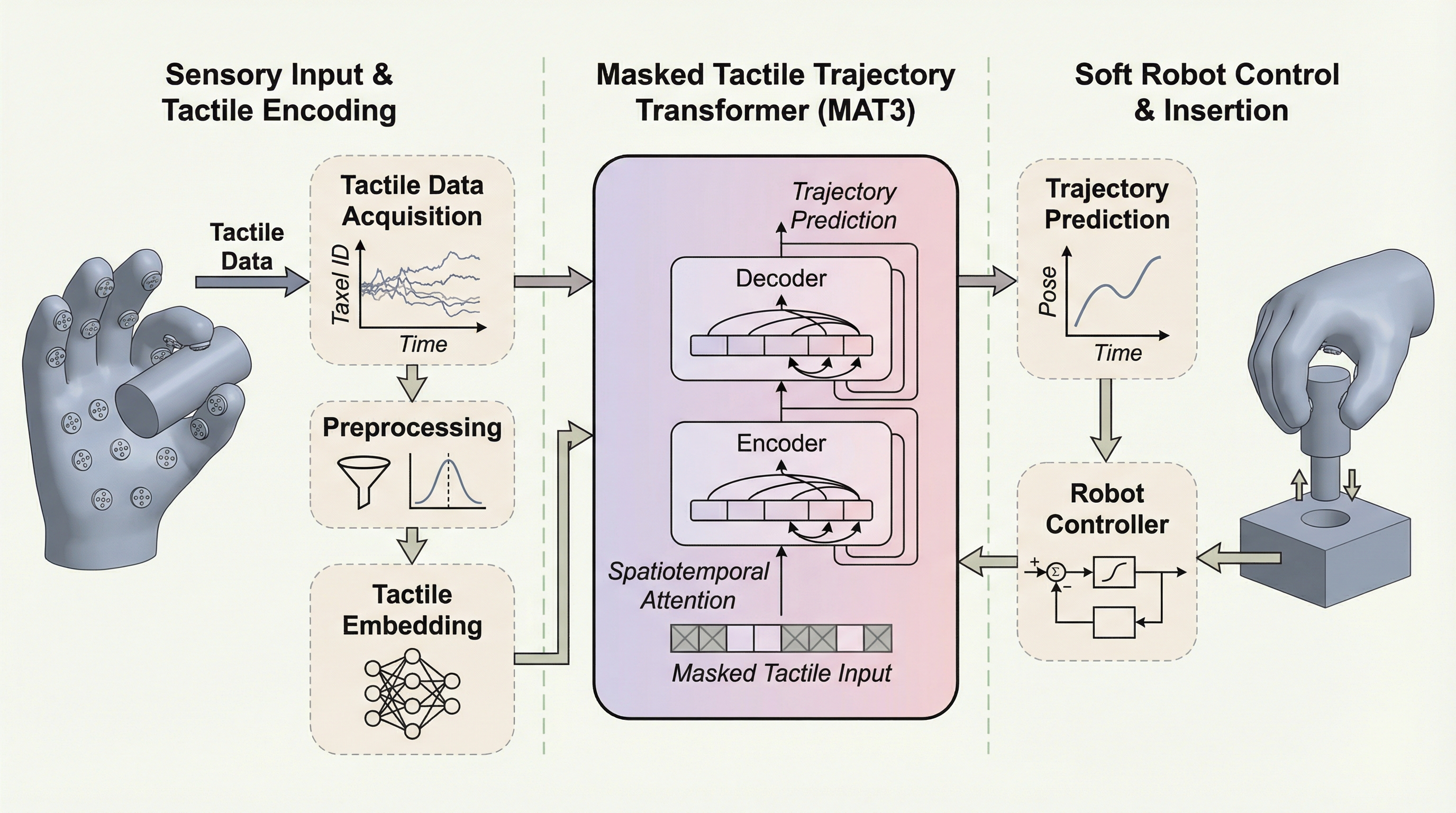
ソフトロボットを用いた触覚メモリ:マスク化エンコーディングとソフト手首による堅牢な物体挿入
物理的な柔軟性を備えたソフト手首と、過去の触覚体験をデータベース化して検索・再利用する機能を統合したロボットシステム「TaMeSo-bot」を開発し、位置の不確実性が高い環境下での堅牢なペグ挿入を実現しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
