分解と形式化:再帰的に検証可能な自然言語推論
自然言語推論において、大規模言語モデルと定理証明器を統合する際の課題であった、長文や複雑な構文に起因する形式化エラーと、それによる推論チェーン全体の破綻を解決するため、推論過程を「含意ツリー」として構造化し、各ステップを最小単位の命題に分解して再帰的に検証・修正するフレームワーク「LLM-TP Tree」を提案しました。 この手法では、文を最小単位に切り分ける「原子的分解」と、イベントベースの論理形式で意味的な役割結合を厳密に管理する「$\theta$置換」を導入することで、定理証明器との互換性と元の文章への忠実性を両立させ、失敗した箇所のみを特定して局所的に修正する効率的なプロセスを実現しています。 5つの最新の大規模言語モデルを用いた評価の結果、従来手法と比較して検証成功率を最大48.9%向上させ、修正のための反復回数や実行時間を大幅に削減しながら、高い推論精度を維持することに成功し、複雑な多段階推論を論理的に厳密な形で検証できる実用的な可能性を示しました。
TL;DR(結論)
自然言語推論において、大規模言語モデルと定理証明器を統合する際の課題であった、長文や複雑な構文に起因する形式化エラーと、それによる推論チェーン全体の破綻を解決するため、推論過程を「含意ツリー」として構造化し、各ステップを最小単位の命題に分解して再帰的に検証・修正するフレームワーク「LLM-TP Tree」を提案しました。 この手法では、文を最小単位に切り分ける「原子的分解」と、イベントベースの論理形式で意味的な役割結合を厳密に管理する「$\theta$置換」を導入することで、定理証明器との互換性と元の文章への忠実性を両立させ、失敗した箇所のみを特定して局所的に修正する効率的なプロセスを実現しています。 5つの最新の大規模言語モデルを用いた評価の結果、従来手法と比較して検証成功率を最大48.9%向上させ、修正のための反復回数や実行時間を大幅に削減しながら、高い推論精度を維持することに成功し、複雑な多段階推論を論理的に厳密な形で検証できる実用的な可能性を示しました。
