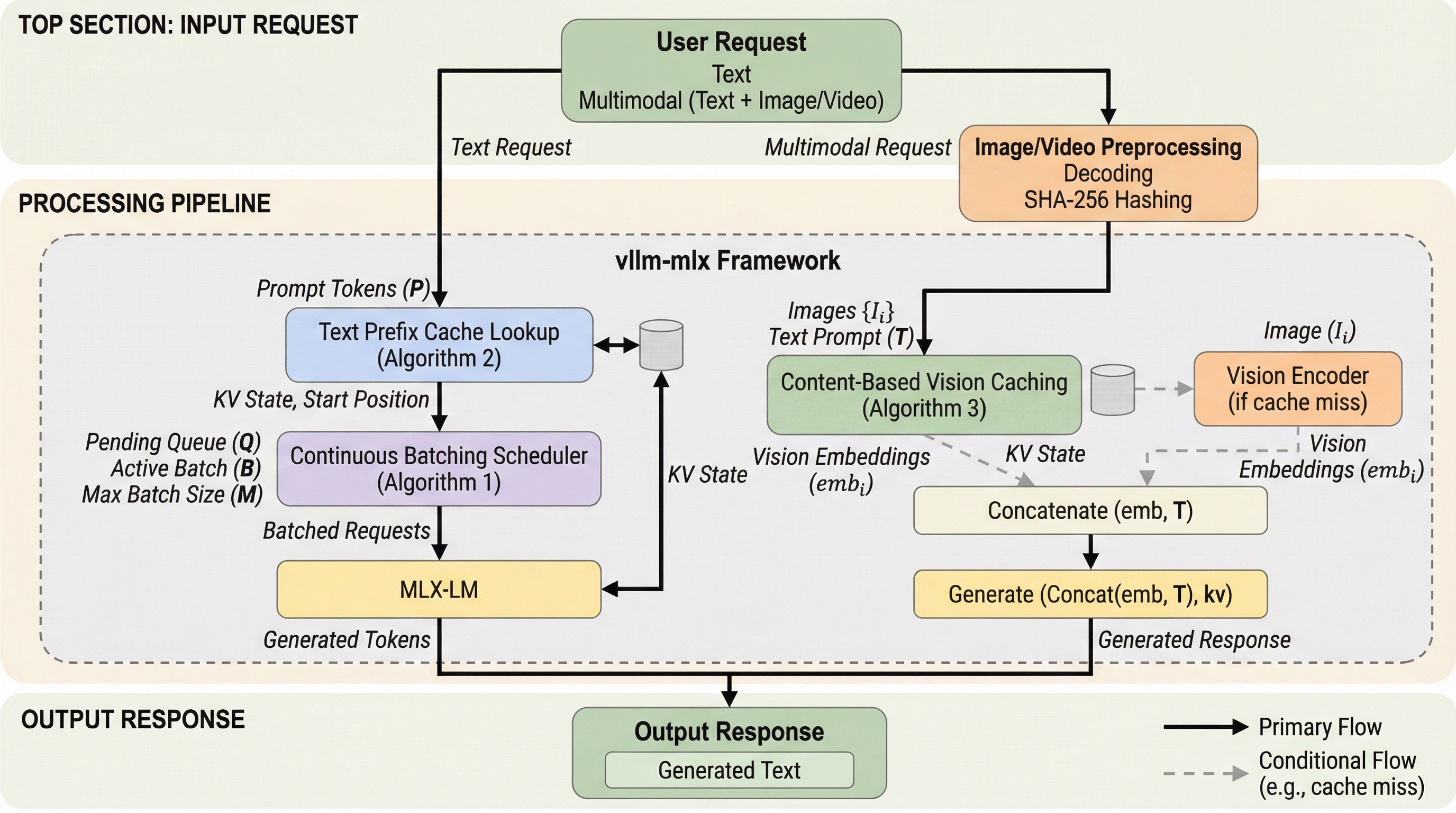
Appleシリコン上での大規模なネイティブLLMおよびMLLM推論
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.
