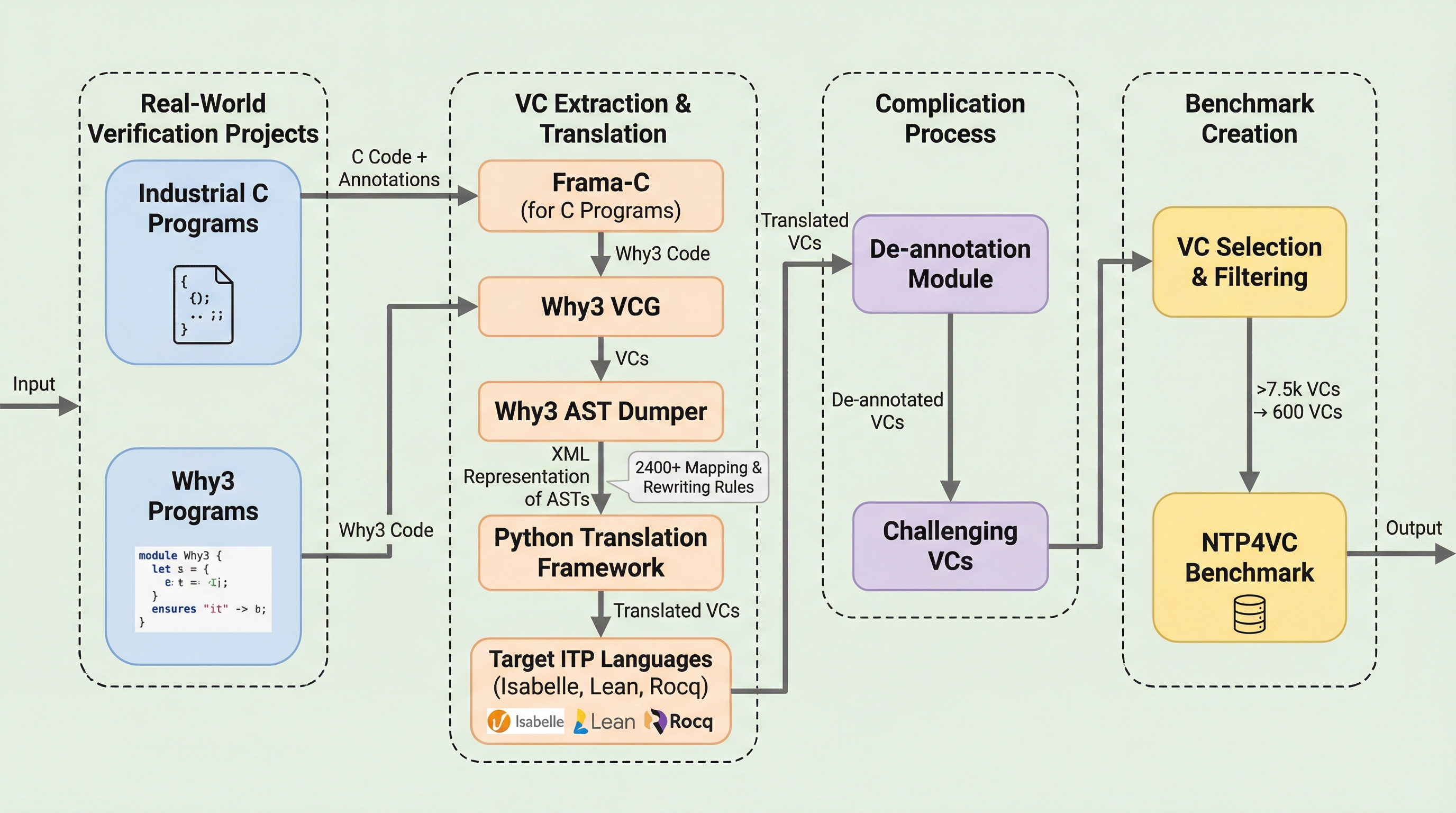
検証条件のためのニューラル定理証明:実世界ベンチマーク
ソフトウェアの信頼性を数学的に保証するプログラム検証において、最大の難所である「検証条件(VC)」の自動証明を解決するため、機械学習を用いたニューラル定理証明(NTP)を実世界の複雑なコードに適用する初のベンチマーク「NTP4VC」を構築した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ソフトウェアの信頼性を数学的に保証するプログラム検証において、最大の難所である「検証条件(VC)」の自動証明を解決するため、機械学習を用いたニューラル定理証明(NTP)を実世界の複雑なコードに適用する初のベンチマーク「NTP4VC」を構築した。