なぜこの問題か
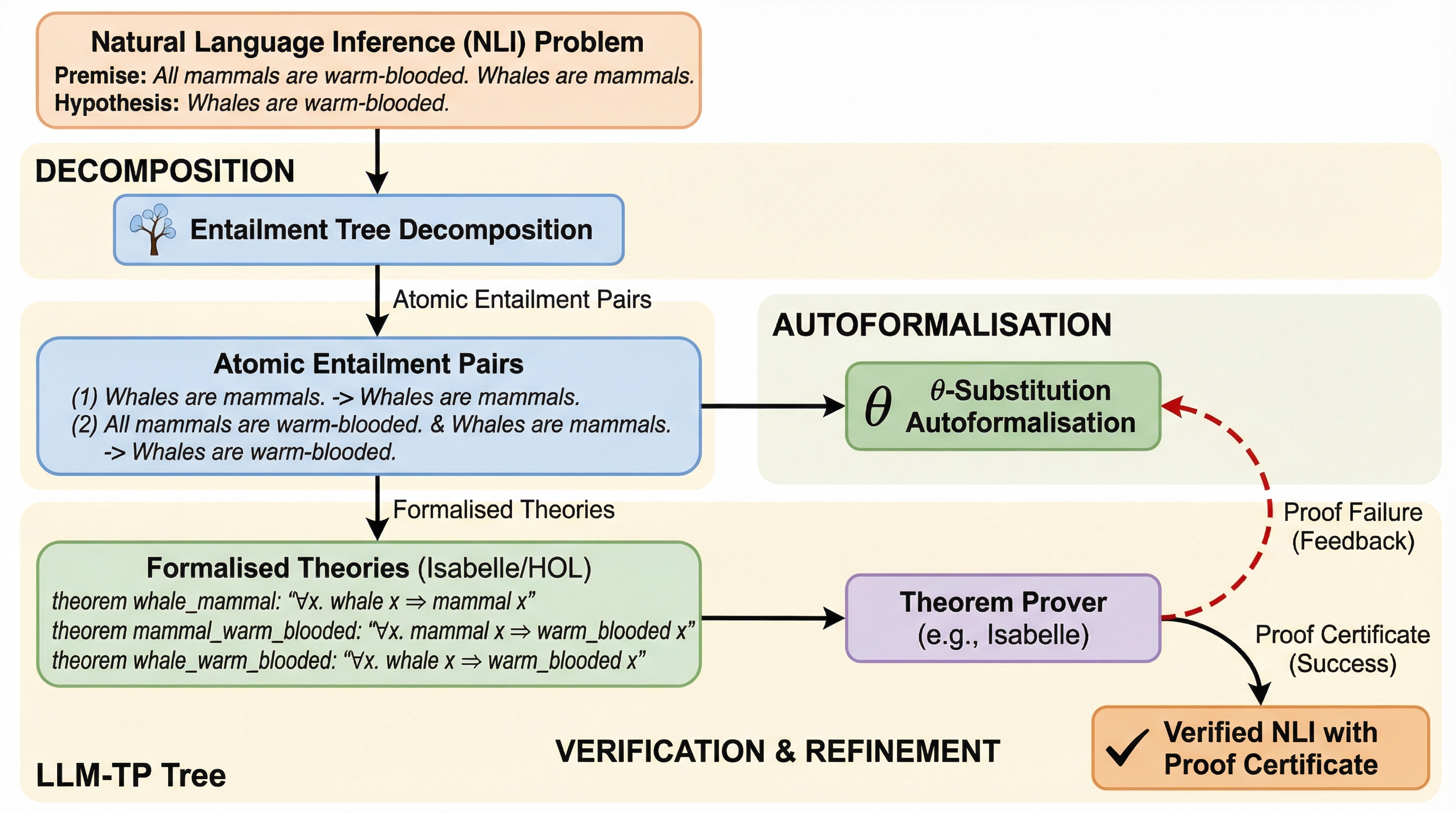
自然言語による説明は人間が論理を伝えるための基本的な手段ですが、人工知能が生成する説明は、しばしば論理的に不完全であったり、厳密さに欠けたりすることが大きな課題となっています。近年、大規模言語モデル(LLM)の生成能力と、外部の定理証明器(TP)による厳密な検証を組み合わせた「ニューロ・シンボリック・パイプライン」が注目されています。これは、自然言語を論理式に変換する「自己形式化」を通じて、推論の正しさを数学的に証明しようとする試みです。しかし、このアプローチを現実的で複雑な推論タスクに適用するには、いくつかの深刻な障壁が存在していました。 まず、入力される文章が長く、構文的に複雑である場合、自己形式化の過程でわずかなエラーが発生しやすくなります。例えば、主語と目的語の入れ替わり、否定の範囲の誤認、あるいは量子化のミスといった局所的な不一致が一つでも生じると、推論チェーン全体が無効化されてしまいます。現在の多くの手法では、証明に失敗した際に説明全体を最初から再生成するという、非常にコストが高く不安定な方法をとっています。…
核心:何を提案したのか
本研究では、従来の「一括での再生成」という非効率なアプローチを打破するために、「構造的な分解と局所的な修理」を基本理念とする新しいフレームワーク「LLM-TP Tree」を提案しています。このフレームワークの核心は、前提と結論のペアを「含意ツリー(Entailment Tree)」として構造化し、推論の各ステップを独立して、かつ再帰的に検証可能な状態にすることにあります。これにより、推論の全体像を維持しながら、個別の論理ステップを精密に精査することが可能になりました。 具体的には、まず大規模言語モデルを用いて、与えられた前提と仮説から中間結論を含む推論ツリーを構築します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related