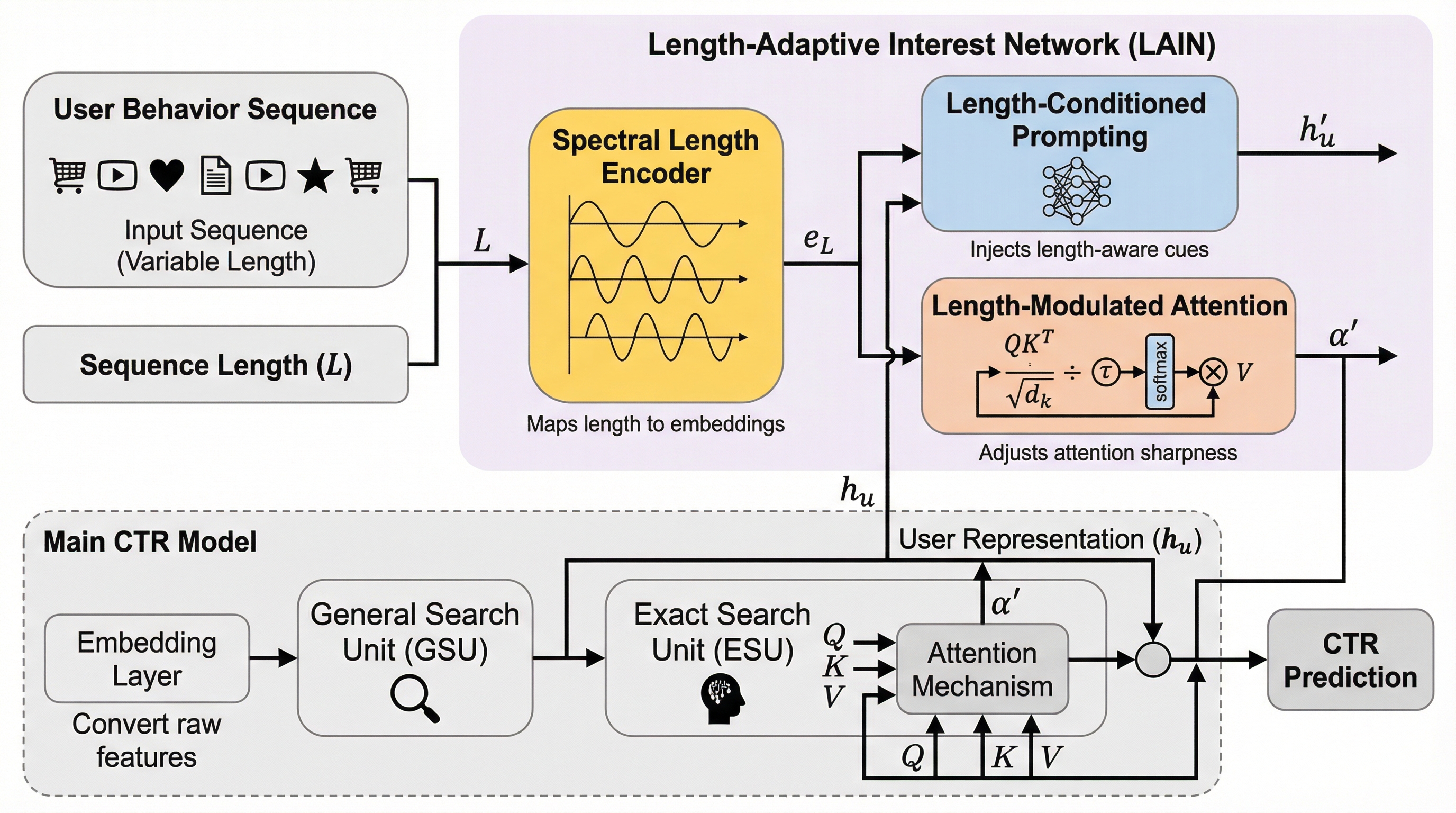
既存のクリック率(CTR)予測モデルにおいて、入力可能な行動履歴の長さを拡張すると、長期履歴を持つユーザーの精度は向上する一方で、短期履歴しか持たないユーザーの精度が逆に低下するという「長さの不均衡」による弊害が生じていることを明らかにした。
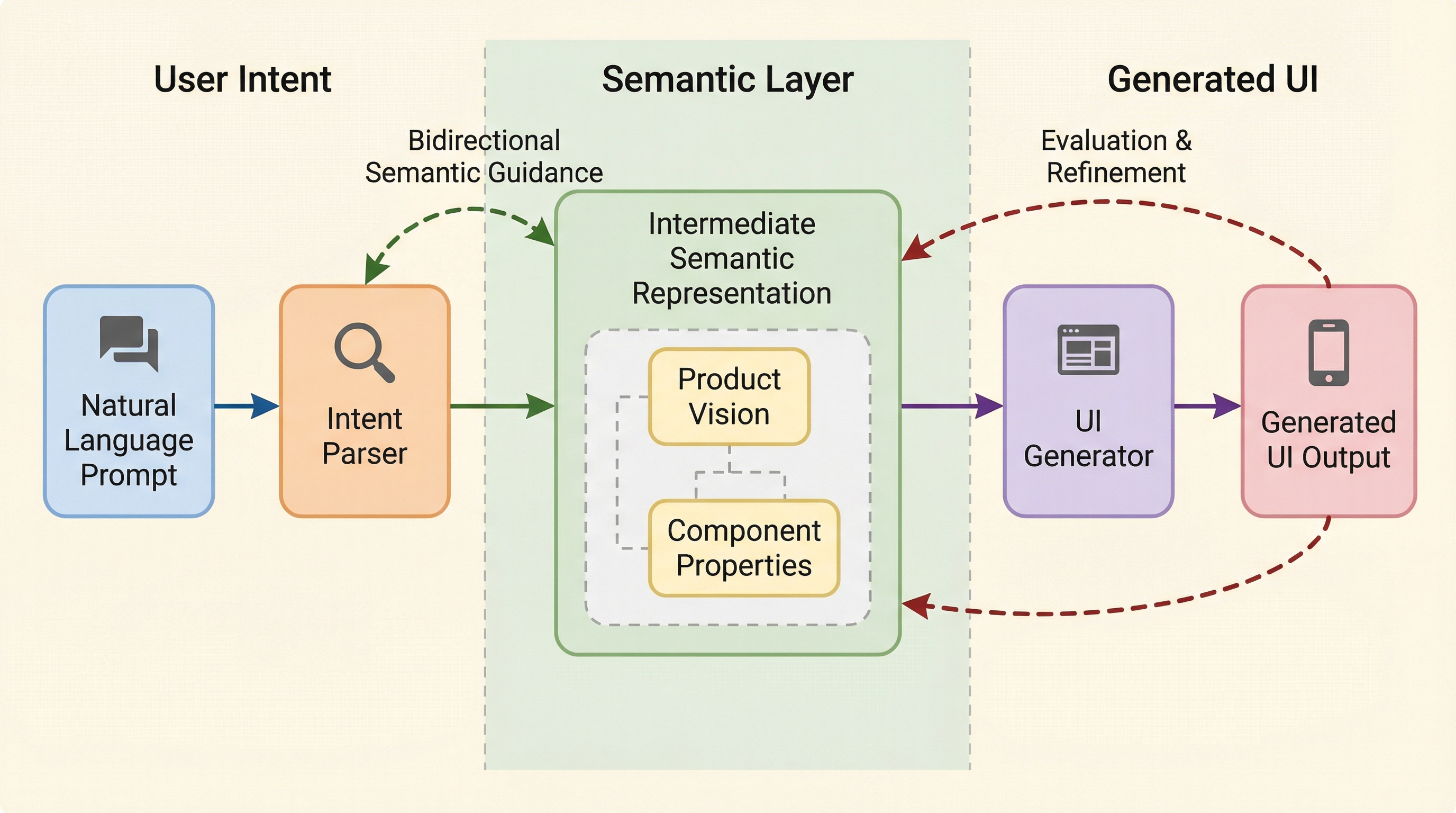
現在のテキストからUIを生成するAIシステムでは、ユーザーが自身のデザイン意図を言語化して伝えることが難しく、また