物理的な柔軟性を備えたソフト手首と、過去の触覚体験をデータベース化して検索・再利用する機能を統合したロボットシステム「TaMeSo-bot」を開発し、位置の不確実性が高い環境下での堅牢なペグ挿入を実現しました。
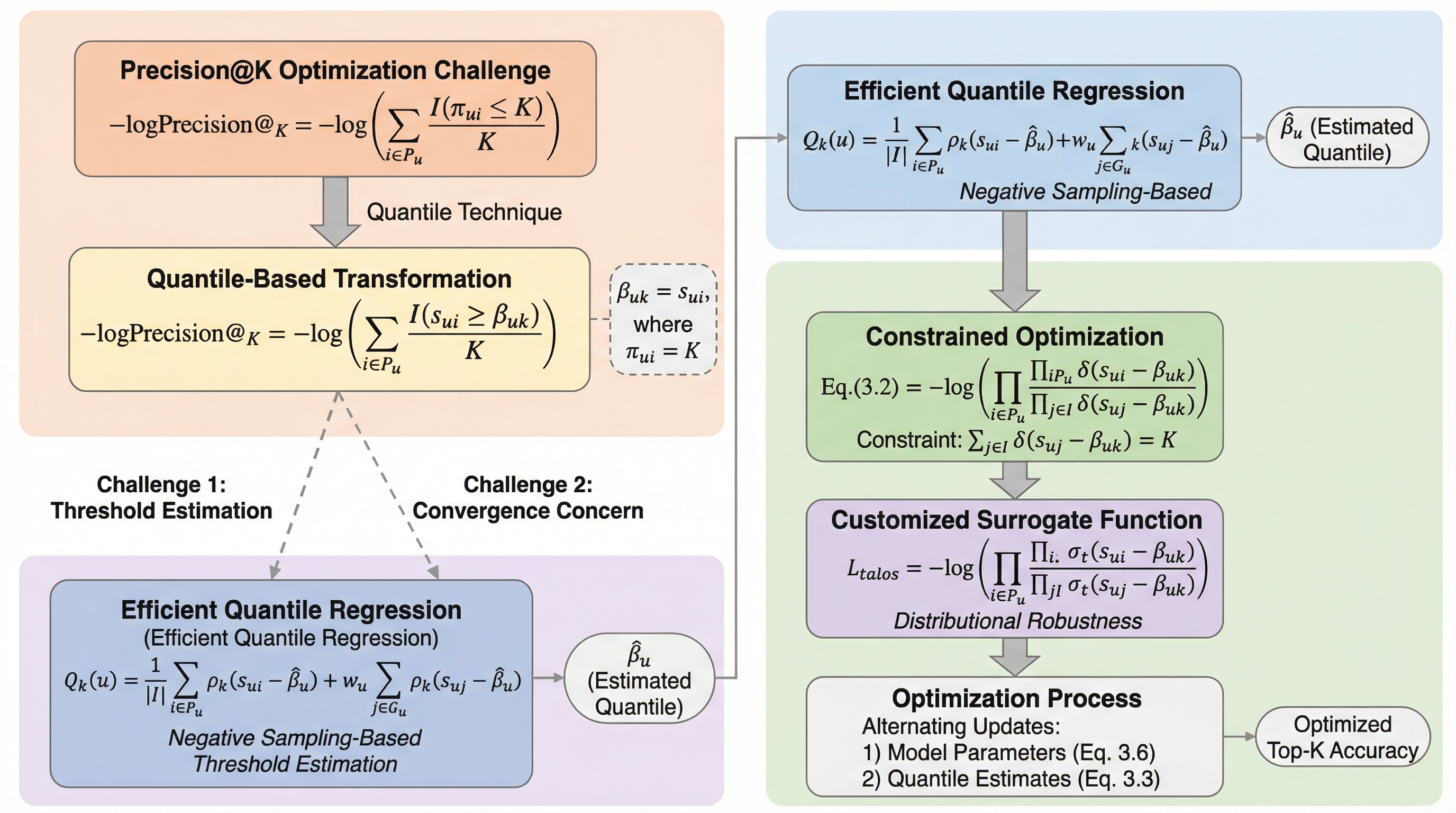
従来の推薦システムで主流だった全ランキング指標の最適化は、実際の利用シーンで重要なTop-$K$精度と必ずしも一致しないという課題がありました。本研究で提案されたTalosは、複雑な順位計算をスコアとしきい値の比較に置き換えるクォンタイル手法を導入し、Top-$K$精度を直接的かつ効率的に最適化する新しい損失関数です。