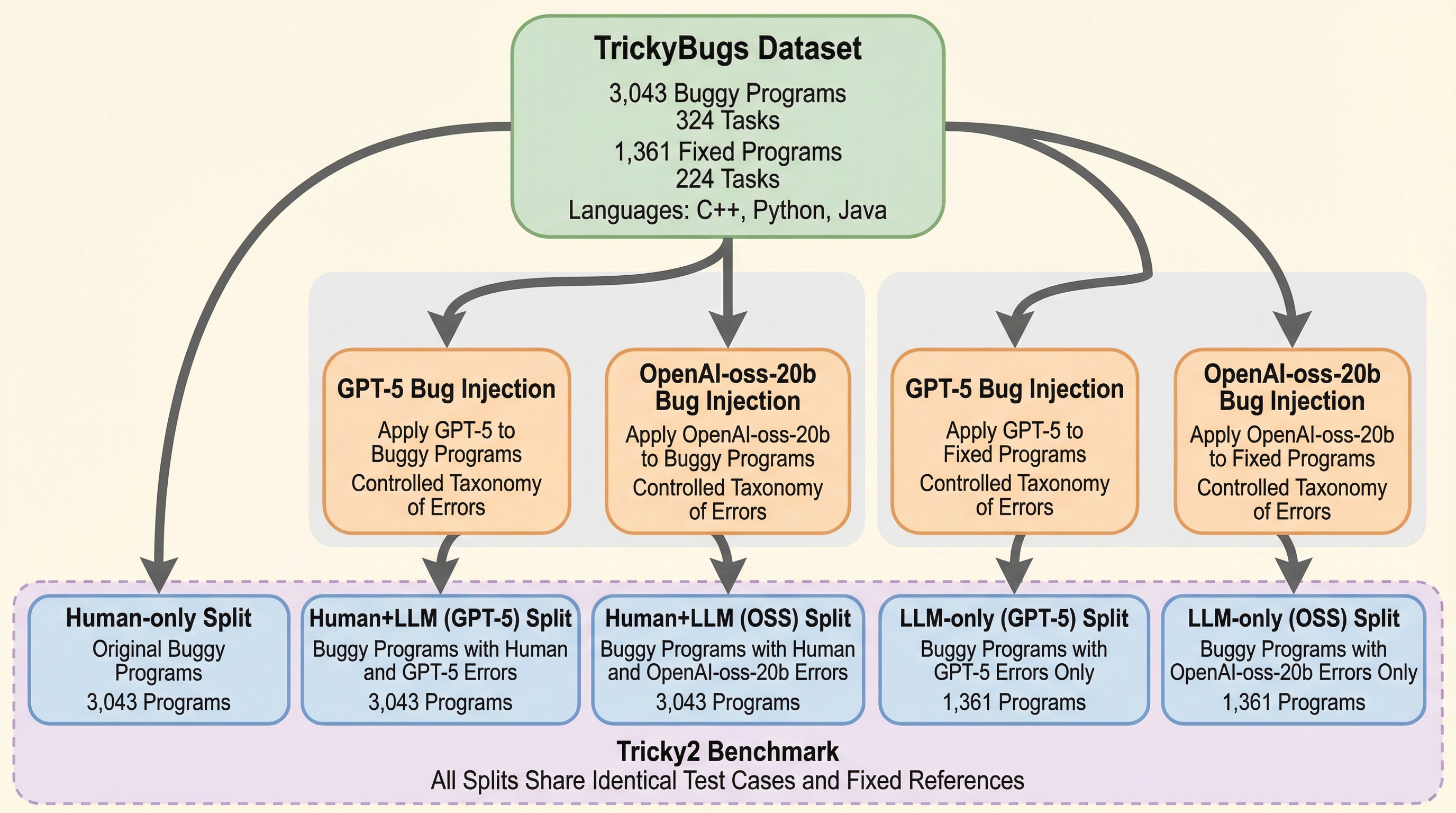
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。
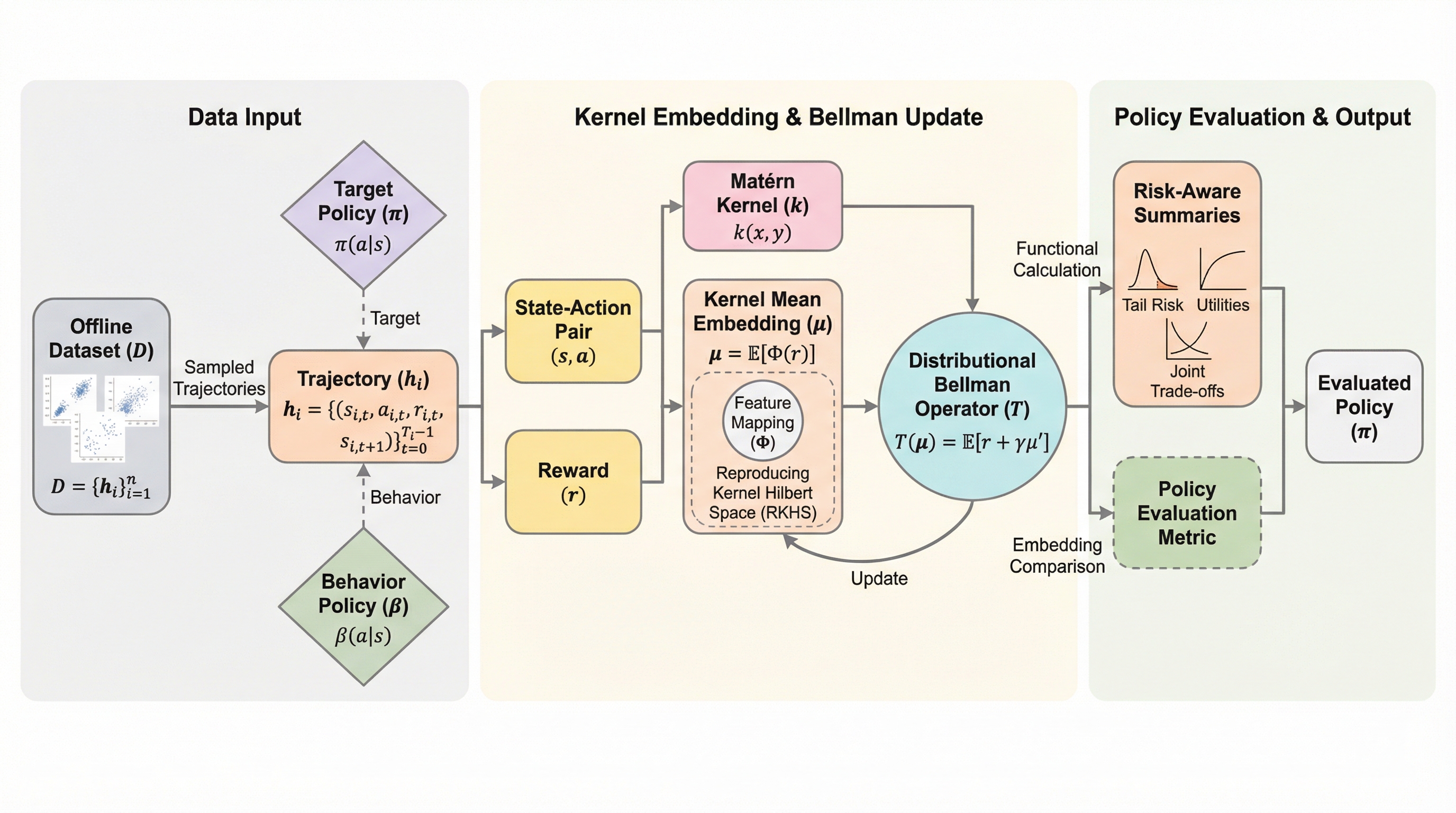
本研究は、多次元の報酬指標と連続的な状態行動空間を扱うオフライン強化学習において、将来的なリターン分布を精度高く推定する新フレームワーク「KE-DRL」を提案している。 従来の分布型強化学習で主流だったワッサースタイン距離は、高次元空間での計算コスト増大と統計的不安定性が課題であったが、再生核ヒルベルト空間への埋め込みとマテルン核を用いた積分確率指標を導入することで、この問題を理論的かつ計算的に解決した。 