生成された結果がなぜそのようになったのかを理解して修正することが困難であるという、実行と評価の両面における大きな隔たりが存在している。
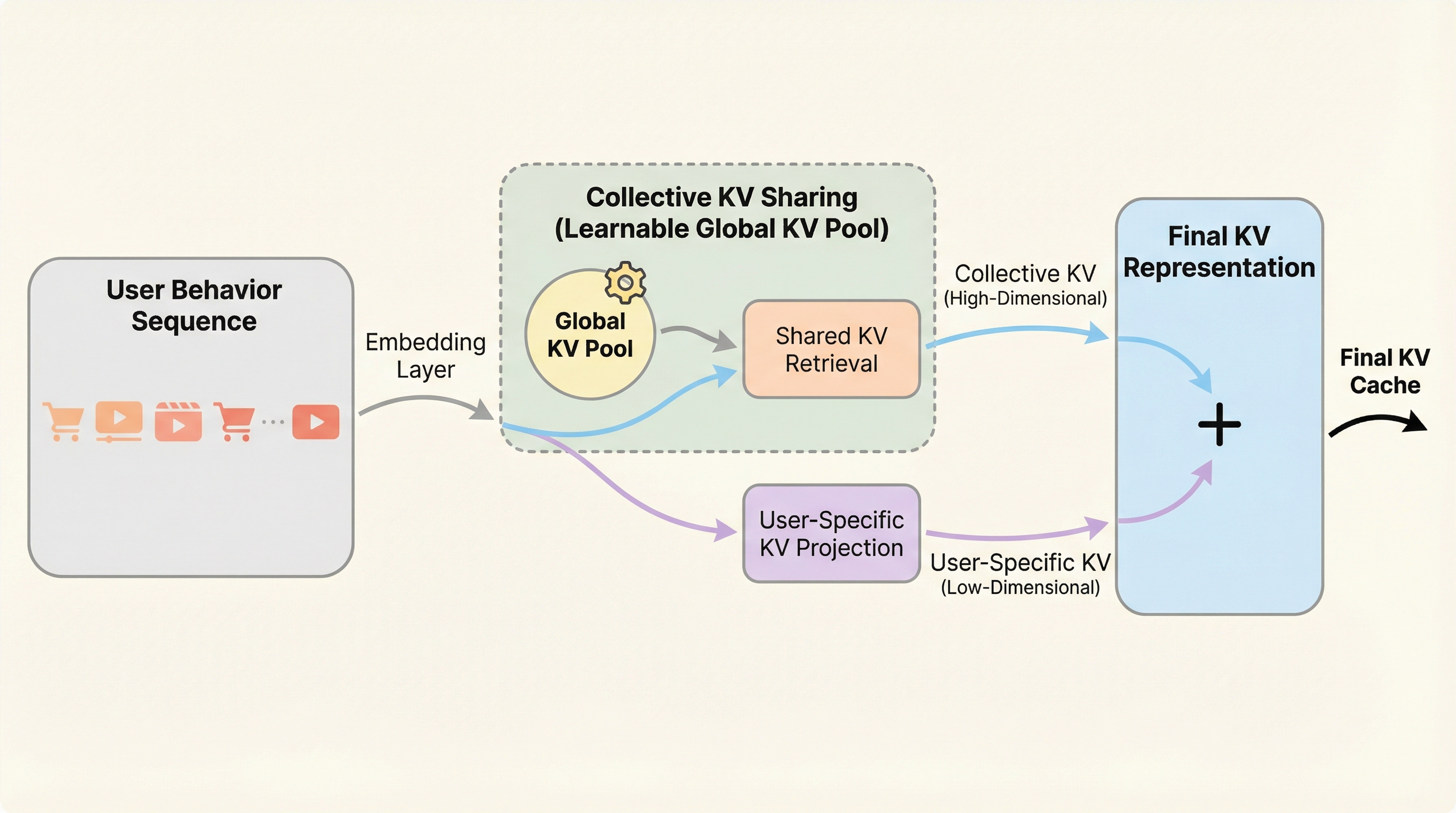
逐次推薦システムにおけるTransformerのKVキャッシュが引き起こす膨大なストレージ消費と推論遅延を解決するため、ユーザー間の協調情報を活用してキャッシュを劇的に圧縮する新手法「CollectiveKV」が提案されました。
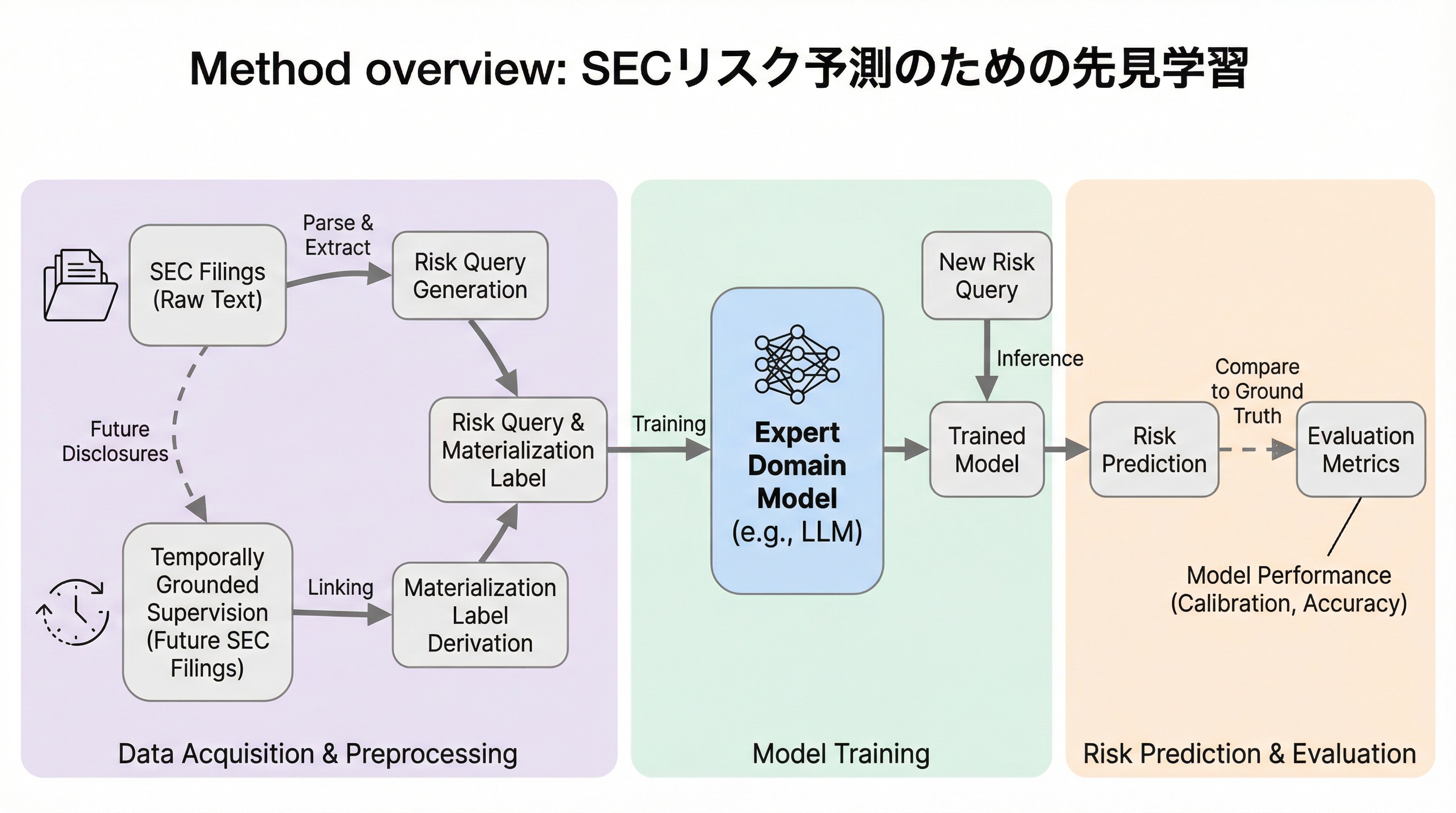