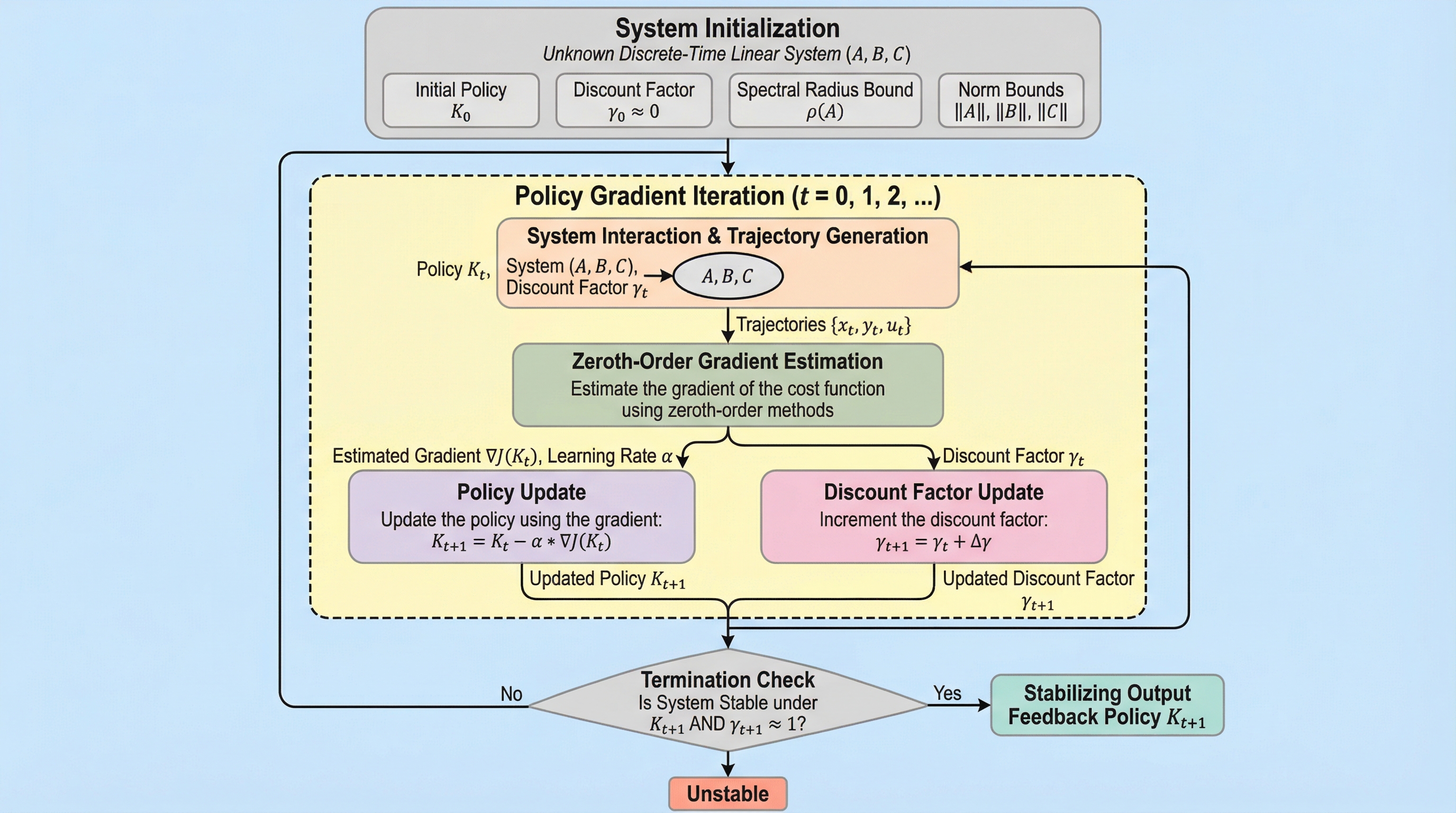
本研究は、システムモデルが未知である離散時間線形動的システムにおいて、観測可能な出力情報のみを利用してシステムを安定化させるための新しいモデルフリーな方策勾配法を提案している。従来の全状態フィードバックを前提とした手法とは異なり、出力フィードバック特有の非凸性や勾配優位性の欠如という困難に対し、割引因子を段階的に調整する「割引法」と零次最適化を組み合わせることで、開ループで不安定なシステムを確実に安定化領域へと導く。