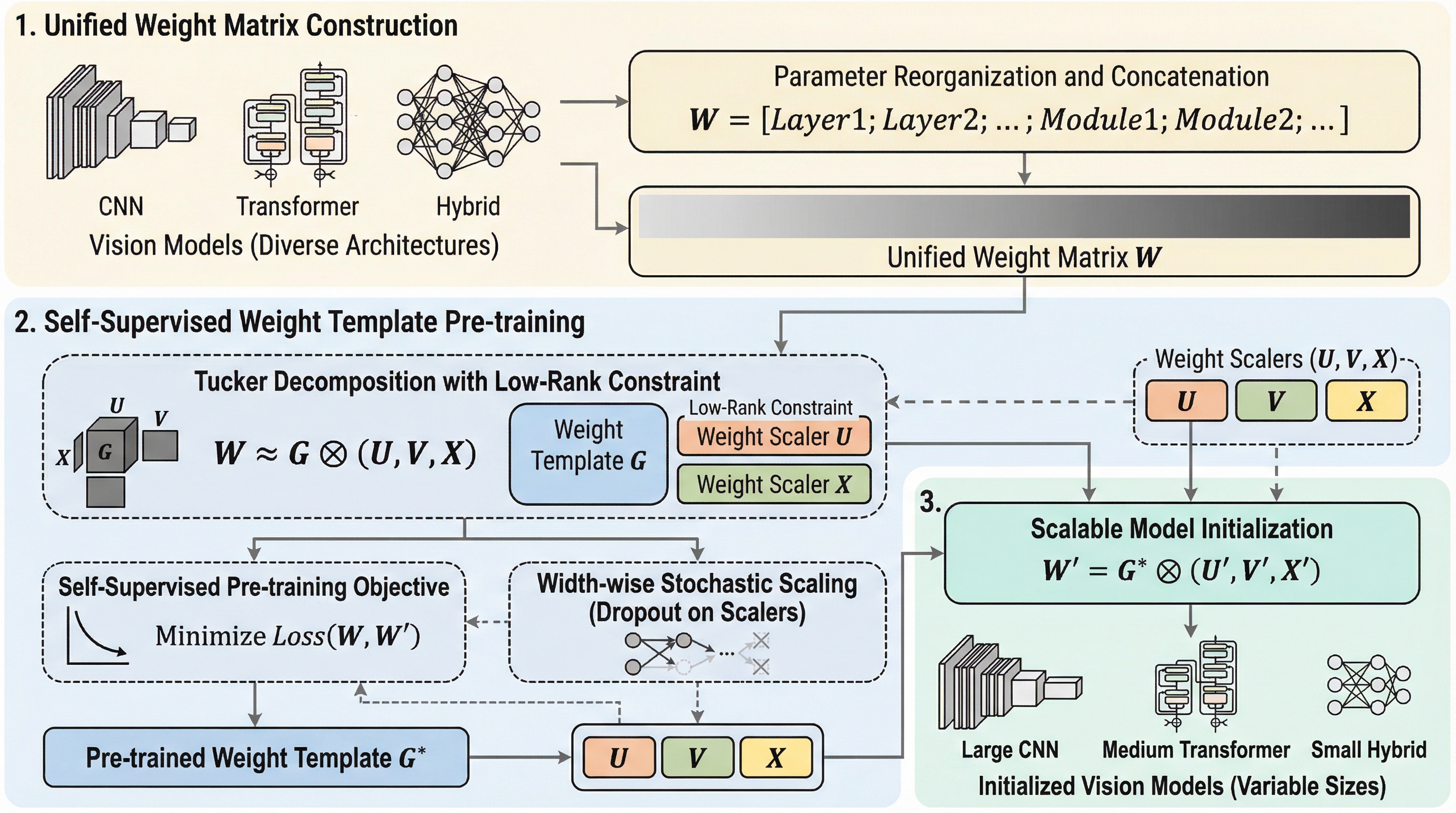
対照表現学習の幾何学的力学:アライメント・ポテンシャル、エントロピー的分散、およびクロスモーダル・ダイバージェンス
本研究は、InfoNCEの幾何学的メカニズムを解明するため、固定された多様体上での表現測度の進化を記述する測度論的フレームワークを導入した。大バッチ極限において、確率的な目的関数が決定論的なエネルギー地形へと収束することを数学的に証明し、学習プロセスを不透明なパラメータ更新から、表現空間における本質的な母集団の幾何学的な動態へと変換することに成功した。 ユニモーダル設定においては、目的関数が厳密に凸なエネルギー地形を形成し、一意のギブス平衡へと収束する性質を持つことを明らかにした。ここでは、従来「一様性」として独立して扱われていた概念が、アライメントによって形成された盆地内でのエントロピー的な分散、すなわち「タイブレーカー」として機能していることを解明し、アライメントと一様性の主従関係を理論的に再定義した。 マルチモーダル設定(CLIPスタイル)では、目的関数に持続的な負の対称ダイバージェンス項が含まれており、これが異なるモーダリティ間の表現分布を押し離す「反発障壁」として機能することを突き止めた。これにより、広く知られるモーダリティ・ギャップは、初期化の不備やサンプリングの偏りによるものではなく、目的関数の構造そのものが課す幾何学的な必然性として生じる平衡状態であることを証明した。