CollectiveKV:逐次推薦における協調情報の分離と共有
逐次推薦システムにおけるTransformerのKVキャッシュが引き起こす膨大なストレージ消費と推論遅延を解決するため、ユーザー間の協調情報を活用してキャッシュを劇的に圧縮する新手法「CollectiveKV」が提案されました。
TL;DR(結論)
逐次推薦システムにおけるTransformerのKVキャッシュが引き起こす膨大なストレージ消費と推論遅延を解決するため、ユーザー間の協調情報を活用してキャッシュを劇的に圧縮する新手法「CollectiveKV」が提案されました。 特異値分解(SVD)を用いた詳細な分析により、KV情報の大部分はユーザー間で共有可能な主成分であり、固有の情報はごく一部であるという事実を突き止め、低次元の固有KVとグローバルプールから抽出する高次元の共有KVを分離・統合する仕組みを構築しました。 5種類の主要な推薦モデルと3つの大規模データセットを用いた広範な検証の結果、推薦精度を維持または向上させつつ、KVキャッシュのサイズを元のわずか0.8%まで圧縮することに成功し、外部ストレージからのデータ転送に伴う遅延を大幅に削減しました。
なぜこの問題か
現代のインターネットサービス、特に短編動画プラットフォームや電子商取引、リアルタイム広告の分野では、ユーザーの過去の行動履歴に基づいて次の興味を予測する逐次推薦モデルが不可欠な技術となっています。これらのシステムでは、ユーザーにストレスのない体験を提供するために、極めて厳しい低遅延の制約を満たしながら高い予測精度を維持することが求められます。既存の多くの研究は、Transformerの注意機構(Attention Mechanism)を導入したり改良したりすることで推薦精度の向上に注力してきましたが、注意機構の計算コストは入力される系列の長さに応じて増大するという性質があり、これが実際のシステム配備において大きな障壁となっています。 注意機構において、入力系列を線形変換によってクエリ(Q)、キー(K)、バリュー(V)に投影する処理は、計算コストの大きな割合を占めます。この推論時の計算負荷を軽減するために、近年では大規模言語モデル(LLM)の分野で培われたKVキャッシュ技術が推薦システムにも導入され始めています。これは、過去のキーとバリューを事前に計算して保存しておき、推論時に再利用することで計算を省略する手法です。…
核心:何を提案したのか
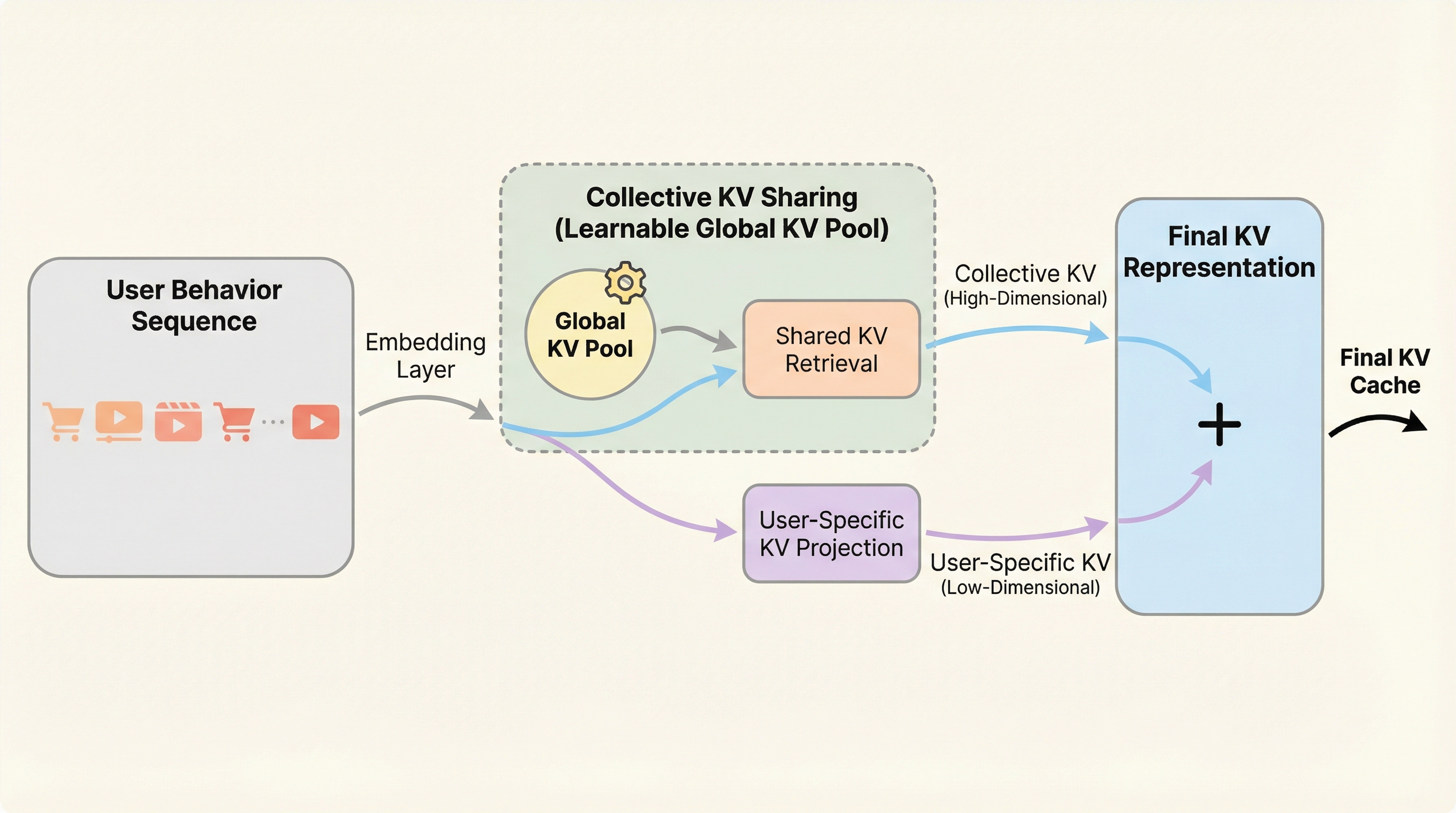
本研究の核心的な提案は、ユーザー間のキーとバリューの類似性を徹底的に分析し、協調信号がKV表現そのものに深く埋め込まれているという発見に基づいた「CollectiveKV」という新しいキャッシュ共有戦略です。著者らはまず、複数の代表的な推薦モデルにおいて、異なるユーザー間でのKおよびVのコサイン類似度を計算しました。その結果、ユーザーが異なっていてもKV表現には高い正の相関が確認され、情報を共有できる可能性が示唆されました。さらに、この現象を定量的に把握するために、特異値分解(SVD)を用いてKV情報を「主成分部分」と「残差部分」に分解する詳細な分析を行いました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related