提案アルゴリズムは、システムの実行軌道データから勾配を推定する二点推定法を採用しており、非凸な最適化環境下での停留点への収束保証とともに、安定化に必要な総サンプル複雑性を理論的に明示し、数値シミュレーションによってその有効性を実証している。
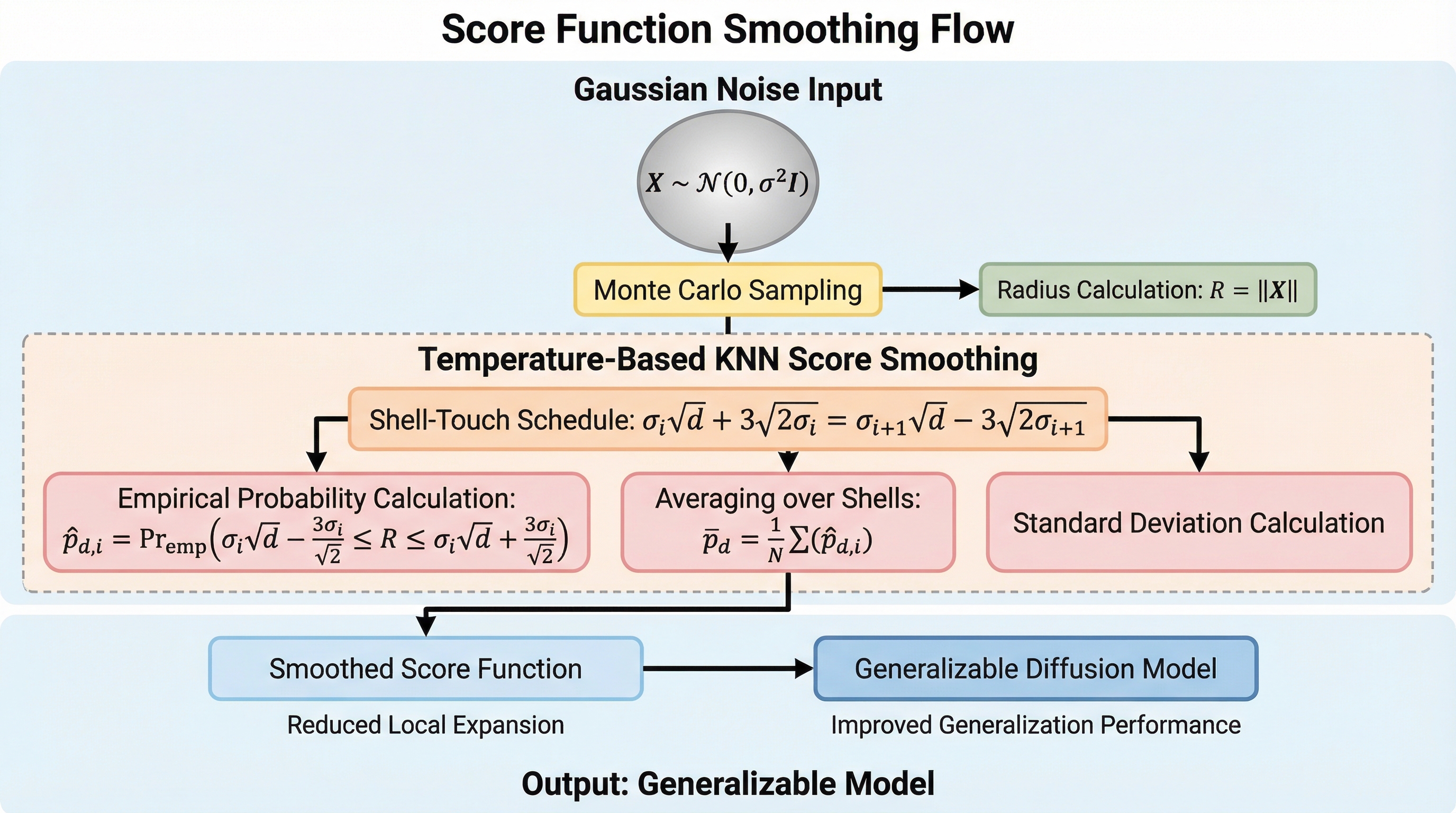
拡散モデルが訓練データをそのまま複製してしまう「記憶」現象は、理論上の経験的スコア関数が非常に鋭いソフトマックス重みを持つガウス分布の和として構成され、サンプリングが特定の訓練点へ崩壊することに起因することを解明した。
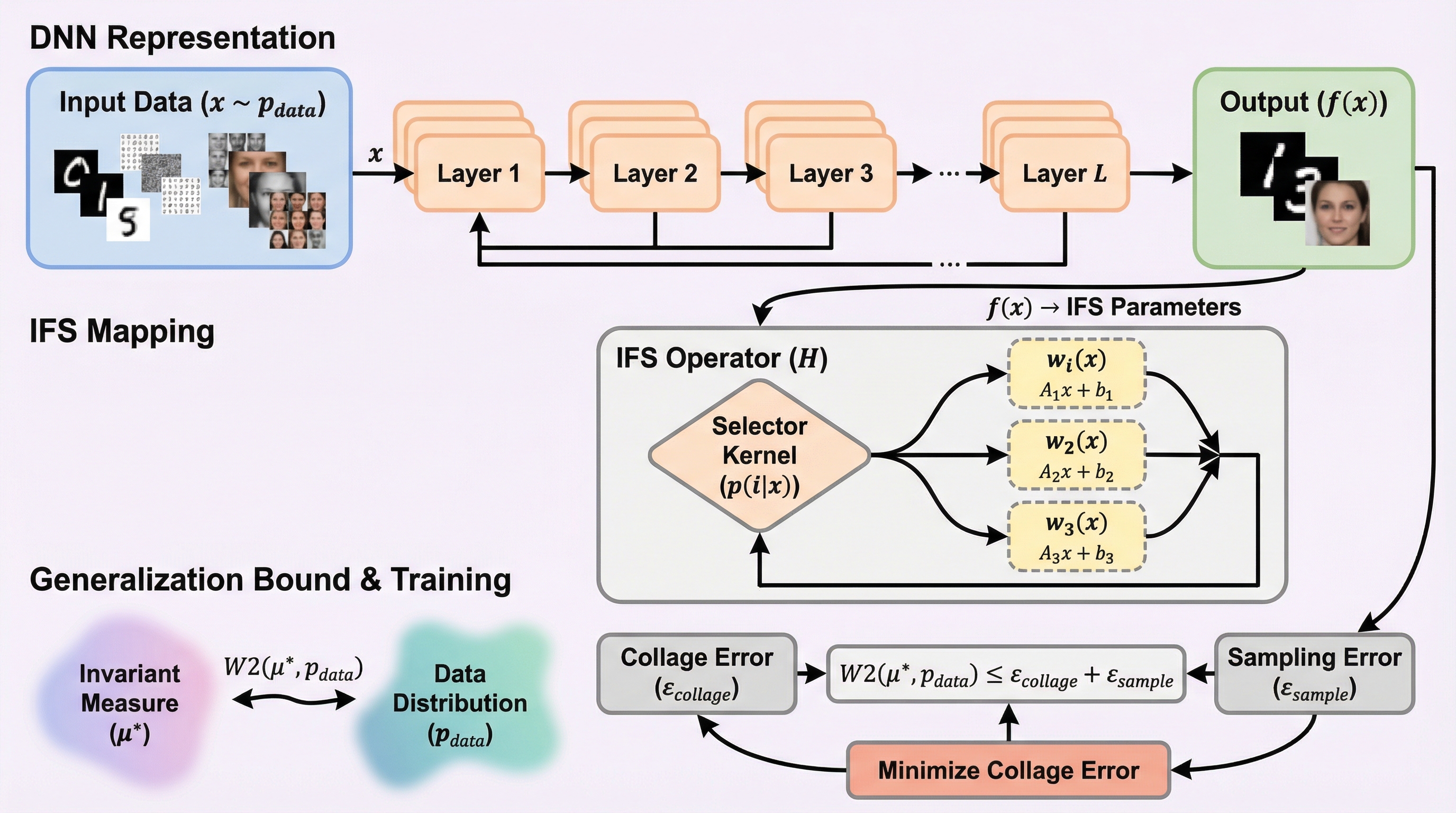
