コンテキスト付き待ち行列バンディットにおけるキュー長リグレット上界
本研究は、個々のジョブが異なる特徴量(コンテキスト)を持つ環境下で、未知のサービス率を学習しながら効率的なスケジューリングを行う「コンテキスト付き待ち行列バンディット」という新しい枠組みを提案した。
TL;DR(結論)
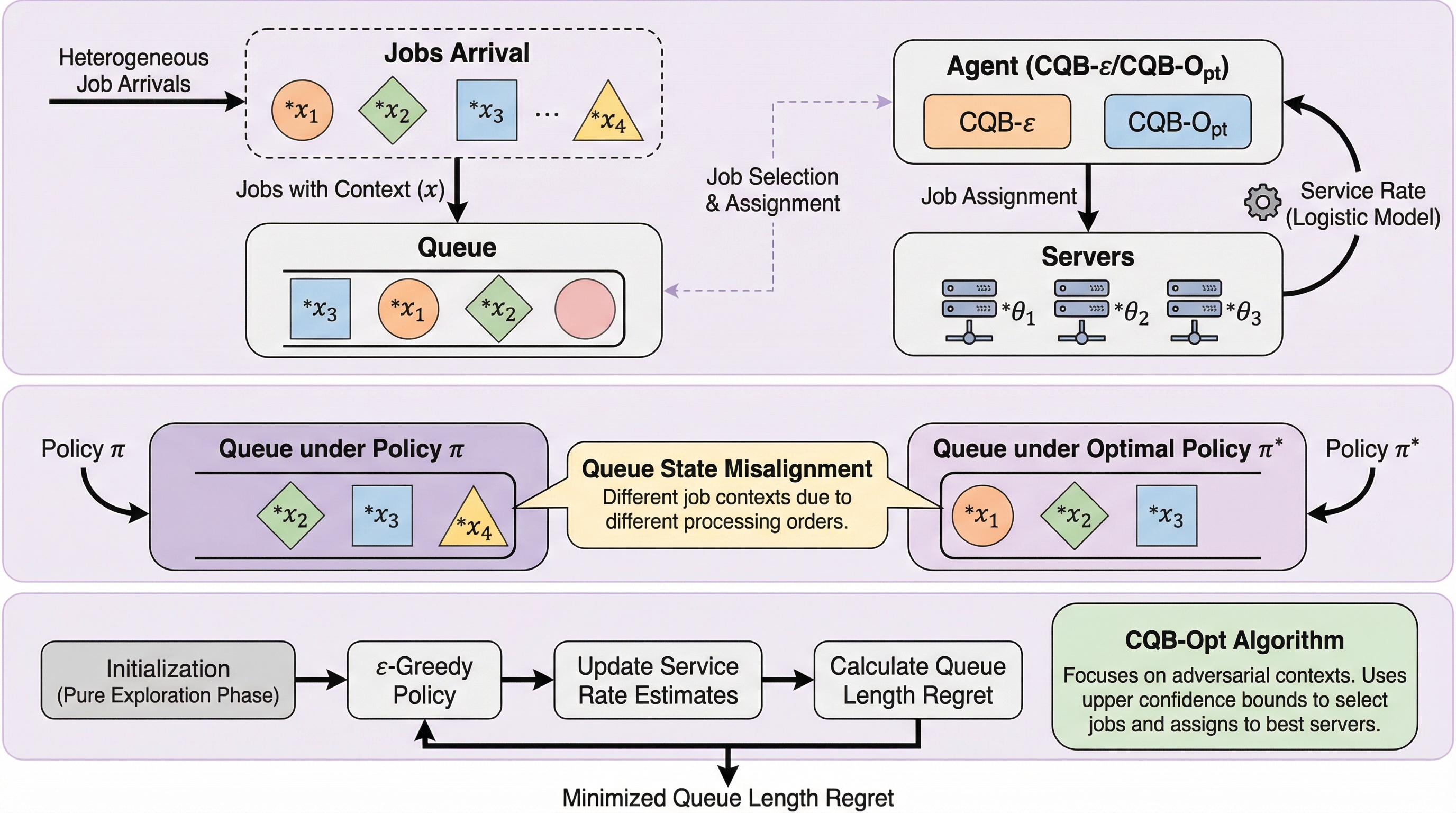
本研究は、個々のジョブが異なる特徴量(コンテキスト)を持つ環境下で、未知のサービス率を学習しながら効率的なスケジューリングを行う「コンテキスト付き待ち行列バンディット」という新しい枠組みを提案した。 提案手法では、方策によって処理順序が異なるために生じる「キュー状態の不一致」という課題に対し、方策切り替えキューとカップリング引数を用いた新しいリグレット分解手法を導入することで、理論的な解析を可能にした。 確率的な設定におけるアルゴリズムCQB-εで収束するリグレット上界を、敵対的な設定におけるCQB-Optで対数的なリグレット上界を達成し、理論的な正当性を実験によって検証した。
なぜこの問題か
現代のサービスプラットフォームにおいて、待ち行列システムの制御は極めて重要な役割を果たしている。クラウドジョブのスケジューラやパーソナライズされた推薦システム、配車サービス、配送市場、コールセンター、さらには大規模言語モデル(LLM)の推論処理など、多岐にわたる分野でこの仕組みが利用されている。これらのプラットフォームにおける中心的な困難は、ジョブのサイズ、電力使用量、ユーザープロファイル、互換デバイスといった多様な特徴やコンテキストを持つ個々のジョブを考慮しながら、適切なプロセッサに割り当てる必要がある点にある。このようなコンテキストを考慮したサービスを提供することは、全体的なサービス品質を向上させるために不可欠である。 しかし、ジョブごとに異なるコンテキスト特徴量を許容する場合、すべてのジョブとサーバーのペアについて、サービス率(離脱率)を事前に完全に把握していると仮定することは現実的ではない。このため、観測された待ち行列の動態から未知のコンテキスト依存のサービス率をリアルタイムで学習しつつ、同時にジョブとサーバーの割り当てを決定するオンラインアルゴリズムが求められている。…
核心:何を提案したのか
本論文では、未知のサービス率を学習しながらスケジューリングを行うための新しいコンテキスト対応フレームワークとして「コンテキスト付き待ち行列バンディット(Contextual Queueing Bandits)」を提案している。このフレームワークでは、各ジョブが持つコンテキスト特徴量と、サーバー固有の未知のパラメータを用いたロジスティックモデルによって離脱率が決定される。エージェントの目標は、適切なジョブとサーバーのペアを選択することで、離脱率を最大化し、システム全体のキューの長さを最小限に抑えることである。 このフレームワークの評価指標として、本研究は「キュー長リグレット」を採用している。これは、ある時点における提案方策下のキューの長さと、すべてのパラメータを既知とする最適方策下のキューの長さの期待値の差として定義される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related