米国証券取引委員会(SEC)への提出書類に含まれる定性的なリスク情報を、将来の開示情報と自動的に紐付けることで、大規模な教師あり学習用データセットを構築する「LightningRod AI」パイプラインを提案した。
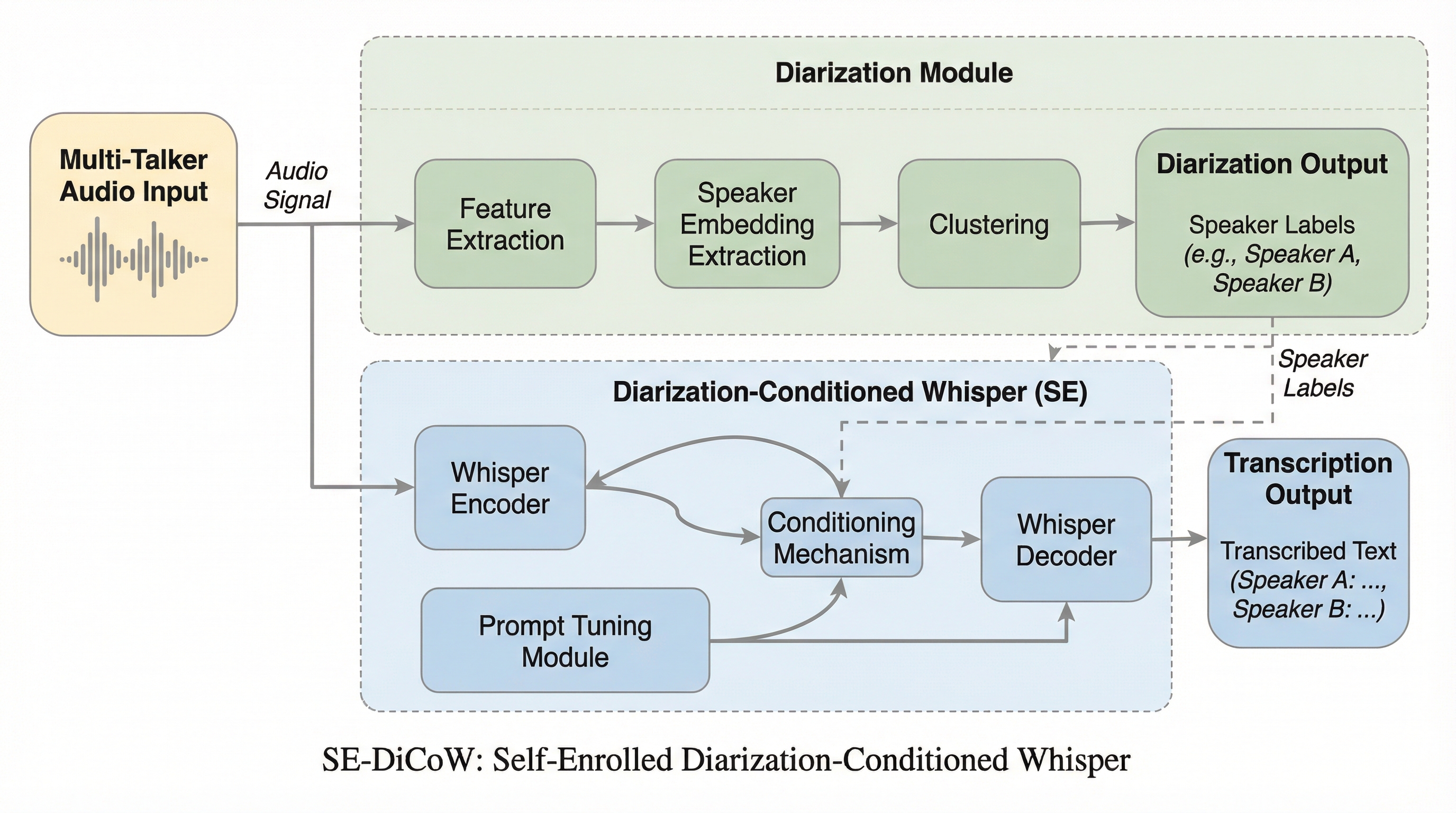
複数話者が同時に発話する環境において、従来の話者属性付き音声認識(ASR)は、話者が完全に重なる区間で情報の曖昧さが生じ、特定の話者を正確に識別することが困難でした。