SECリスク予測のための先見学習
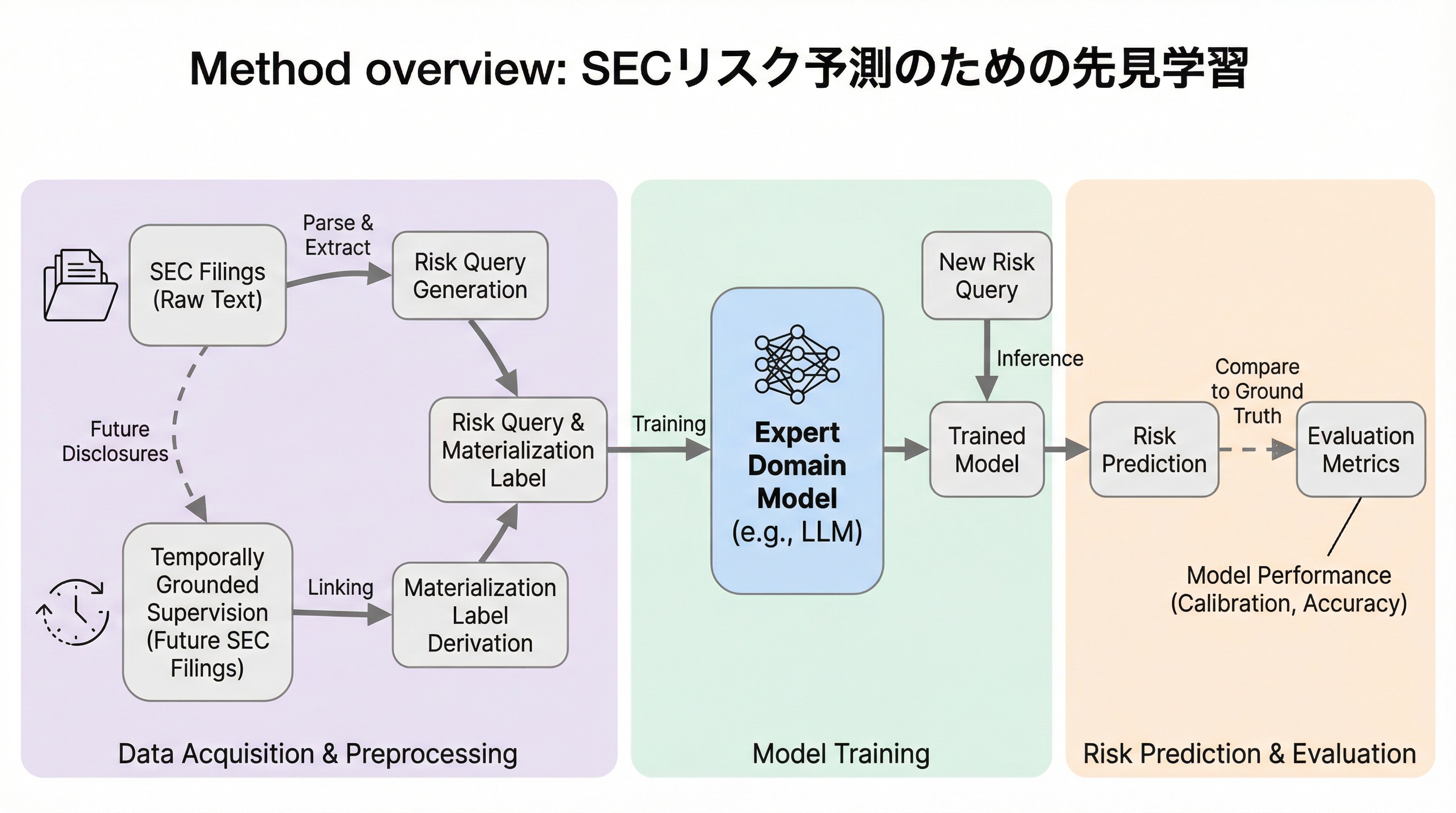
米国証券取引委員会(SEC)への提出書類に含まれる定性的なリスク情報を、将来の開示情報と自動的に紐付けることで、大規模な教師あり学習用データセットを構築する「LightningRod AI」パイプラインを提案した。
TL;DR(結論)
米国証券取引委員会(SEC)への提出書類に含まれる定性的なリスク情報を、将来の開示情報と自動的に紐付けることで、大規模な教師あり学習用データセットを構築する「LightningRod AI」パイプラインを提案した。 このデータを用いて「先見学習(Foresight Learning)」を行うことで、特定の企業リスクが指定期間内に現実化する確率を推定するコンパクトな言語モデルを訓練し、GPT-5などの汎用的な最先端モデルを上回る予測精度と較正性能を達成した。 独自データや手動のアノテーションを一切使わず、公開されている時系列のドメインテキストのみから、単一のGPUで動作可能な高性能な専門家モデルを構築できることを実証し、企業文書から意思決定に役立つ信号を抽出する新たな手法を提示した。
なぜこの問題か
上場企業は、米国証券取引委員会(SEC)に対して定期的に提出する書類の中で、広範なリスクを開示することが義務付けられている。これらの開示情報は、潜在的な悪影響、業務上の課題、規制上の制約、戦略的な不確実性などを記述しているが、そのほとんどは定性的な表現に留まっている。企業は「何が起こり得るか」については説明するものの、それが「どの程度の確率で発生するか」を数値化して示すことは稀である。その結果、投資家やリスク管理の実務者は、体系的あるいは較正された指針がないまま、ナラティブなテキストからリスクの発生確率を推論しなければならないという課題を抱えている。 この問題の根本的な障害は、開示されたリスクと実際に発生した結果をリンクさせる、大規模かつリスクレベルでの教師データが存在しないことにある。リスクの結果が事前にアノテーションされることはほとんどなく、発生し得るリスクの空間は構造化されておらず、異種混合で、企業ごとに固有である。そのため、人間による大規模な手動のラベル付けは事実上不可能である。…
核心:何を提案したのか
本研究では、SECの開示情報からリスクの現実化を予測する問題を解決するために、公開されているSEC提出書類のみを使用して、大規模なリスクレベルの教師データを生成する完全に自動化されたパイプライン「LightningRod AI」を導入した。このパイプラインは、各提出書類の「リスク要因(Risk Factors)」セクションから企業固有かつ時間制限のある「リスククエリ」を生成し、その後の開示情報と照らし合わせて結果を解決することで、人間の介入なしに時間的に裏付けられた教師データを構築する。この仕組みにより、構造化されていない膨大な規制文書を、モデルの訓練に直接利用可能な形式へと変換することに成功した。 このデータセットを用いて、著者らは「先見学習(Foresight Learning)」と呼ばれる枠組みで言語モデルを訓練した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related