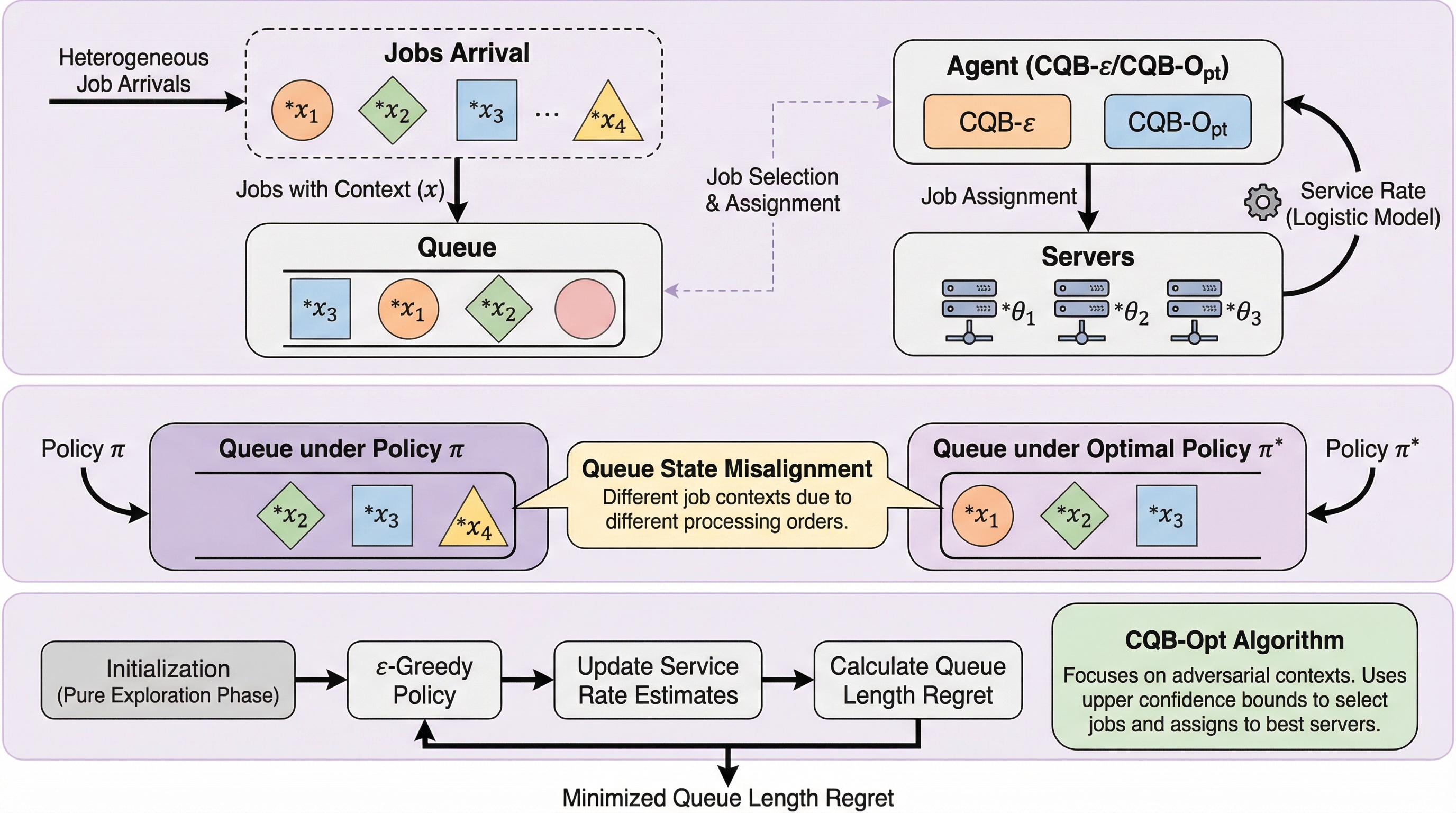
本研究は、個々のジョブが異なる特徴量(コンテキスト)を持つ環境下で、未知のサービス率を学習しながら効率的なスケジューリングを行う「コンテキスト付き待ち行列バンディット」という新しい枠組みを提案した。
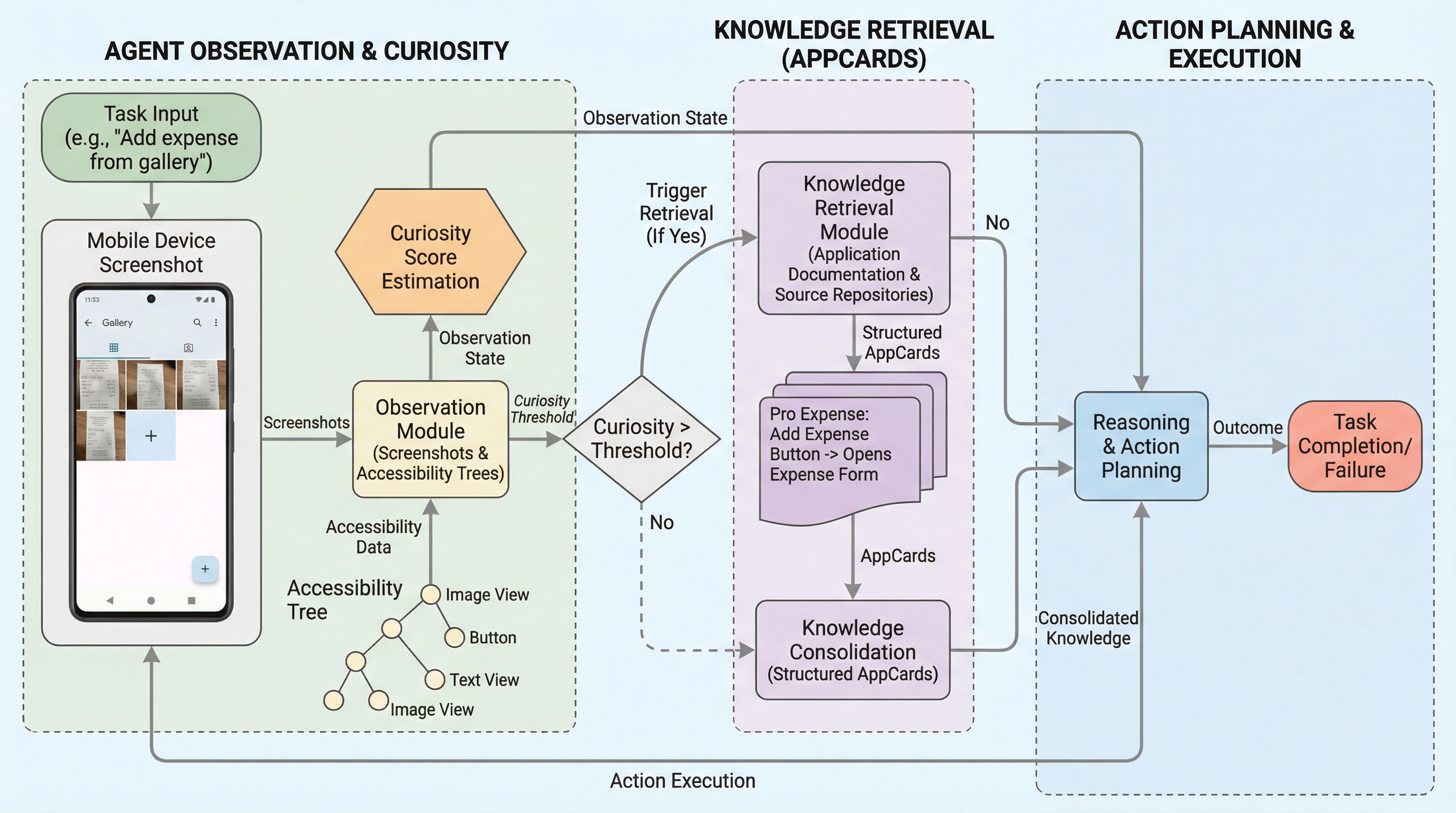
スマートフォン操作を自動化するモバイルエージェントが、未知のアプリや複雑なタスクに直面した際の知識不足を解消するため、実行中の不確実性を「好奇心スコア」として数値化し、外部知識を動的に取得するフレームワークを提案した。
