拡散モデルにおける汎化のためのスコア関数の平滑化:最適化に基づく説明フレームワーク
拡散モデルが訓練データをそのまま複製してしまう「記憶」現象は、理論上の経験的スコア関数が非常に鋭いソフトマックス重みを持つガウス分布の和として構成され、サンプリングが特定の訓練点へ崩壊することに起因することを解明した。
TL;DR(結論)
拡散モデルが訓練データをそのまま複製してしまう「記憶」現象は、理論上の経験的スコア関数が非常に鋭いソフトマックス重みを持つガウス分布の和として構成され、サンプリングが特定の訓練点へ崩壊することに起因することを解明した。 ニューラルネットワークはこの鋭い重みを学習過程で暗黙的に平滑化することで、単一の点ではなく局所的な多様体の影響を受けやすくし、これが未知のデータを生成する「汎化」の鍵であることを理論と実験の両面から突き止めた。 汎化を明示的に制御するため、ノイズ条件付けを排除して各訓練点が最適な影響範囲を適応的に決定する「ノイズ非条件付け」と、重みの滑らかさを直接操作する「温度平滑化」の二手法を提案し、生成品質を保ちつつ記憶を抑制することに成功した。
なぜこの問題か
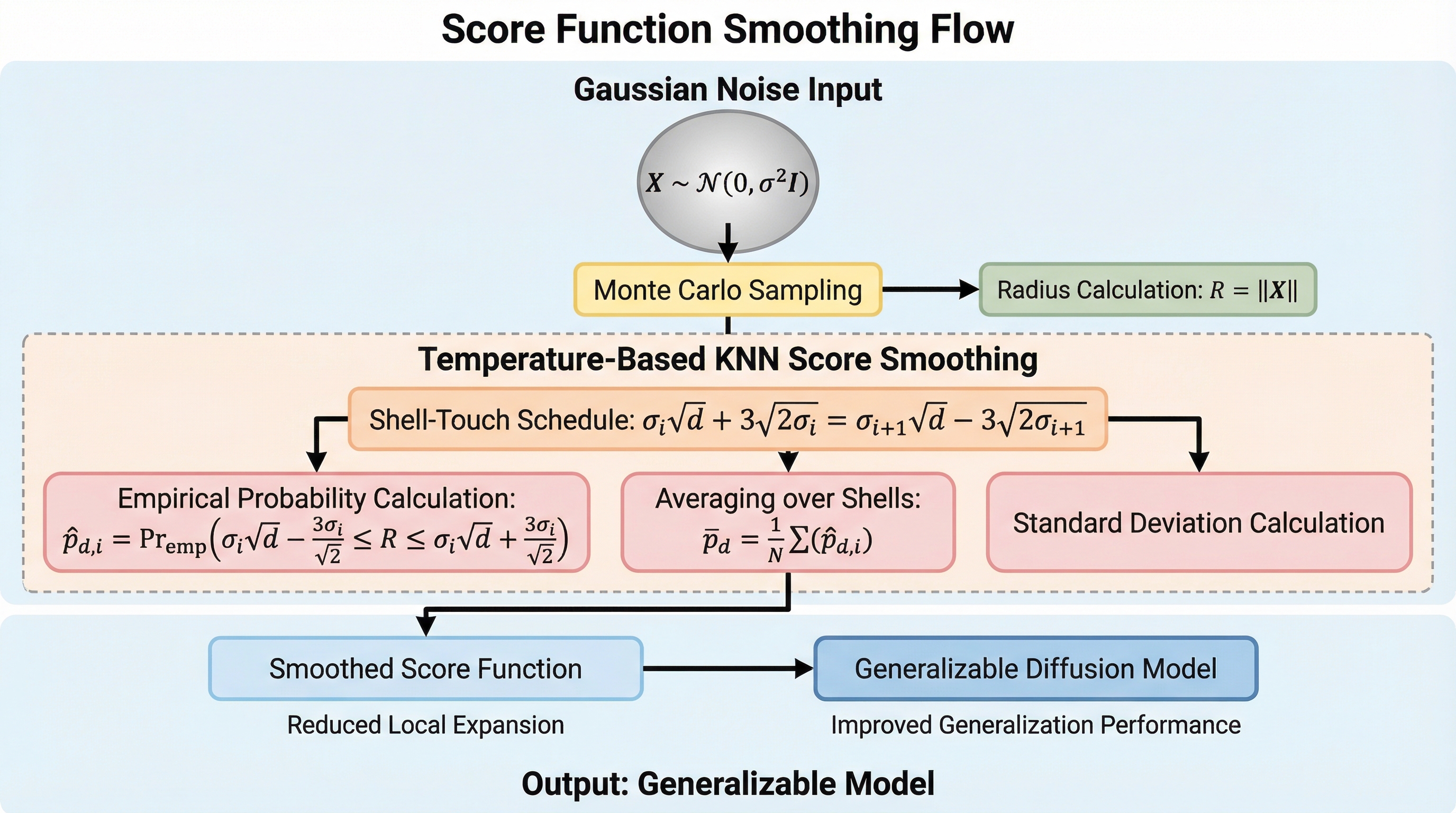
拡散モデルは、テキストからの画像生成や複雑なタンパク質構造の予測など、現代の生成AIにおける中心的な技術として目覚ましい成果を上げている。このモデルの根幹は、データに対して段階的にガウスノイズを付加していく順方向のプロセスと、そのノイズを除去して元のデータ分布を復元する逆方向のスコアベースのデノイジング学習にある。しかし、高次元空間におけるデータ分布は「多様体仮説」に基づき、極めて限定的な領域にのみ存在している。このため、データの密度が低い領域では勾配の推定が困難になり、スコアマッチングが適切に機能しなくなるという本質的な課題を抱えている。拡散モデルはこの問題を解決するために、ニューラルネットワークを用いて一連の周辺分布を近似し、サンプリング経路全体でスコア関数を正確に学習するように設計されている。 しかし、近年の研究によって、拡散モデルが高い生成品質を実現する一方で、生成されたサンプルが訓練データと完全に一致してしまう「記憶(memorization)」という深刻な問題が浮き彫りになった。この現象は、理論的な分布の進化の観点から説明が可能である。…
核心:何を提案したのか
本研究の最大の貢献は、拡散モデルにおける記憶と汎化のメカニズムを「スコア関数の平滑化」という観点から統一的に説明する理論的枠組みを構築したことである。まず、訓練データの経験分布に対応する「経験的スコア関数」が、個々の訓練サンプルを中心とするガウス分布のスコア関数の加重和として厳密に表されることを示した。この際、各サンプルに割り当てられる重みは、非常に鋭い特性を持つソフトマックス関数として振る舞う。この数学的構造により、サンプリングプロセスにおいて特定の訓練サンプルがスコア関数を支配してしまい、結果として生成される点がその訓練サンプルの一点へと収束(崩壊)してしまうことが、記憶現象の正体であると定義した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related