数学的な解析により分布型ベルマン作用素の縮小性と一様収束性を証明するとともに、エクスペディアのホテル検索データを用いた実証実験を通じて、テールリスクの評価や複数報酬間の複雑なトレードオフを考慮した意思決定における実用的な有効性を明らかにした。
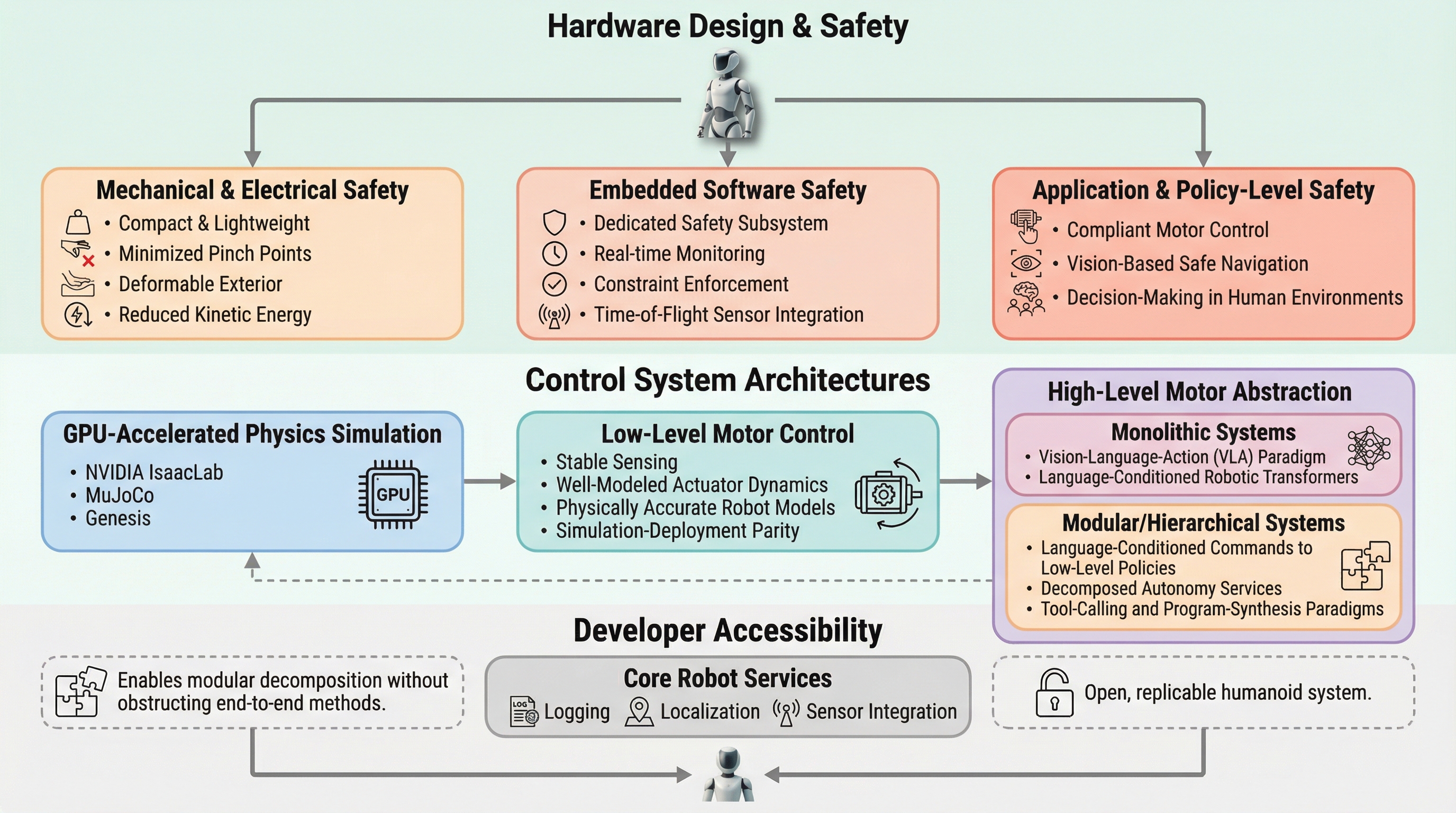
Fauna Sproutは、身長1.07メートル、重量22.7キログラムという極めて軽量かつコンパクトな設計を採用し、人間と日常的な空間を共有することを前提とした開発者向けのヒューマノイドロボットプラットフォームである。
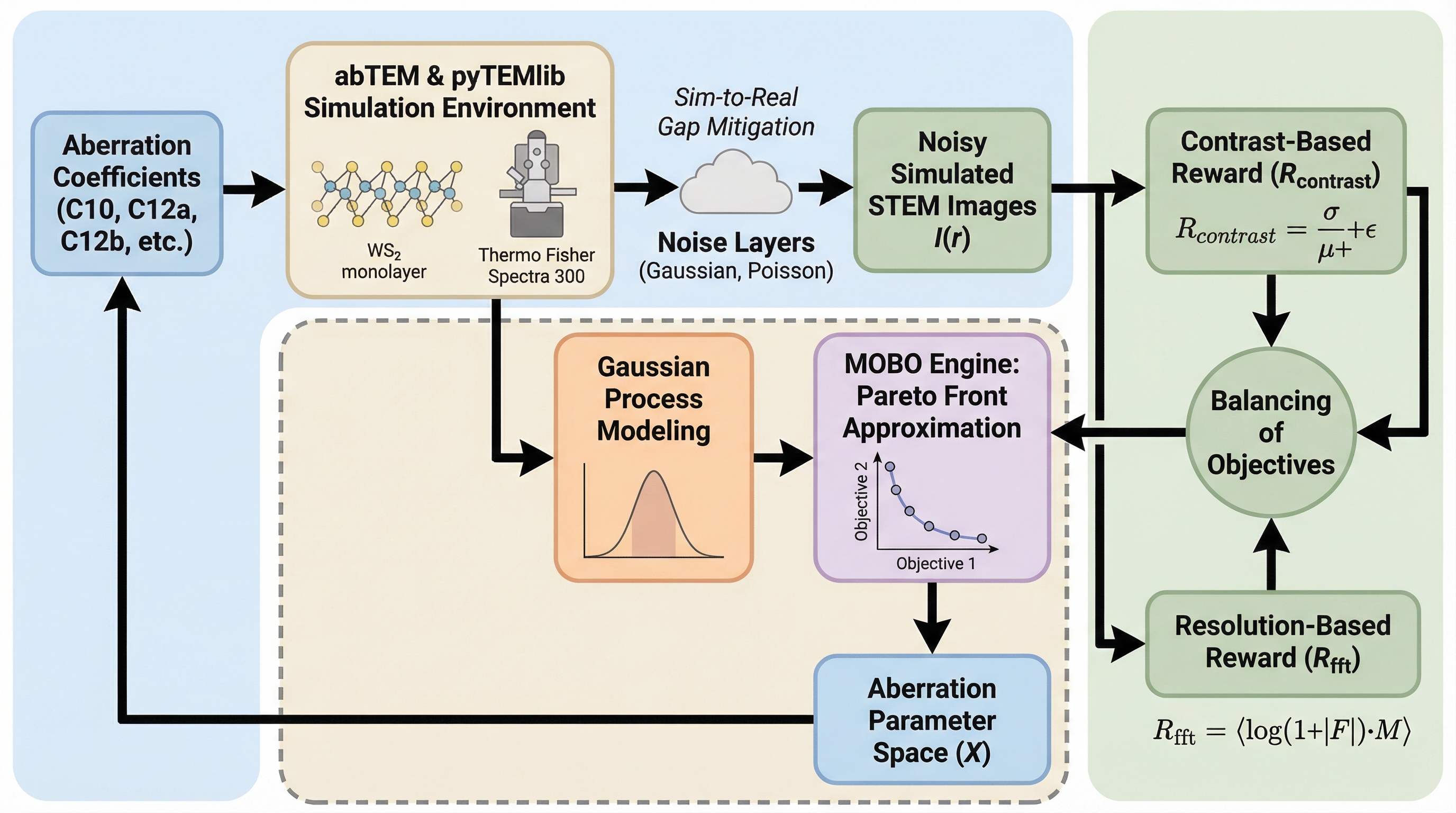