本研究で提案されたSE-DiCoWは、会話全体から対象話者が最も活発な区間を自動的に特定して「自己登録セグメント」として抽出し、クロスアテンション機構を通じてモデルに条件付けを行うことで、この根本的な問題を解決します。この革新的な自己登録メカニズムと学習プロセスの改善により、EMMA MT-ASRベンチマークにおいて従来モデルからエラー率を相対的に52.4%削減し、実環境のデータセットにおいても最先端の性能を達成することに成功しました。
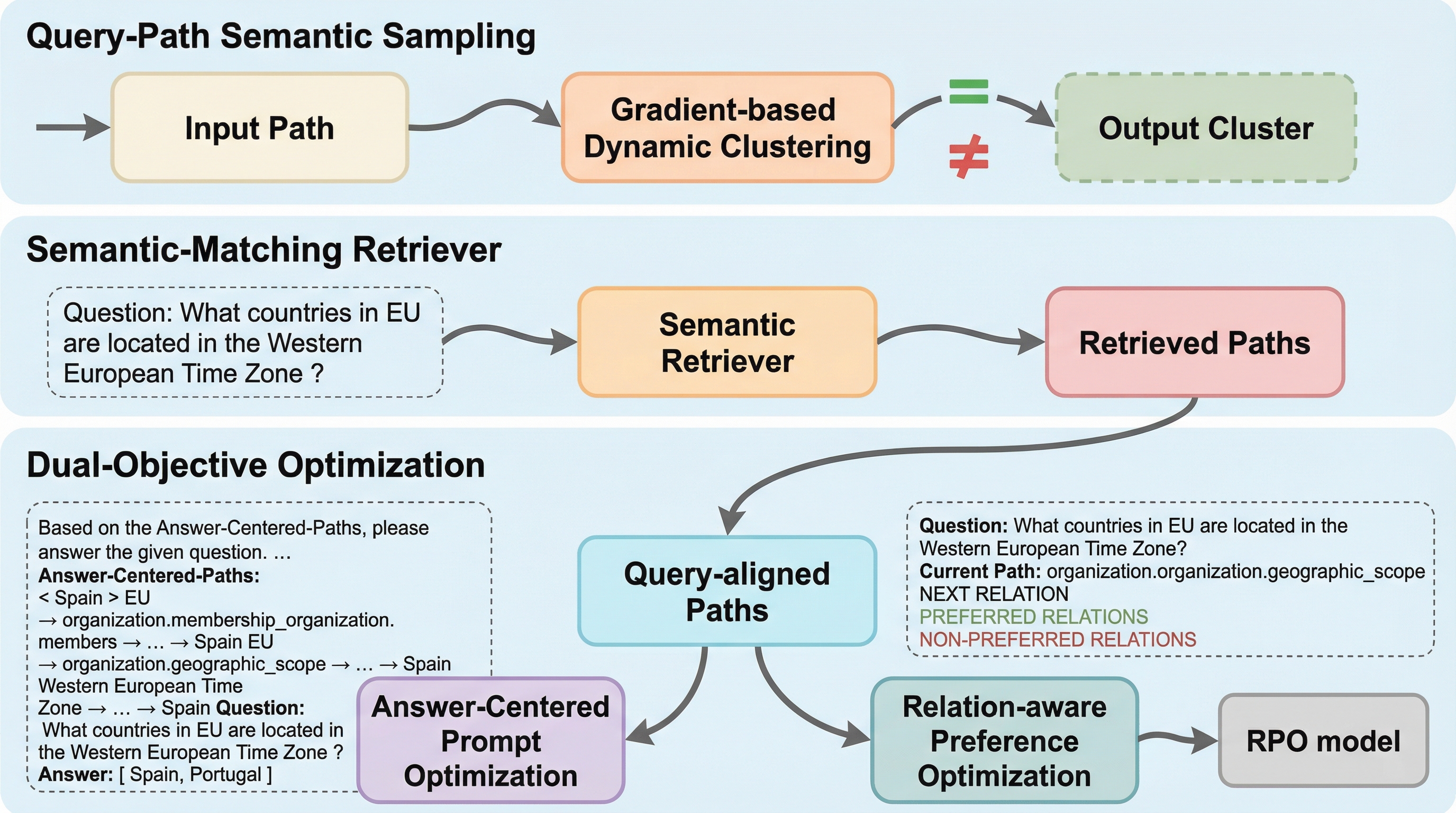