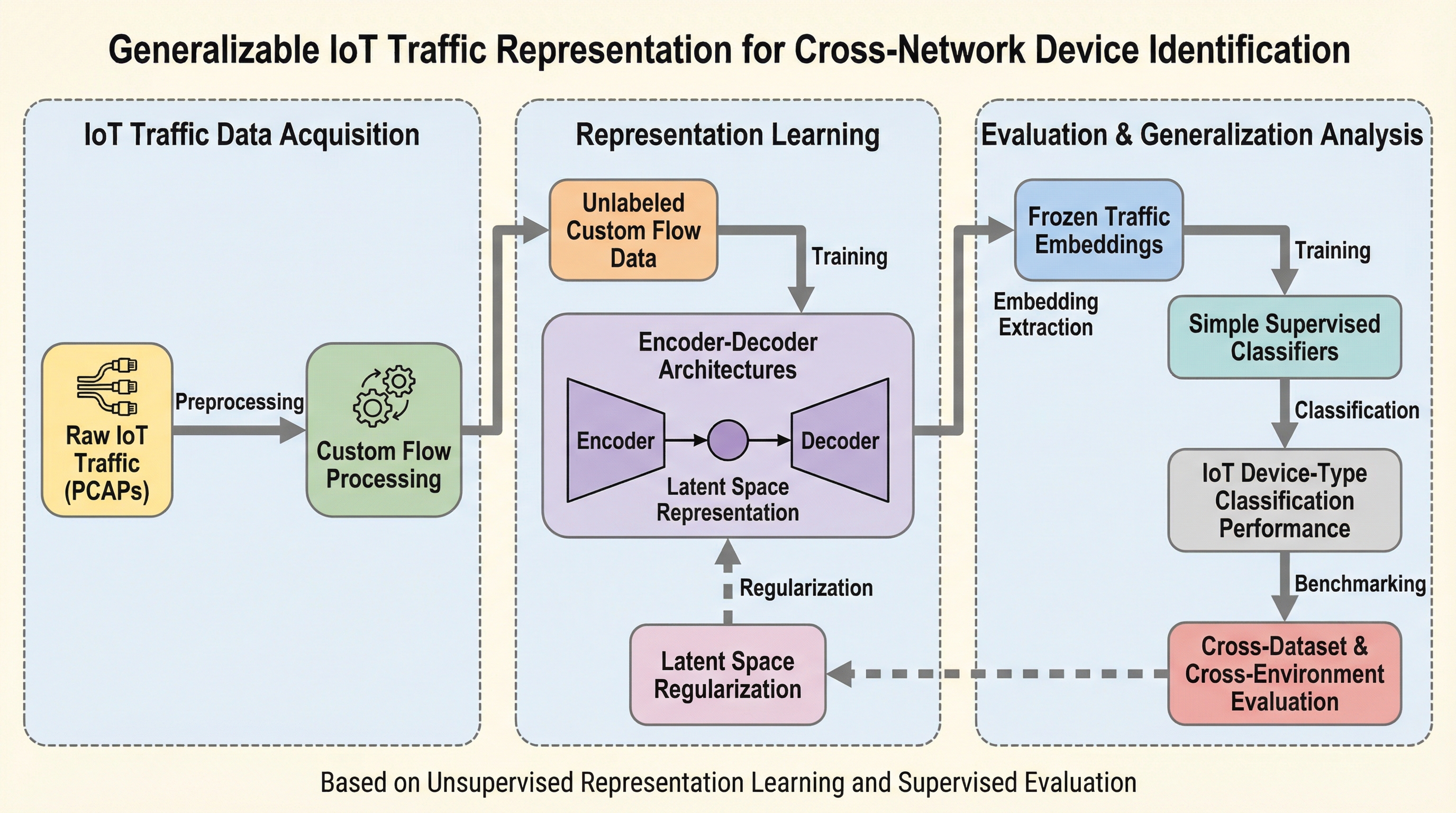
IoTデバイスの識別において、特定の環境やデータセットに依存しない汎用的なトラフィック表現を学習する手法が提案された。ラベルのない膨大なIoT通信データから、エンコーダ・デコーダ構成を用いてコンパクトな埋め込み表現を抽出し、これを固定したまま単純な分類器でデバイス種別を特定する。
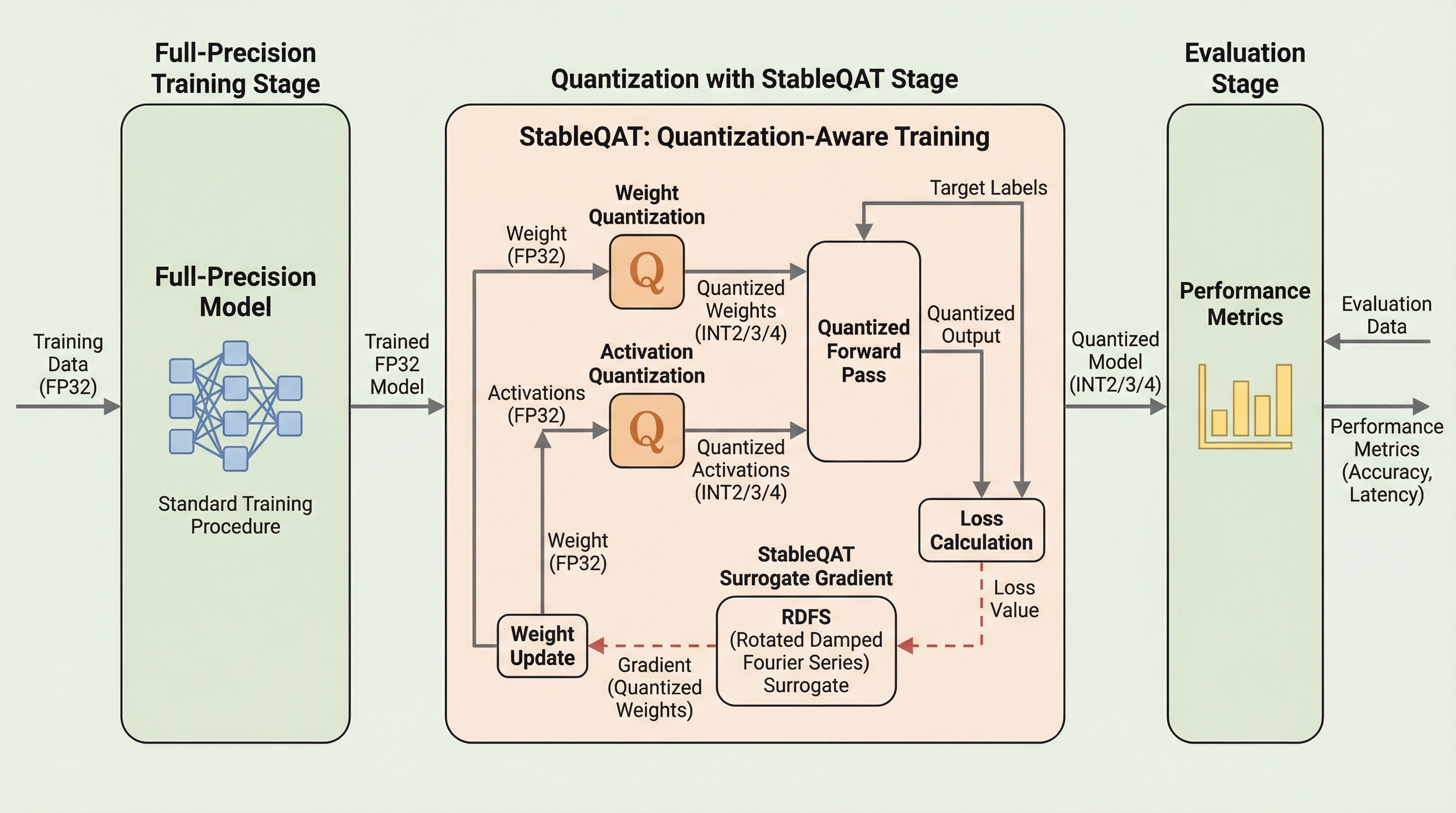