走査透過電子顕微鏡(STEM)の複雑な収差補正を自動化するため、多目的ベイズ最適化(MOBO)を用いた新しいフレームワークが開発されました。この手法は、ガウス過程回帰を活用して収差の状態を確率的にモデル化し、コントラストと解像度という相反する指標のトレードオフをパレートフロントとして提示することで、効率的かつ堅牢な調整を実現します。 従来のグリッド探索や単一指標の最適化とは異なり、このシステムは次に評価すべき最適なレンズ設定を能動的に選択するアクティブラーニングを採用しています。これにより、ノイズやサンプルの損傷に惑わされる「報酬ハッキング」を防ぎ、熟練オペレーターの経験に頼ることなく、短時間でサブオングストロームの解像度を維持することが可能になります。 シミュレーションと実機(Spectra 300)の両方で検証が行われ、わずか25回程度の試行で最適な観察条件に収束することが確認されました。また、最適化の過程をすべて記録するFAIR原則に準拠したデータ管理により、将来のAI学習やデジタルツイン構築に役立つ貴重なデータセットを蓄積できる「自己最適化型」顕微鏡の基盤を構築しました。
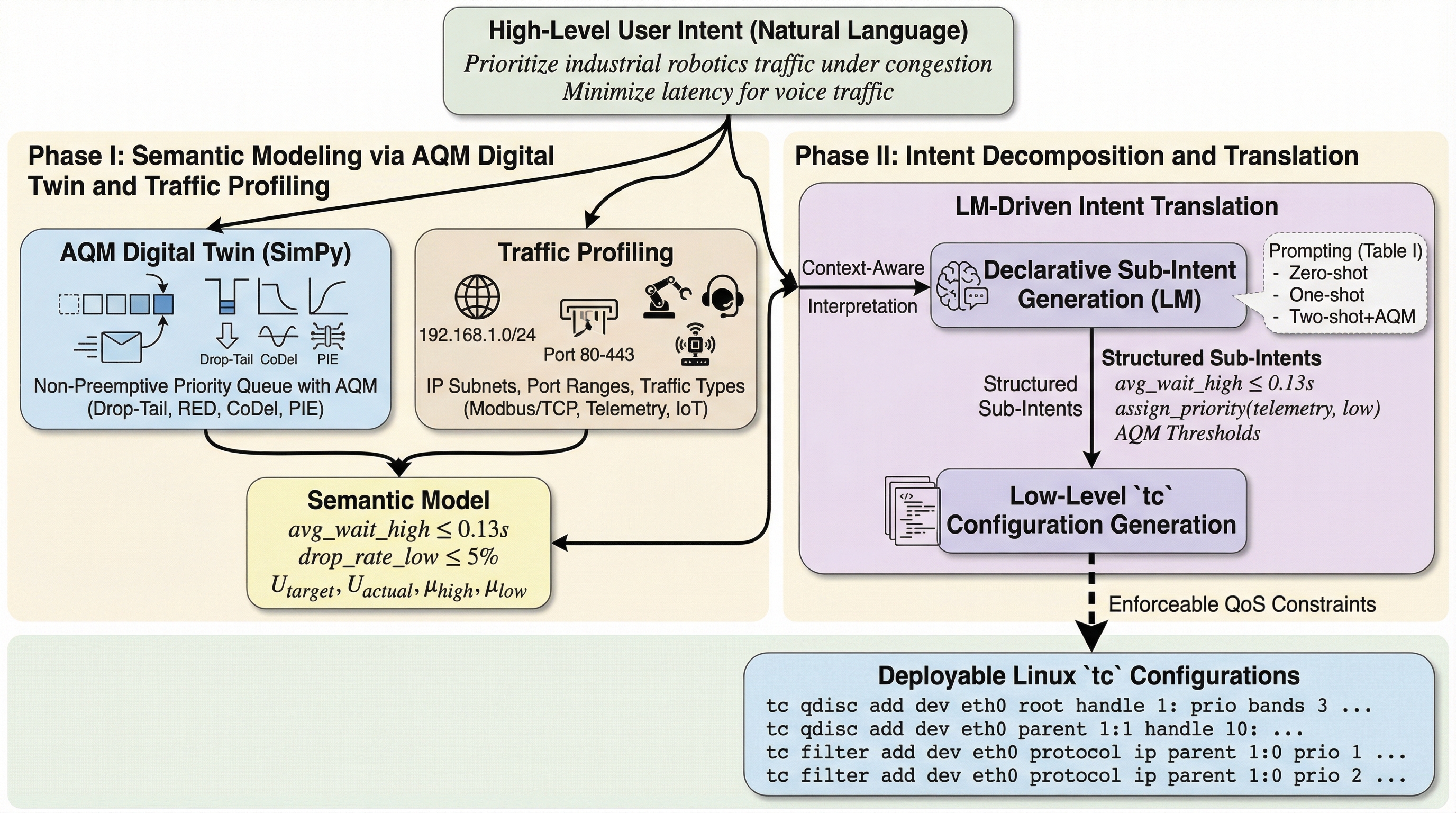
ネットワーク管理者が自然言語で記述した抽象的な「意図」を、Linuxのトラフィック制御(tc)ルールへ自動変換するエンドツーエンドのパイプライン「Intent2QoS」を提案しました。このシステムは、管理者が「ビデオ会議の遅延を最小限にする」といった高レベルな目標を入力するだけで、複雑な低レベルコマンドを自動生成し、専門知識が不足している環境でも高度なQoS設定を可能にします。 