方策勾配法を用いた線形システムの出力フィードバック安定化
本研究は、システムモデルが未知である離散時間線形動的システムにおいて、観測可能な出力情報のみを利用してシステムを安定化させるための新しいモデルフリーな方策勾配法を提案している。従来の全状態フィードバックを前提とした手法とは異なり、出力フィードバック特有の非凸性や勾配優位性の欠如という困難に対し、割引因子を段階的に調整する「割引法」と零次最適化を組み合わせることで、開ループで不安定なシステムを確実に安定化領域へと導く。提案アルゴリズムは、システムの実行軌道データから勾配を推定する二点推定法を採用しており、非凸な最適化環境下での停留点への収束保証とともに、安定化に必要な総サンプル複雑性を理論的に明示し、数値シミュレーションによってその有効性を実証している。
TL;DR(結論)
本研究は、システムモデルが未知である離散時間線形動的システムにおいて、観測可能な出力情報のみを利用してシステムを安定化させるための新しいモデルフリーな方策勾配法を提案している。従来の全状態フィードバックを前提とした手法とは異なり、出力フィードバック特有の非凸性や勾配優位性の欠如という困難に対し、割引因子を段階的に調整する「割引法」と零次最適化を組み合わせることで、開ループで不安定なシステムを確実に安定化領域へと導く。提案アルゴリズムは、システムの実行軌道データから勾配を推定する二点推定法を採用しており、非凸な最適化環境下での停留点への収束保証とともに、安定化に必要な総サンプル複雑性を理論的に明示し、数値シミュレーションによってその有効性を実証している。
なぜこの問題か
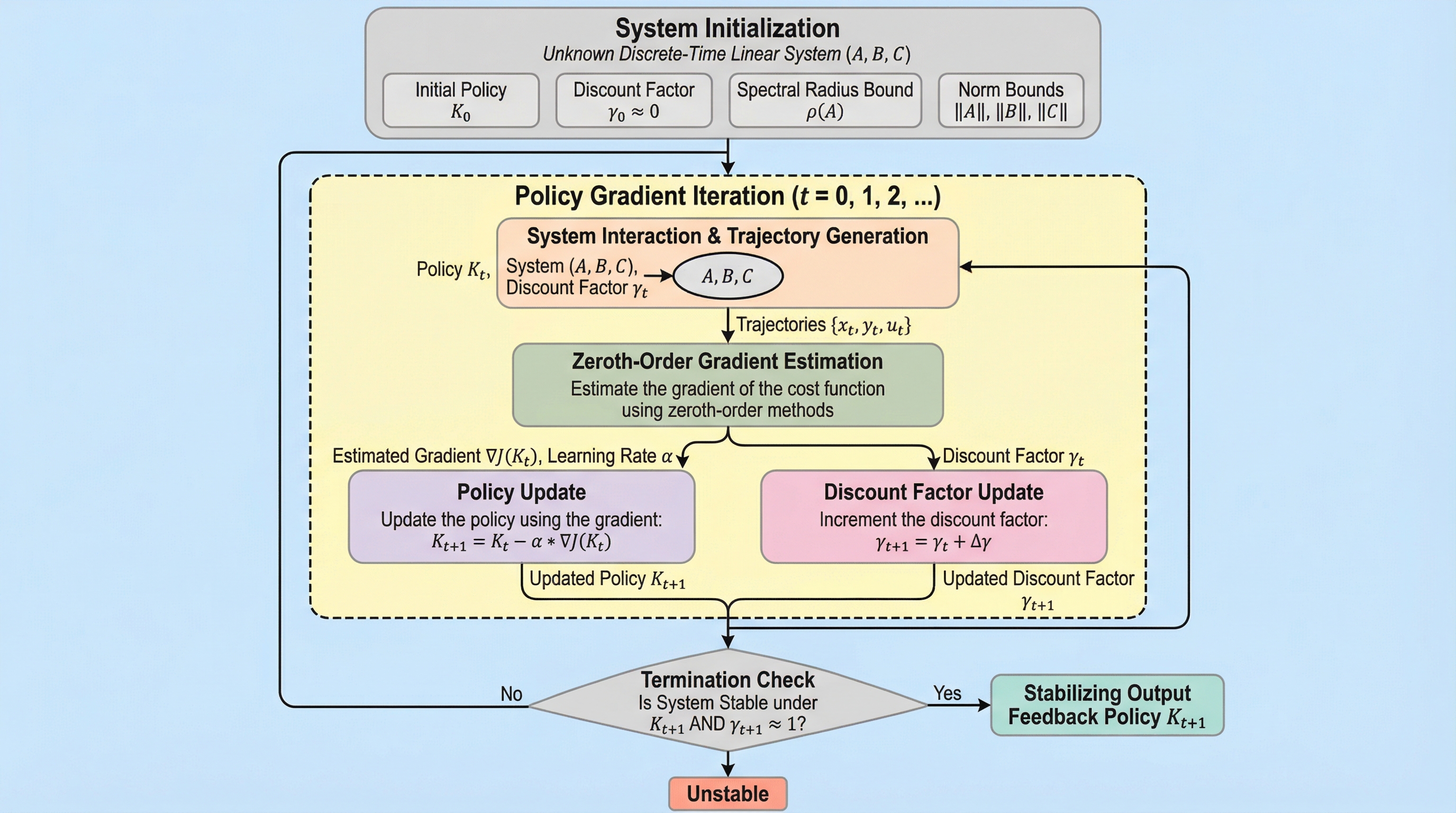
動的システムの安定化は制御理論における最も基本的かつ重要な課題であり、線形二次レギュレータ(LQR)などの高度な制御タスクを解決するための必須の前提条件となっている。システムモデルが既知であれば設計は容易だが、現実の複雑なアプリケーションでは正確な数式モデルを得ることは困難であり、データから直接制御則を学習するモデルフリーな手法が強く求められている。強化学習の一種である方策勾配法は、モデルを介さずに最適な制御方策を探索できるため注目を集めてきたが、これまでの研究の多くはシステムの状態すべてが直接観測可能であることを前提とした全状態フィードバックに焦点を当てていた。しかし、実際の産業現場や大規模システムにおいては、コストや技術的な制約からすべての内部状態を計測することは不可能であり、限定的な出力情報のみを利用する出力フィードバック制御が実用上極めて重要である。 出力フィードバックの設定では、全状態フィードバックの場合とは異なり、最適化の対象となるコスト関数が勾配優位性(Polyak-Łojasiewicz条件)を持たず、安定化方策の集合が非連結になる可能性があるという構造的な困難が存在する。…
核心:何を提案したのか
本研究の核心は、未知の離散時間線形システムに対して、静的出力フィードバック(SOF)コントローラを学習するための新しいモデルフリーなアルゴリズムの枠組みを提案したことにある。具体的には、開ループで不安定なシステムを安定化させるために、割引因子を用いた「割引法」を出力フィードバックの設定に拡張して導入している。この手法は、元の不安定なシステムの安定化問題を、適切に選択された割引因子を持つ一連の減衰システムの学習問題へと変換するものである。これにより、初期状態としてゼロ方策のような単純な方策から開始し、割引因子を段階的に1に近づけていくことで、最終的に元のシステムの安定化コントローラを得ることが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related