StableQATは、2ビットから4ビットという極めて低いビット幅における量子化意識トレーニング(QAT)を安定化させるための革新的なフレームワークである。従来のストレートスルー推定量(STE)が抱える勾配の不一致や、既存のソフト量子化手法が伴う膨大な計算コストといった課題を、離散フーリエ解析に基づく「回転減衰フーリエ代理関数(RDFS)」の導入によって根本から解決する。 この手法は、丸め操作の幾何学的な構造を周波数領域で捉え直すことで、勾配の分散を一定の範囲内に抑えつつ、滑らかで有界な最適化方向をモデルに提供する。その結果、追加の計算負荷をほとんど発生させることなく、大規模言語モデル(LLM)などの学習安定性と最終的な推論精度を大幅に向上させることが可能となった。 理論的にはSTEを特殊なケースとして包含する一般化された形式を持ち、実装面でも既存の学習パイプラインへ容易に統合できるプラグアンドプレイな特性を備えている。これにより、メモリや電力の制約が厳しい環境下での高性能なAIモデルの展開を強力に支援し、エッジデバイス等での効率的な推論を実現する。
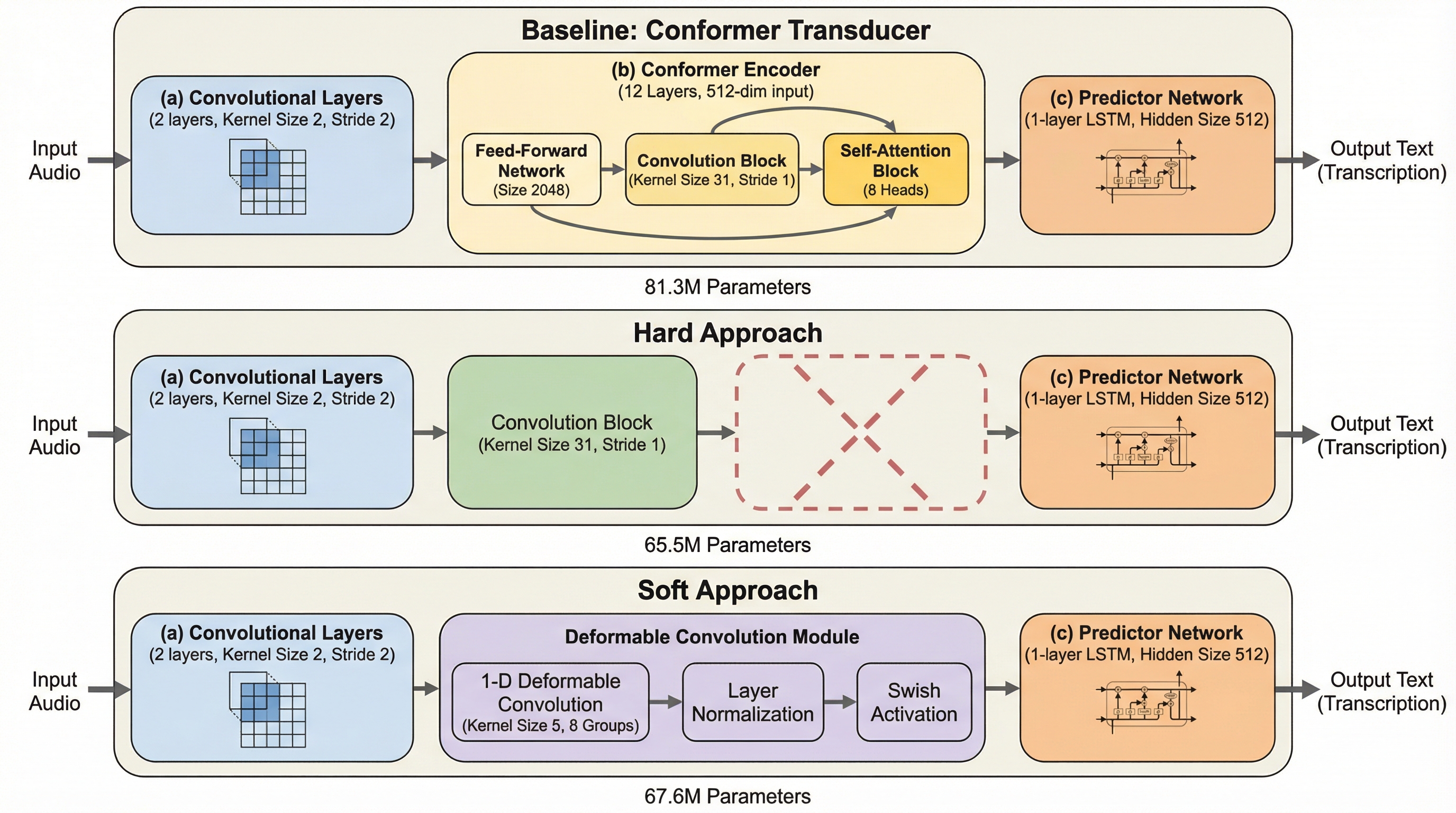
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。