キューイング理論に基づくデジタルツインを用いたセマンティックモデルと言語モデルを統合することで、従来の言語モデル単体では困難だったネットワークの物理的挙動の考慮と正確な設定生成を実現しました。これにより、単なる構文の正しさだけでなく、遅延やパケットドロップ率といった物理的な制約を反映した、実際にデプロイ可能な設定セットの出力が可能になります。 100件の意図を用いた検証では、LLaMA3(8B)がセマンティック類似度0.88を達成し、AQM情報を活用したプロンプト手法により設定のばらつきを従来の3分の1に抑制できることが示されました。このフレームワークは、手動設定に伴うヒューマンエラーを排除し、ネットワーク運用のスケーラビリティを大幅に向上させる強力な基盤を提供します。
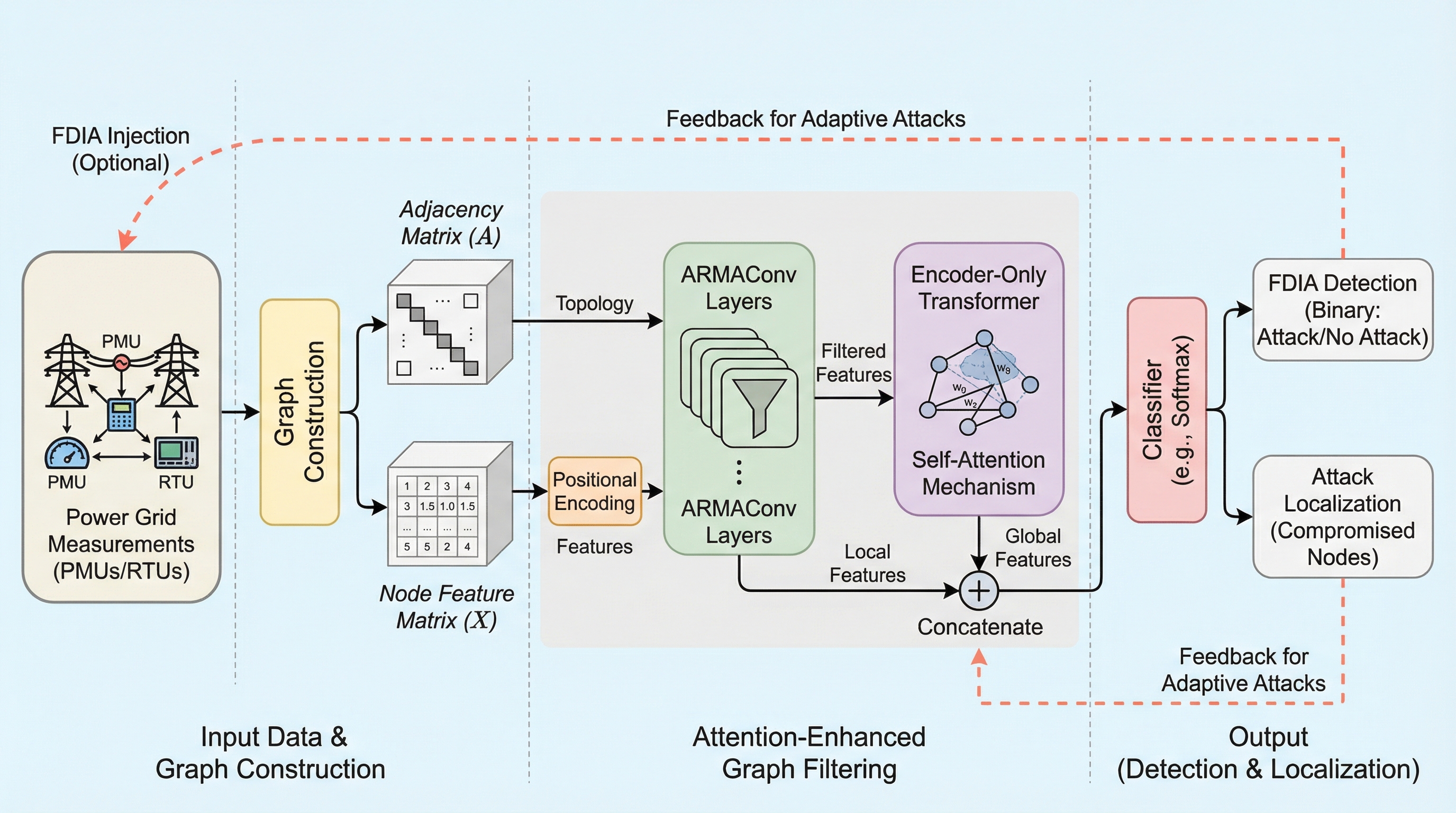
現代の電力網(スマートグリッド)を標的とした巧妙な偽データ注入攻撃(FDIA)に対し、局所的なトポロジーを捉える自己回帰移動平均(ARMA)グラフフィルタと、広域的な依存関係をモデル化するTransformerを統合した新フレームワーク「ACEOT」が提案されました。
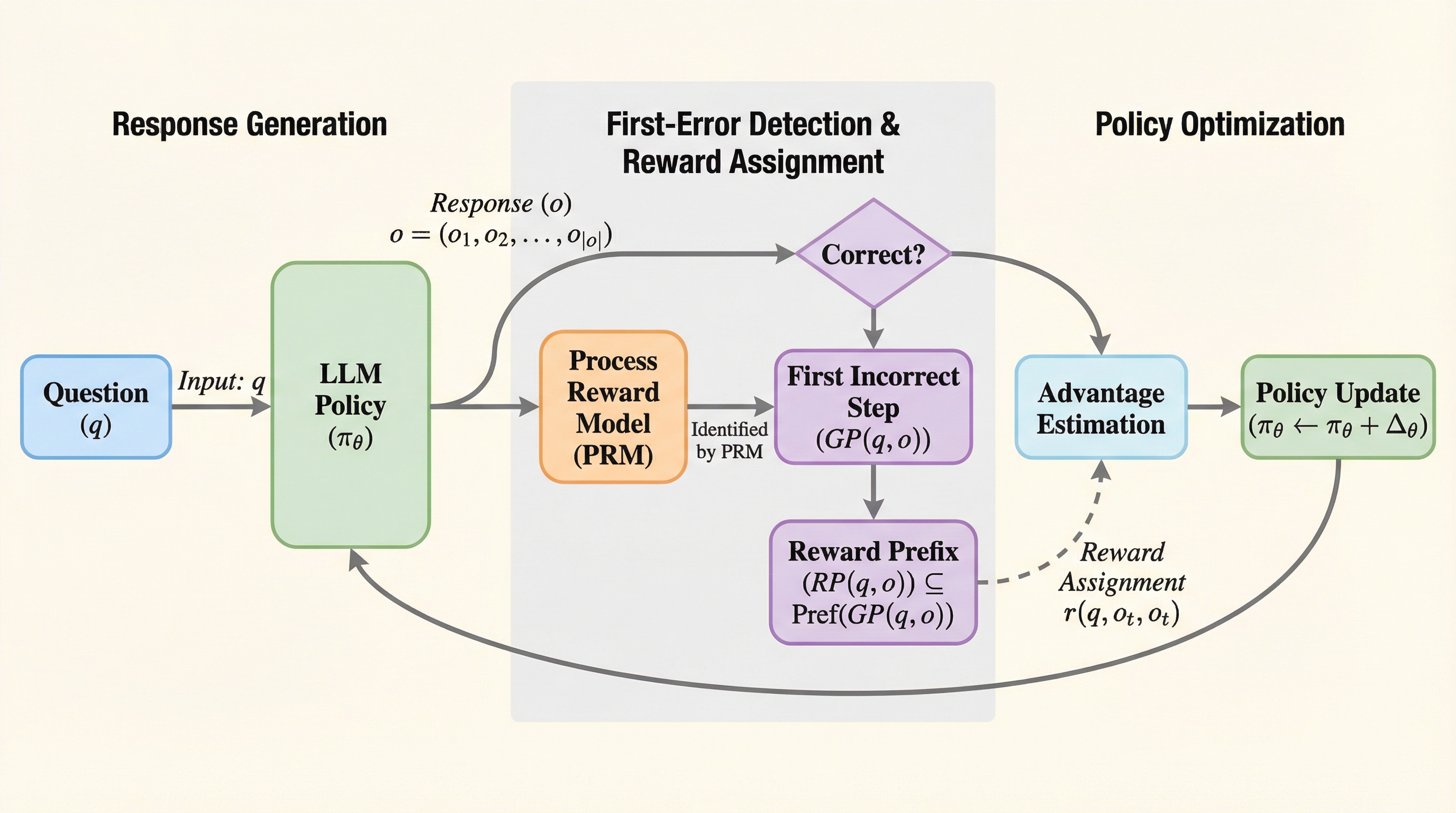
大規模言語モデル(LLM)の推論学習において、最終回答の正誤のみを報酬とする従来の強化学習では、誤答に含まれる「途中までの正しい思考(グッド・プレフィックス)」が不当に否定される課題がありました。
