空白は嘘をつかない:機械生成コード検出のための特徴駆動型および埋め込みベースのアプローチ
大規模言語モデル(LLM)の普及により、人間が書いたコードとAIが生成したコードを区別することが学術的誠実性や著作権の観点から急務となっています。本研究では、コードの空白や構造に着目した軽量で解釈可能な「特徴量ベース」の手法と、CodeBERTを用いた深い意味理解に基づく「埋め込みベース」の手法の2つを、60万件の大規模データセットを用いて比較検証しました。その結果、特徴量ベースの手法がROC-AUC 0.995という極めて高い性能を示し、特にインデントや空白のパターンがAIと人間を分ける強力な指標であることが判明した一方で、埋め込みベースの手法は高い精度(Precision)を維持するという、両者のトレードオフが明らかになりました。
TL;DR(結論)
大規模言語モデル(LLM)の普及により、人間が書いたコードとAIが生成したコードを区別することが学術的誠実性や著作権の観点から急務となっています。本研究では、コードの空白や構造に着目した軽量で解釈可能な「特徴量ベース」の手法と、CodeBERTを用いた深い意味理解に基づく「埋め込みベース」の手法の2つを、60万件の大規模データセットを用いて比較検証しました。その結果、特徴量ベースの手法がROC-AUC 0.995という極めて高い性能を示し、特にインデントや空白のパターンがAIと人間を分ける強力な指標であることが判明した一方で、埋め込みベースの手法は高い精度(Precision)を維持するという、両者のトレードオフが明らかになりました。
なぜこの問題か
ChatGPTやGitHub Copilotといった大規模言語モデル(LLM)の急速な進歩は、ソフトウェア開発とプログラミング教育のあり方を根本から変えてしまいました。これらのシステムは、自然言語の指示から高品質なソースコードを合成し、課題を完了させ、ユニットテストに合格する解決策を提示することを可能にしています。開発者にとってはプロトタイピングの加速や生産性の向上に繋がりますが、教育現場では学生がAI生成のコードを自作として提出するリスクが生じ、評価の妥当性や公平性が損なわれる懸念があります。また、研究や実務の文脈においても、コードの出所が不明確であることは、責任の所在やライセンス、長期的な保守性に複雑な問題をもたらします。 自然言語テキストにおけるAI生成コンテンツの検出は広く研究されていますが、ソースコードへの適用は容易ではありません。コードはテキストよりも構造化されており、形式的な構文や、空白の使用、識別子の命名、制御フロー構造といった強いスタイル上の信号を持っています。…
核心:何を提案したのか
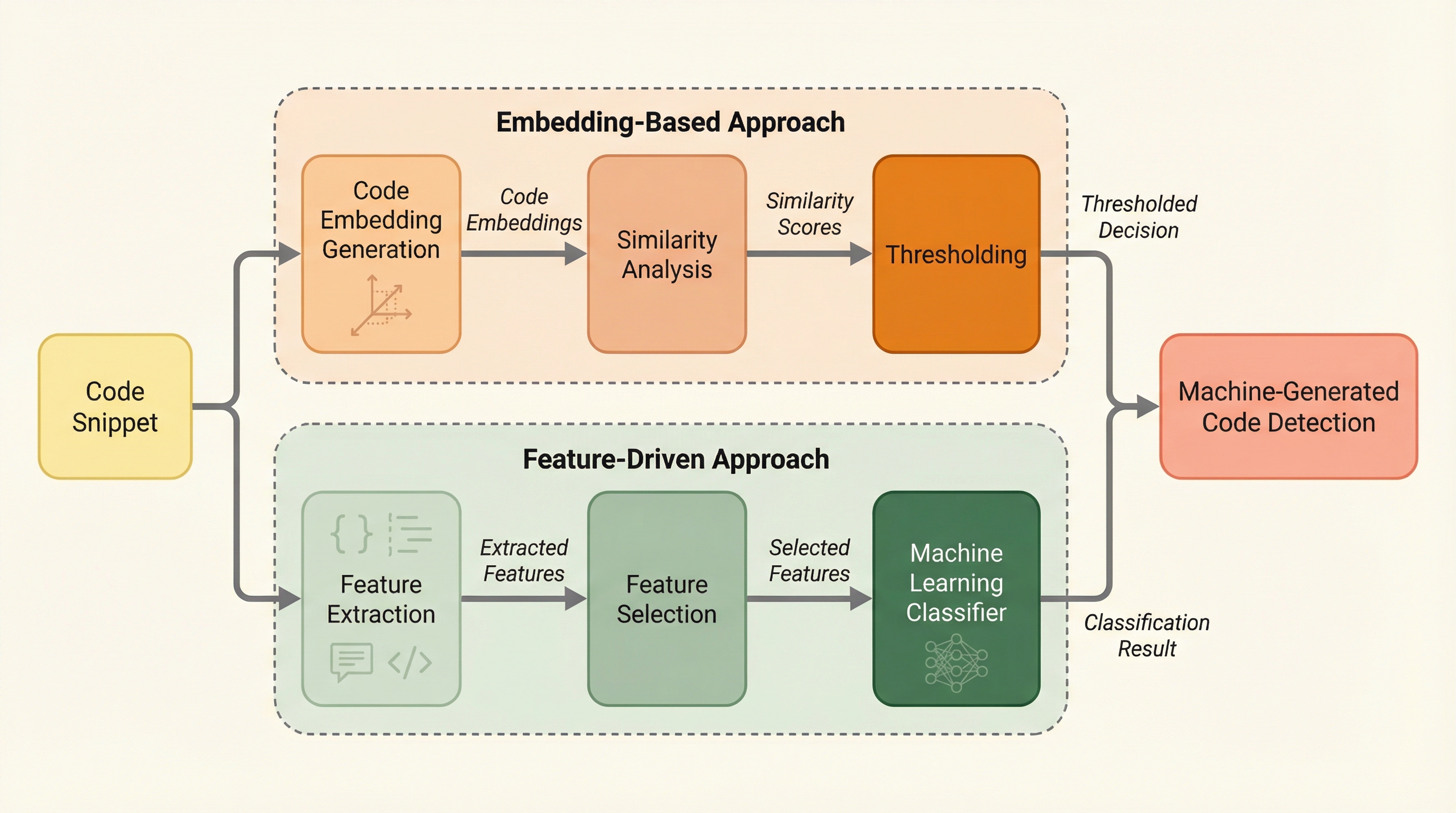
本研究では、人間が書いたコードと機械が生成したコードを区別するための体系的なアプローチとして、2つの相補的なパラダイムを比較するフレームワークを提案しました。1つ目は「特徴量ベースのアプローチ」であり、コードの表面的なスタイルや構造的特性を捉える手作業の指標を抽出します。これはコードスタイロメトリや著作者特定に関する従来の研究に根ざしたもので、高い解釈性と効率性を提供します。2つ目は「埋め込みベースのアプローチ」であり、CodeBERTのような事前学習済みのコード用言語モデルを使用してコードを密なベクトルに変換し、深い文脈的な規則性を利用します。 これらの2つのパイプラインを統一されたプロトコルの下で訓練および評価することで、それぞれの強みと限界を明らかにしました。特に、解釈可能性、汎用性、および計算コストに焦点を当てて比較を行っています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related