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、知識グラフ(KG)を活用したRAGにおいて、30億パラメータ未満の小規模モデルでも高精度な推論を可能にする新フレームワーク「RPO-RAG」が提案されました。
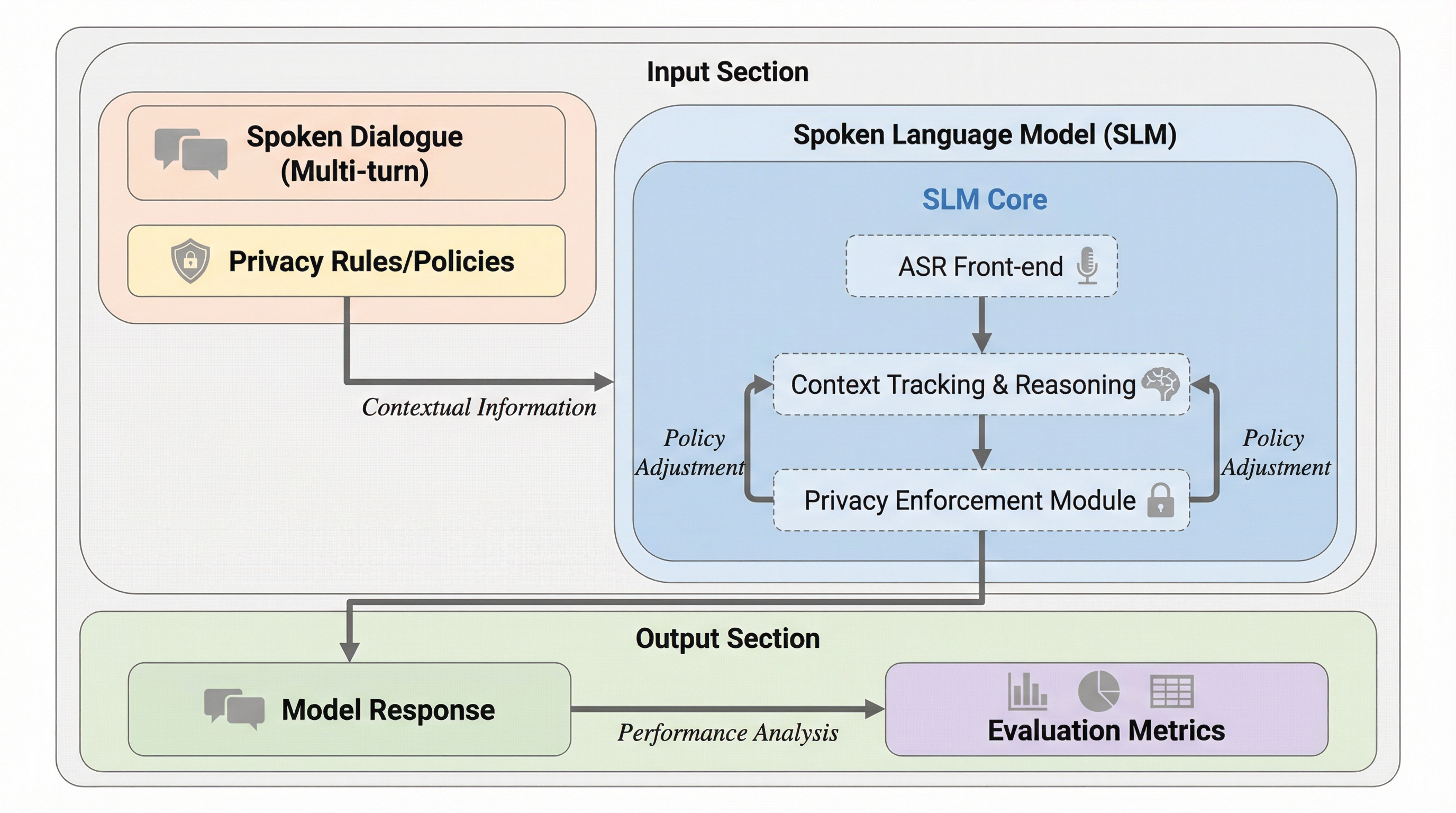
音声言語モデル(SLM)がスマートホーム等の共有環境で、特定の利用者の機密情報を他者に漏洩させる「対話的プライバシー」の欠如を評価するための専用ベンチマーク「VoxPrivacy」が提案された。
