スケーラブルなビジョンモデル初期化のための自己教師あり重みテンプレート
現代の視覚モデルの急速な大規模化に伴い、特定のサイズで事前学習されたモデルを異なる規模のアーキテクチャに適応させる際の膨大な計算コストが課題となっているが、本研究はこの問題を解決するために、Tucker分解に基づく構造的制約を用いた自己教師あり学習フレームワークであるSWEETを提案した。
TL;DR(結論)
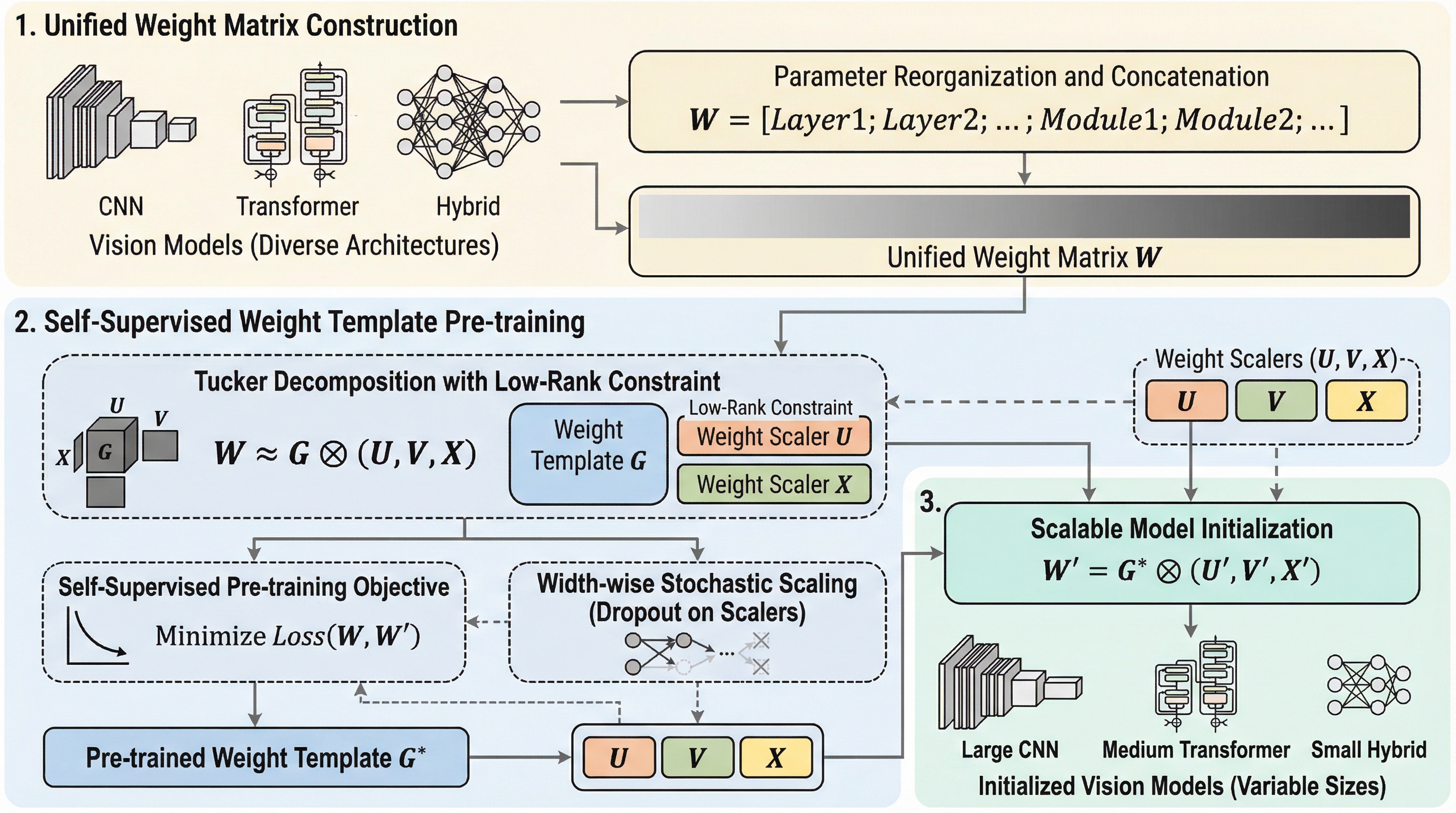
現代の視覚モデルの急速な大規模化に伴い、特定のサイズで事前学習されたモデルを異なる規模のアーキテクチャに適応させる際の膨大な計算コストが課題となっているが、本研究はこの問題を解決するために、Tucker分解に基づく構造的制約を用いた自己教師あり学習フレームワークであるSWEETを提案した。 この手法は、モデル内の全パラメータを統合した巨大な行列を、共有の「重みテンプレート」とサイズ固有の「重みスケーラー」に分解して学習することで、深さや幅が異なる多様なモデルへの柔軟な初期化を可能にし、さらに幅方向の確率的スケーリングを導入することで、任意のモデル幅に対する頑健な転送性能を実現している。 画像分類、物体検出、セマンティックセグメンテーション、画像生成の各タスクにおいて、従来の固定サイズモデルや既存の初期化手法を大幅に上回る性能を実証しており、一度の事前学習で得られたテンプレートを軽量なスケーラー適応のみで再利用できるため、計算リソースを抑えた効率的なモデル展開の新たな基準を確立した。
なぜこの問題か
近年の視覚モデルにおけるパラメータ数と複雑性の増大は、モデルをゼロから学習することを極めて非効率なものにしており、事前学習済みモデルの活用が現代の視覚学習において不可欠な基盤となっている。しかし、従来の事前学習パラダイムは、特定のデータセットにおいて固定されたサイズのモデル、例えばViT-Lなどの性能を最大化することに特化しており、特定の規模やタスクドメインに密結合しているという根本的な限界がある。実際の運用環境では、利用可能な計算リソースや下流タスクの具体的な要求に応じて、多様な規模のアーキテクチャが必要とされるが、既存の事前学習済みモデルの構成から外れる場合、再学習や知識蒸留といった多大な計算オーバーヘッドを伴うプロセスが必要になる。 一部の既存手法では、事前学習済みの重みを再利用または変換して異なる規模のモデルを初期化しようと試みているが、これらは事前学習された表現の構造的一貫性を損なう傾向がある。その結果、パラメータの不一致や特徴の分断による負の転送を招き、最終的な性能が大幅に低下するという問題が報告されている。…
核心:何を提案したのか
本研究では、多様なサイズや視覚タスクにわたってスケーラブルな初期化を可能にする、自己教師あり重みテンプレート学習フレームワークであるSWEETを提案している。SWEETの核心は、固定サイズのモデルを学習する代わりに、Tucker分解に基づく構造的制約の下で、共有される「重みテンプレート」とサイズ固有の「重みスケーラー」を学習する点にある。具体的には、異なるレイヤーやモジュールのすべての主要なパラメータを一つの統一された重み行列に統合し、これをTucker分解によって再構成することで、アテンションヘッドやフィードフォワードモジュールといった異なるコンポーネント間での…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related