RPO-RAG:ナレッジグラフ質問応答のための関係認識型選好最適化による小規模LLMのアライメント
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、知識グラフ(KG)を活用したRAGにおいて、30億パラメータ未満の小規模モデルでも高精度な推論を可能にする新フレームワーク「RPO-RAG」が提案されました。
TL;DR(結論)
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、知識グラフ(KG)を活用したRAGにおいて、30億パラメータ未満の小規模モデルでも高精度な推論を可能にする新フレームワーク「RPO-RAG」が提案されました。 この手法は、質問の意図に合致する推論経路を動的クラスタリングで抽出する意味的サンプリング、中間的な関係レベルでの学習を行う選好最適化、そして回答候補ごとに根拠を整理する回答中心のプロンプト設計という3つの革新的な要素を導入しています。 実験では、WebQSPデータセットでF1スコアを最大8.8%向上させ、CWQデータセットでも80億パラメータ未満のモデルにおける最高精度を達成するなど、リソース制約のある環境での実用的な知識グラフ質問応答の可能性を実証しました。
なぜこの問題か
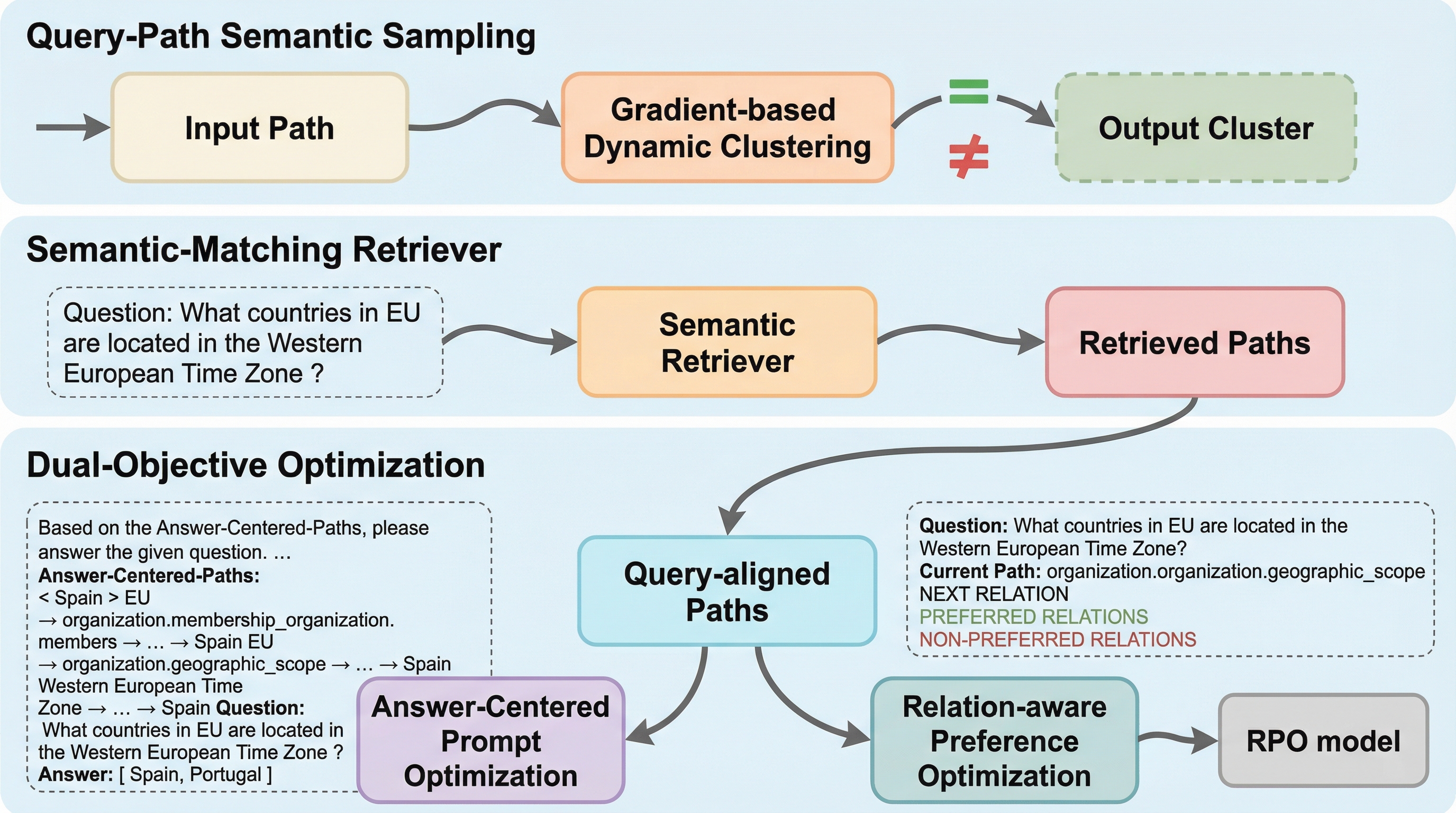
大規模言語モデル(LLM)は優れた推論能力を持つ一方で、事実に基づかない情報を生成するハルシネーションという深刻な課題を抱えています。この問題を解決するために、外部の構造化された知識源を参照する検索拡張生成(RAG)が有効な手段として注目されており、特に事実関係を厳密に保持する知識グラフ(KG)の活用が期待されています。しかし、既存の知識グラフを用いたRAG手法には、大きく分けて三つの深刻な課題が存在しており、これが精度の限界となっていました。 第一に、学習データの構築において、質問の意図を考慮しない経路サンプリングが行われている点です。従来の手法は、最短経路を探索する幅優先探索(BFS)などのヒューリスティックな手法に依存しており、質問の意味とは無関係な経路が学習データに含まれてしまうことが多々あります。これにより、モデルは質問の意図よりもグラフ上の物理的な近接性を優先して学習してしまい、誤った推論パターンを内面化する原因となっています。 第二に、検索された経路と言語モデルの推論目的との間の整合性が弱いという問題があります。…
核心:何を提案したのか
本研究では、小規模な言語モデル(Small LLMs)に特化して設計された、知識グラフに基づく新しいRAGフレームワーク「RPO-RAG(Relation-aware weighted Preference Optimization for RAG)」を提案しています。このフレームワークは、検索から推論に至るパイプライン全体で学習信号を精緻化し、知識グラフの構造とモデルの推論プロセスを高度に整合させることを目的としています。RPO-RAGの核心となる提案は、主に三つの革新的な要素で構成されています。 一つ目は「質問・経路意味的サンプリング(Query-Path Semantic Sampling)」です。これは、従来の機械的な経路抽出に代わり、質問の意図と経路の意味的な一致度を動的に評価して学習データを構築する手法です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related