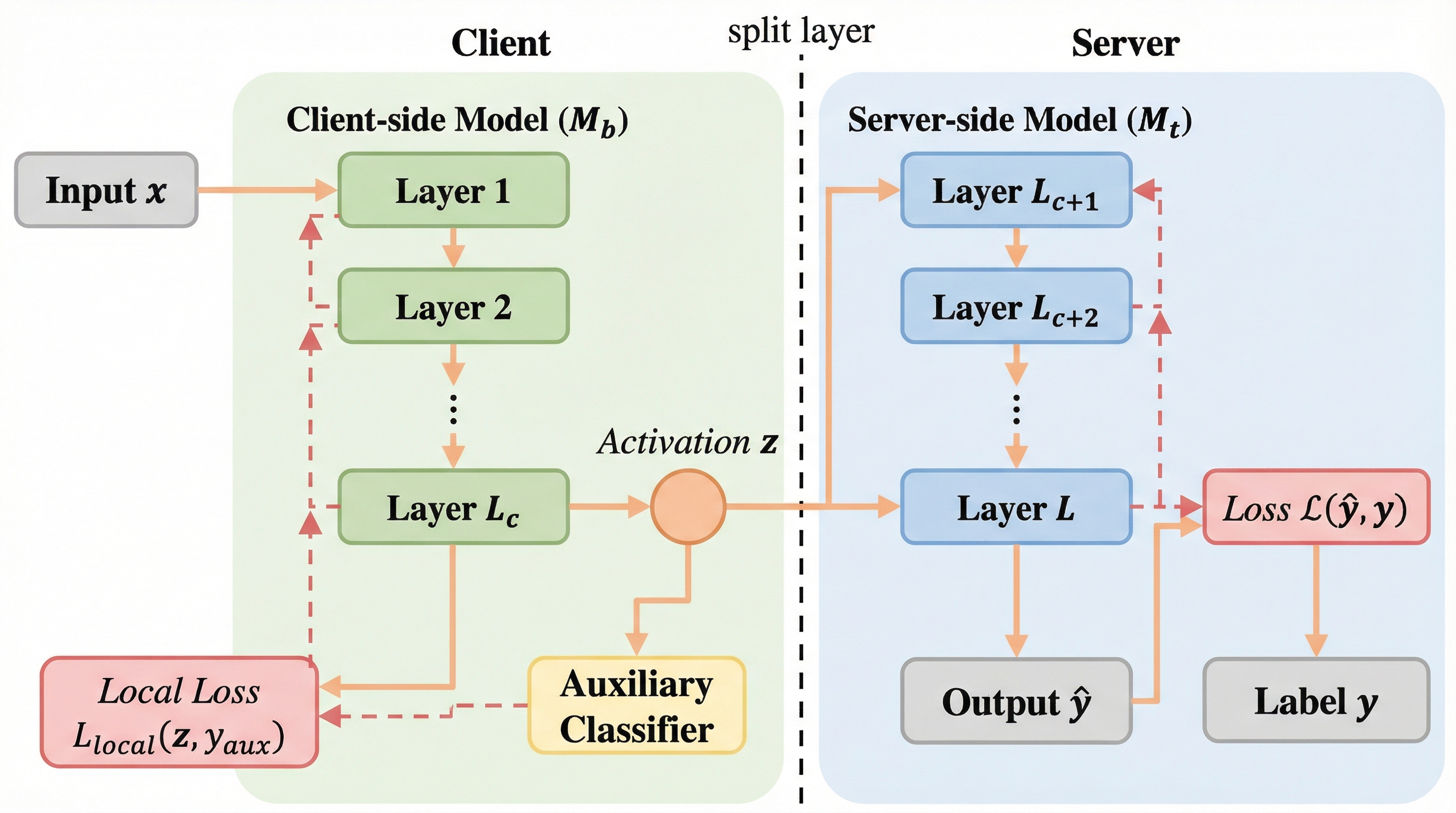
従来の分割学習(Split Learning)が抱えていた、サーバーからの勾配返送待ちによる通信遅延と、バックプロパゲーションのための膨大なメモリ消費という二大課題を、分割点に軽量な補助分類器を導入して学習プロセスを「分離」することで根本から解決しました。
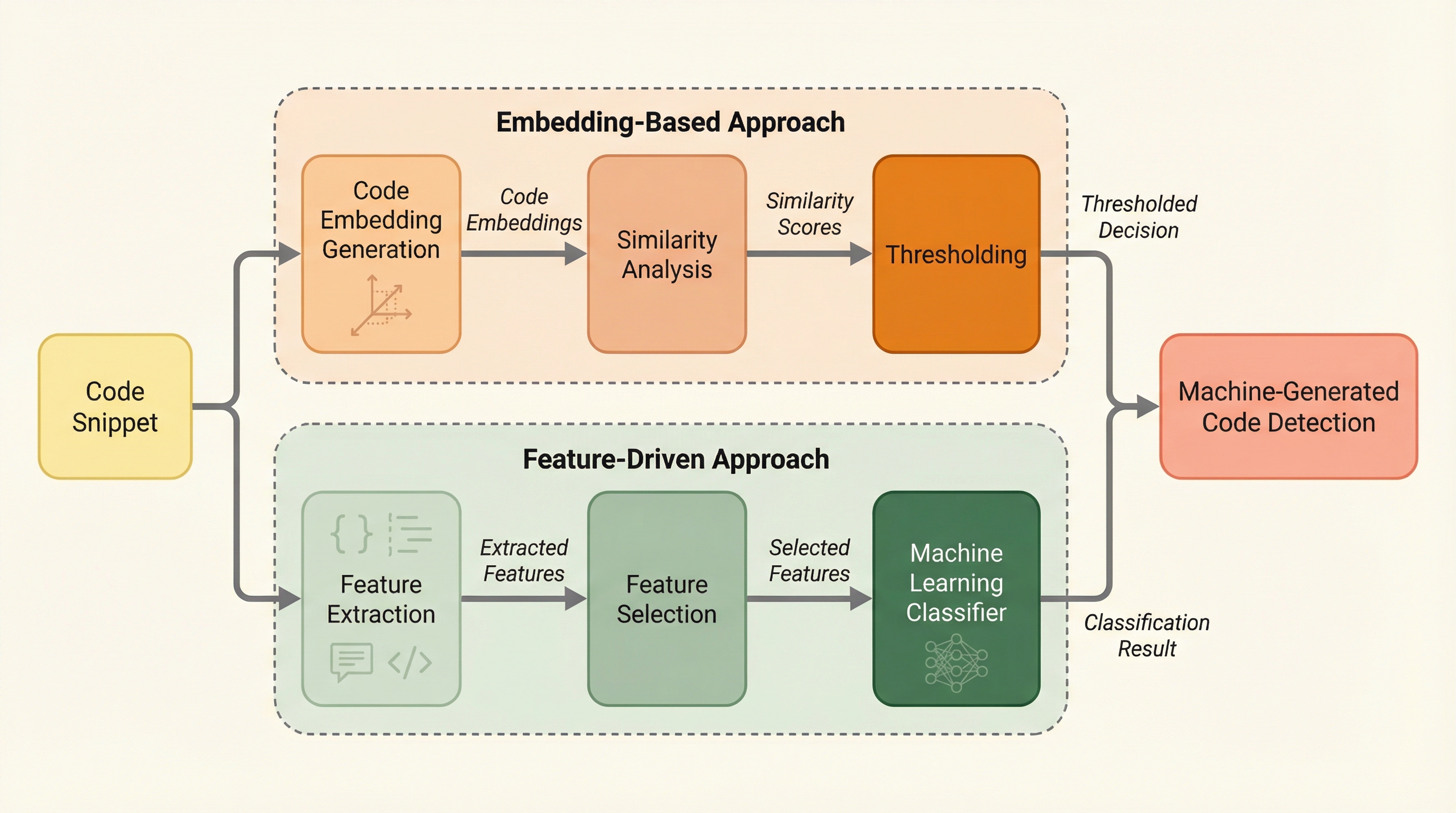
大規模言語モデル(LLM)の普及により、人間が書いたコードとAIが生成したコードを区別することが学術的誠実性や著作権の観点から急務となっています。本研究では、コードの空白や構造に着目した軽量で解釈可能な「特徴量ベース」の手法と、CodeBERTを用いた深い意味理解に基づく「埋め込みベース」の手法の2つを、60万件の大規模データセットを用いて比較検証しました。その結果、特徴量ベースの手法がROC-AUC 0.995という極めて高い性能を示し、特にインデントや空白のパターンがAIと人間を分ける強力な指標であることが判明した一方で、埋め込みベースの手法は高い精度(Precision)を維持するという、両者のトレードオフが明らかになりました。