StableQAT:超低ビット幅における安定した量子化意識トレーニング
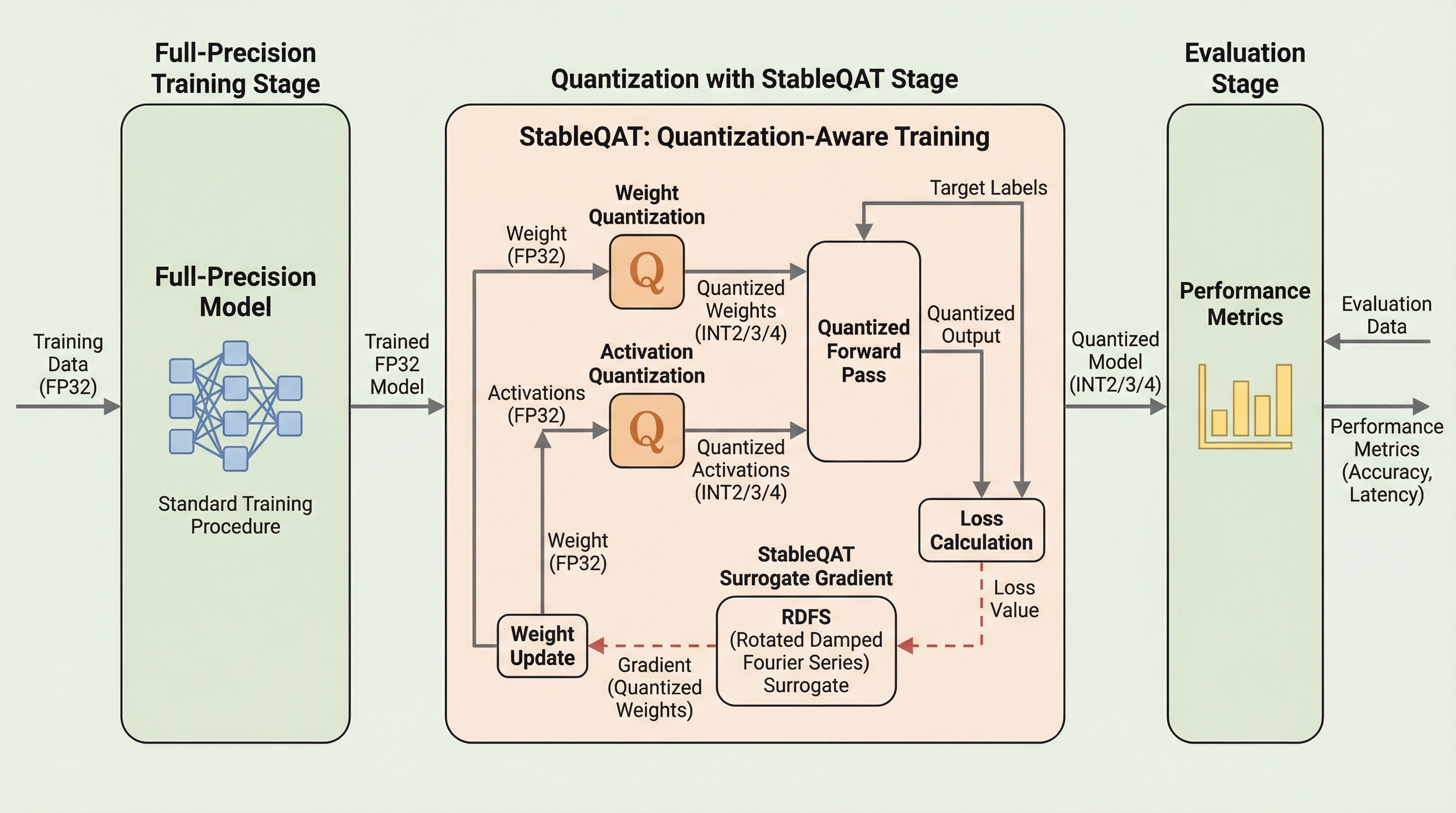
StableQATは、2ビットから4ビットという極めて低いビット幅における量子化意識トレーニング(QAT)を安定化させるための革新的なフレームワークである。従来のストレートスルー推定量(STE)が抱える勾配の不一致や、既存のソフト量子化手法が伴う膨大な計算コストといった課題を、離散フーリエ解析に基づく「回転減衰フーリエ代理関数(RDFS)」の導入によって根本から解決する。 この手法は、丸め操作の幾何学的な構造を周波数領域で捉え直すことで、勾配の分散を一定の範囲内に抑えつつ、滑らかで有界な最適化方向をモデルに提供する。その結果、追加の計算負荷をほとんど発生させることなく、大規模言語モデル(LLM)などの学習安定性と最終的な推論精度を大幅に向上させることが可能となった。 理論的にはSTEを特殊なケースとして包含する一般化された形式を持ち、実装面でも既存の学習パイプラインへ容易に統合できるプラグアンドプレイな特性を備えている。これにより、メモリや電力の制約が厳しい環境下での高性能なAIモデルの展開を強力に支援し、エッジデバイス等での効率的な推論を実現する。
TL;DR(結論)
StableQATは、2ビットから4ビットという極めて低いビット幅における量子化意識トレーニング(QAT)を安定化させるための革新的なフレームワークである。従来のストレートスルー推定量(STE)が抱える勾配の不一致や、既存のソフト量子化手法が伴う膨大な計算コストといった課題を、離散フーリエ解析に基づく「回転減衰フーリエ代理関数(RDFS)」の導入によって根本から解決する。 この手法は、丸め操作の幾何学的な構造を周波数領域で捉え直すことで、勾配の分散を一定の範囲内に抑えつつ、滑らかで有界な最適化方向をモデルに提供する。その結果、追加の計算負荷をほとんど発生させることなく、大規模言語モデル(LLM)などの学習安定性と最終的な推論精度を大幅に向上させることが可能となった。 