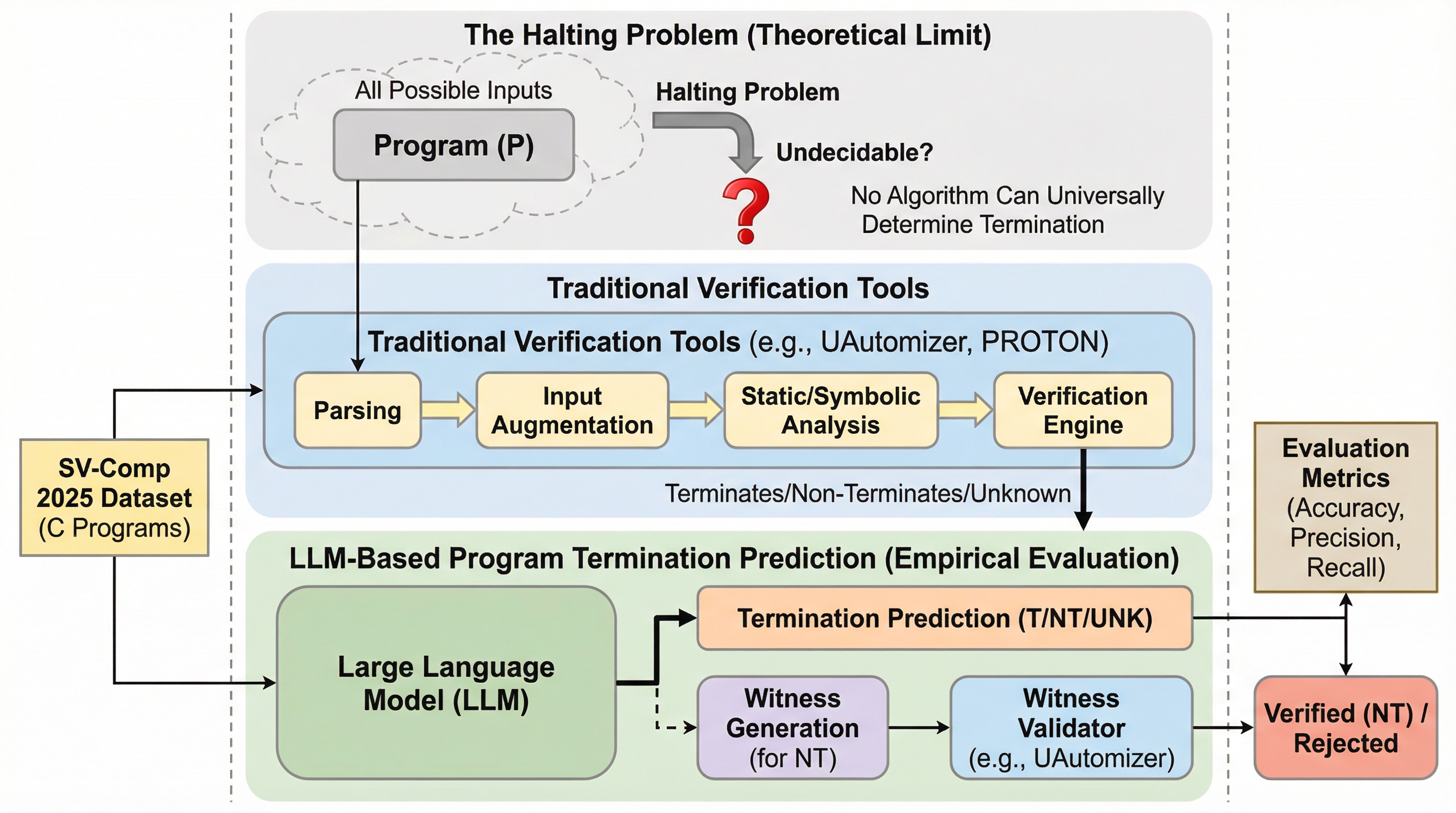
本研究は、計算機科学の根幹的な未解決問題である「停止問題」に対し、GPT-5やClaude Sonnet-4.5といった最新の大規模言語モデル(LLM)が、国際ソフトウェア検証コンペティション(SV-Comp)2025の基準で専門ツールに匹敵する予測能力を持つことを実証した。
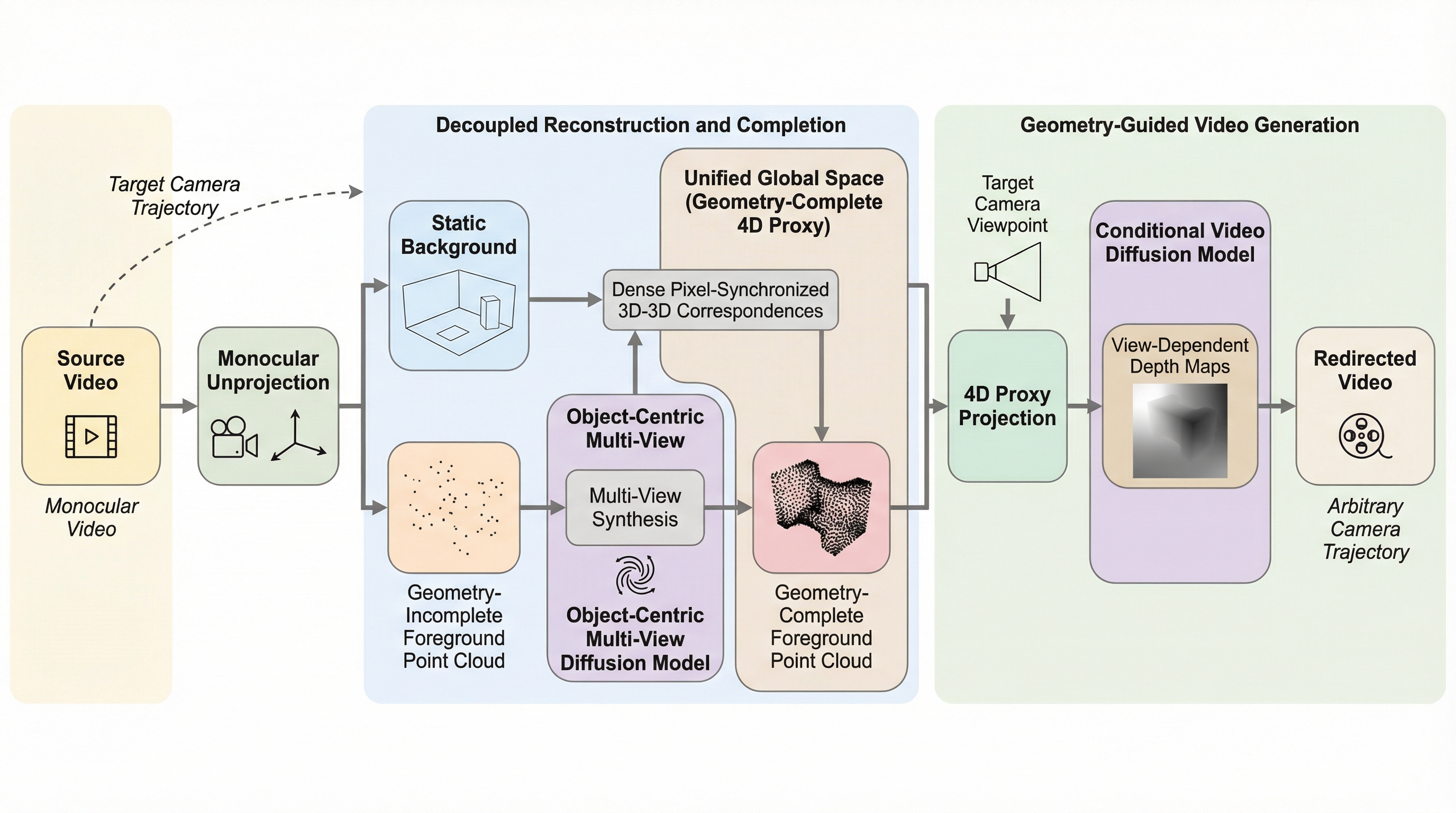
単眼動画から任意のカメラ軌道に沿った映像を生成するカメラリダイレクションにおいて、従来の「暗黙的制御」や「明示的ワーピング」では困難だった広角な視点変更と幾何学的な整合性の両立を、追加学習なしで実現する新フレームワーク「FreeOrbit4D」を提案しました。