理論的にはSTEを特殊なケースとして包含する一般化された形式を持ち、実装面でも既存の学習パイプラインへ容易に統合できるプラグアンドプレイな特性を備えている。これにより、メモリや電力の制約が厳しい環境下での高性能なAIモデルの展開を強力に支援し、エッジデバイス等での効率的な推論を実現する。
なぜこの問題か
大規模言語モデル(LLM)を実用的なデバイスに展開する際、メモリ帯域幅や電力消費、ハードウェアのスループットといった厳しい制約が大きな障壁となる。フル精度のモデルは巨大すぎて、一般的なエッジデバイスやモバイル環境での推論は現実的ではない。このため、重みや活性化関数を低精度なビット幅に変換する量子化技術が不可欠となっている。しかし、従来の事後量子化(PTQ)は8ビット精度では良好な結果を示すものの、4ビットを下回る超低ビット領域では、データの分布が不均一であるために精度が急激に低下するという致命的な欠点がある。 この精度低下を克服するために、学習プロセスの中で量子化の影響を考慮する量子化意識トレーニング(QAT)が広く用いられている。QATはモデルを離散化によるノイズに適応させることで、低ビット化に伴う誤差を最小限に抑える効果がある。しかし、ビット幅が低くなるほど最適化のプロセスは極めて脆弱になり、学習の安定性と精度の両立が困難になる。この不安定性の根本的な原因は、順伝播における離散的な丸め処理と、逆伝播における連続的な勾配ベースの最適化との間に存在する深刻な不一致にある。…
核心:何を提案したのか
本研究では、低ビット量子化における最適化のボトルネックを解消するための、シンプルかつ柔軟で効果的なフレームワークであるStableQATを提案している。この提案の核心は、量子化演算子の新しい代理関数として「回転減衰フーリエ代理関数(RDFS)」を導入した点にある。RDFSは、丸め操作のスペクトル構造をフーリエ解析によってモデル化し、幾何学的な回転を加えることで、滑らかで有界な最適化方向を導き出すものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related